















































软件

产品


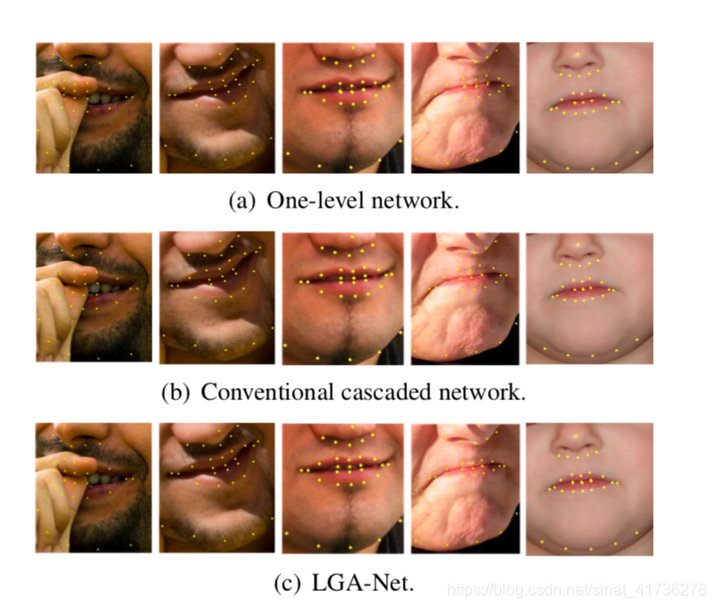
提出了一个局部-全局整合网络,包含两个卷积神经网络来整合局部-全局的信息来提升预测精确性和鲁棒性。
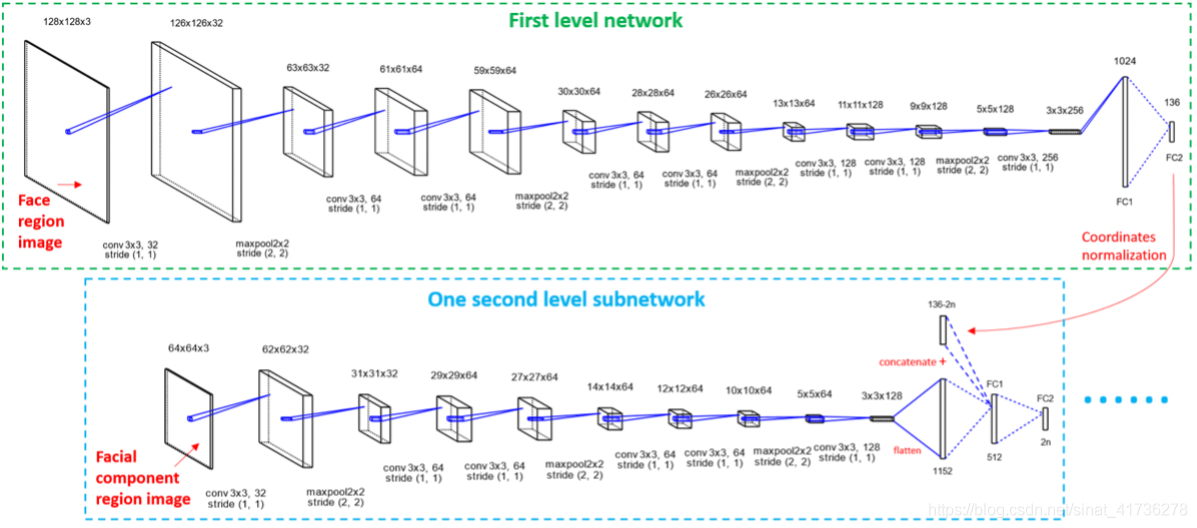
First level 输入为通过独立的人脸检测出的原始人脸图像。因为first level network是用全脸进行训练的,包括了全剧信息,能够给出粗糙但是鲁棒性强的全部人脸关键点预测。然而他的精确度十分有限,特别是一些变形的人脸要素,如嘴巴和眼睛。为了得到既高精确度又尺寸小的模型,从粗到细的策略被提出,引入了级联神经网络结构。在每一个层级中,网络都局部的重新定义一个包含从先前网络中得到的相关的原始人脸图片的关键点的子集。
为了得到更鲁棒的在无限制环境下的关键点预测,局部-全局整合网络的第二层自网络将原始图片和来自first level的全局脸部信息共同作为输入。在这项工作中,关键点坐标从上一级网络中获得选择作为高层次的全局特征。这种做法的好处是,在训练过程中,全局特征可以直接从训练数据中获得,而不是从以前的网络中获得,这样每个子网络都可以独立地训练和级联。
First level network输入一个3通道128x128的人脸图片,输出一个136个元素的array代表着全脸的68个关键点的坐标。面部要素的bbox由这些坐标来确定。原始的人脸图片根据bbox剪裁,resize到64x64,然后传到第二层子网络中作为局部信息来进行关键点的微调。应当注意,对于裁剪的分量区域图像,设置了最大纵横比2:1。如果在训练和测试中都超过了最大比率,则区域图像的较短边将被迫延伸以保持合理的纵横比以获得更好的性能。
全局信息输入到第二级网络中,first level的关键点坐标根据每个相关的面部要素的bbox来标准化然后传入二层子网络。为了避免first level的关键点预测过于干扰二层子网络的关键点预测,相关关键点坐标将去除输入first level坐标来通过二层子网络预测。为了有效的整合局部-全局特征,在二级网络中,最后一层卷积得到的高阶特征被展平为一维array,然后和来自first level的关键点坐标来形成新的包含全局和局部特征的特征array。