















































软件

产品


介绍
今天我们将使用 OpenCV 和 MediaPipe 来检测图像中的468 个面部地标。
OpenCV 是用于计算机视觉、机器学习和图像处理的跨平台开源库,我们可以使用它来开发实时计算机视觉应用程序。它主要用于图像或视频处理以及分析,包括对象检测、面部检测等。
面部地标用于定位和表示面部的重要区域,例如:
面部地标有许多应用,例如:
如果我们在两张不同的脸上估计了面部地标特征点,我们可以将一张脸与另一张脸对齐,然后我们可以将一张脸克隆到另一张脸上。
面部地标可用于通过对齐可变形的面部来生成中间图像。
一旦我们知道了一些面部地标点,那么我们也可以估计头部的姿势。
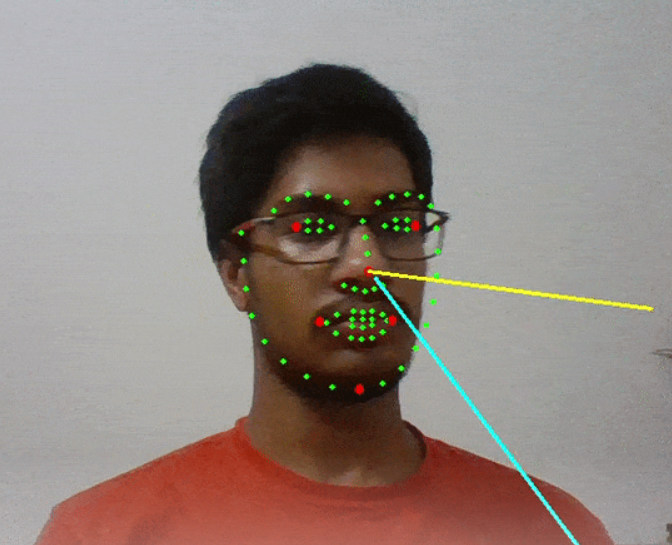
即使在移动设备上,MediaPipe Face Mesh 也可以实时估计 468 个 3D 面部地标。通过应用机器学习 (ML) 来推断 3D 表面几何形状,它只需要单个相机输入,而无需专用的深度传感器。它提供了更好的实时性能。
3D 面部地标模型使用迁移学习,并在具有不同目标的网络上进行训练:该网络预测合成渲染数据上的 3D 地标坐标。由此产生的网络在现实世界的数据上表现得相当好。
3D 地标网络将输入作为裁剪的视频帧,而无需额外的深度输入。该模型输出 3D 点的位置,在输入中合理对齐。
几何管线是一个关键组件,它估计 3D Metric 空间内的几何对象。在每一帧上,分别执行以下步骤:
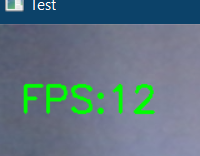
首先,让我们检查我们的网络摄像头 ID 是否工作正常,并在输出屏幕上打印每秒帧数 (fps)。
import cv2import timecap = cv2.VideoCapture(0)pTime = 0while True:success, img = cap.read()imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)cTime = time.time()fps = 1/(cTime-pTime)pTime = cTimecv2.putText(img, f'FPS:{int(fps)}', (20, 70), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)cv2.imshow("Test", img)cv2.waitKey(1) 如果你有网络摄像头,它应该会打开一个窗口,否则你可以在“VideoCapture”功能中指定视频路径而不是零。
在左上角,你可以看到 FPS(变化),如下所示。
现在让我们创建一个新的 python 文件并开始创建我们的面部地标检测模块。
安装所需的模块。
pip install opencv-pythonpip install mediapipe import cv2import mediapipe as mpimport timecap = cv2.VideoCapture(0)pTime = 0NUM_FACE = 2 mpDraw = mp.solutions.drawing_utilsmpFaceMesh = mp.solutions.face_meshfaceMesh = mpFaceMesh.FaceMesh(max_num_faces=NUM_FACE)drawSpec = mpDraw.DrawingSpec(thickness=1, circle_radius=1) 在上面的代码中,我们从网络摄像头获取输入,变量“NUM_FACE”表示有多少面部要从帧中检测和定位面部地标。
要绘制面部点,我们使用 'mpDraw' 变量。我们将使用“mp.solutions.face_mesh”来创建面部网格。
为了控制连接线和点的粗细,我们将使用“drawSpec”。
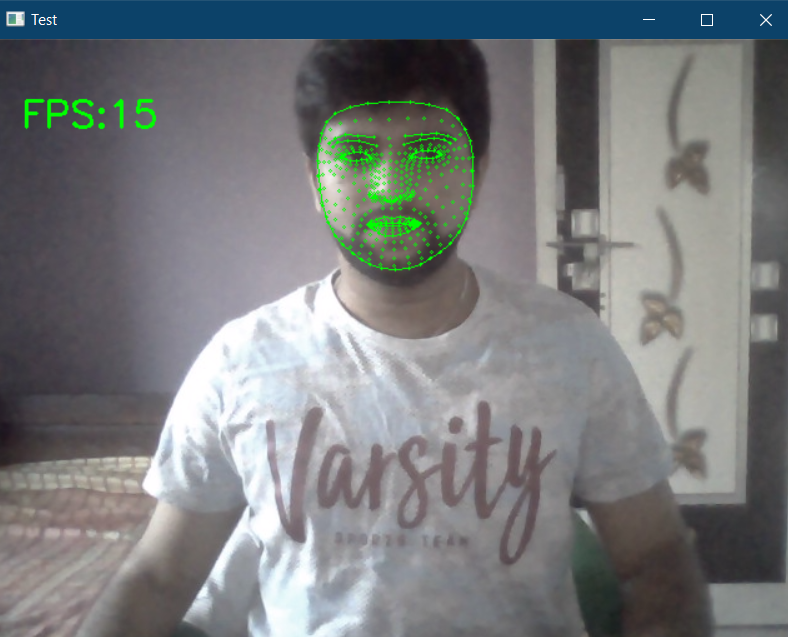
while True: success, img = cap.read() imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) results = faceMesh.process(imgRGB) if results.multi_face_landmarks: for faceLms in results.multi_face_landmarks: mpDraw.draw_landmarks(img, faceLms,mpFaceMesh.FACE_CONNECTIONS, drawSpec, drawSpec) for id,lm in enumerate(faceLms.landmark):print(lm)ih, iw, ic = img.shapex,y = int(lm.x*iw), int(lm.y*ih)# uncomment the below line to see the 468 facial landmark# cv2.putText(img, str(id), (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0, 255, 0), 1)print(id, x,y) cTime = time.time()fps = 1/(cTime-pTime)pTime = cTimecv2.putText(img, f'FPS:{int(fps)}', (20,70), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,255,0), 2)cv2.imshow("Test", img)cv2.waitKey(1) 然后在 while 循环中读取帧并将帧转换为 RGB,将该图像传递给“ *faceMesh.process()”,*然后在面部绘制检测到的地标。