这个array之后被传入全脸阶层来重新提炼关键点预测。最后,来自二层网络的关键点坐标和来自一级网络人脸轮廓的坐标融合来形成最终的人脸关键点预测。总共4个二级子网络包括左眉,左眼,鼻子和嘴。为了使整个网络更小,通过左眉和左眼子网对右眉和右眼进行处理,通过水平翻转区域图像和对应的关键点坐标从一级网络得到。
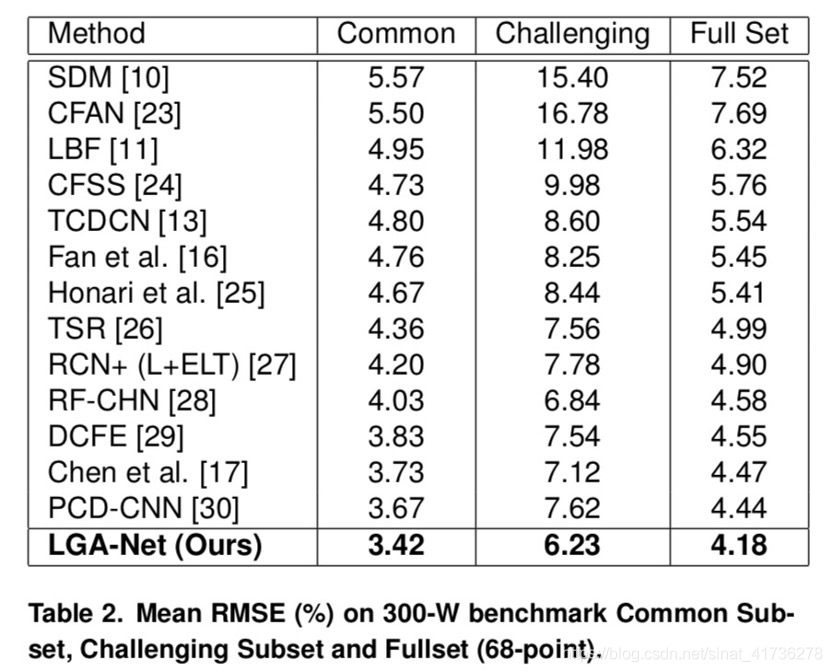
数据集:300-W AFW HELEN IBUG LFPW MENPO 共10831个68landmarks的图片作为训练集和测试集
数据扩大:bounding box random expansion [21], random rotation, horizontal flipping, and random Gaussian blurring are applied
整个训练集分为normal和strong
训练细节:normalized
consider a bounding box whose top left cor- ner coordinate is (xbbox,ybbox), with w and height h. (x,y) is one landmark coordinate before normalization. Then the normalized landmark coordinate (xnorm,ynorm) based on the bounding box is
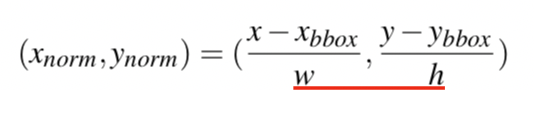
Euclidean loss
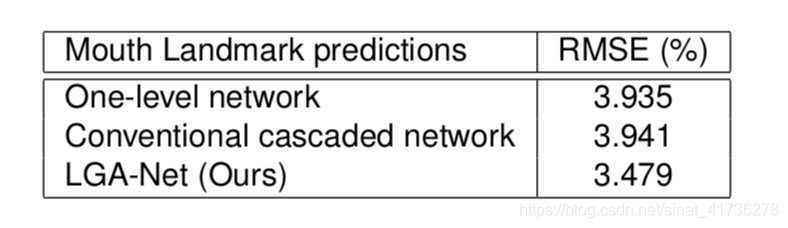
Point-to-point RMS error between predicted landmark and ground truth annotations,
RMSE:均方根误差亦称标准误差,其定义为 ,i=1,2,3,…n。在有限测量次数中,均方根误差常用下式表示:√[∑di^2/n]=Re,式中:n为测量次数;di为一组测量值与真值的偏差。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