为了看到468 个面部地标,取消对for loop 中的“cv2.putText()”函数的注释。语句 ' print (id, x, y)'将打印出 id 和坐标。然后输出如下。
现在为了创建一个模块,以便我们可以在不同的项目中使用它,首先我们需要创建一个包含函数的类。
import cv2import mediapipe as mpimport time NUM_FACE = 2 class FaceLandMarks(): def __init__(self, staticMode=False,maxFace=NUM_FACE, minDetectionCon=0.5, minTrackCon=0.5): self.staticMode = staticMode self.maxFace = maxFace self.minDetectionCon = minDetectionCon self.minTrackCon = minTrackCon self.mpDraw = mp.solutions.drawing_utils self.mpFaceMesh = mp.solutions.face_mesh self.faceMesh = self.mpFaceMesh.FaceMesh(self.staticMode, self.maxFace, self.minDetectionCon, self.minTrackCon) self.drawSpec = self.mpDraw.DrawingSpec(thickness=1, circle_radius=1) def findFaceLandmark(self, img, draw=True): self.imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) self.results = self.faceMesh.process(self.imgRGB) faces = [] if self.results.multi_face_landmarks: for faceLms in self.results.multi_face_landmarks: if draw: self.mpDraw.draw_landmarks(img, faceLms, self.mpFaceMesh.FACE_CONNECTIONS, self.drawSpec, self.drawSpec) face = [] for id, lm in enumerate(faceLms.landmark): # print(lm) ih, iw, ic = img.shape x, y = int(lm.x * iw), int(lm.y * ih) #cv2.putText(img, str(id), (x,y), cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0,255,0), 1) #print(id, x, y) face.append([x,y]) faces.append(face) return img, facesdef main(): cap = cv2.VideoCapture(0) pTime = 0 detector = FaceLandMarks() while True: success, img = cap.read() img, faces = detector.findFaceLandmark(img) if len(faces)!=0: print(len(faces)) cTime = time.time() fps = 1 / (cTime - pTime) pTime = cTime cv2.putText(img, f'FPS:{int(fps)}', (20, 70), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2) cv2.imshow("Test", img) cv2.waitKey(1)if __name__ == "__main__": main()在上面的代码中,函数名称是*“findFaceLandmarks”,它检测面部地标并执行与上述相同的功能。类“FaceLandMarks()”* 取静态模式中,面部的最大数量和最小检测置信度和最小的跟踪置信度。然后创建 main 函数来运行代码。
完整代码可在此处获得:https://github.com/BakingBrains/Face_LandMark_Detection
https://www.youtube.com/watch?v=V9bzew8A1tc&t=2125s
https://learnopencv.com/facial-landmark-detection/
https://google.github.io/mediapipe/solutions/face_mesh.html
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















