















































软件

产品


通过将声音分解为与持续时间无关的情绪空间和与持续时间相关的内容空间 可以都得到动态的2d landmark
然后作者提出了 Target-Adaptive Face Synthesis technique(目标自适应人脸合成技术)可以缩小推断的landmark和目标视频的自然头部姿态之间的gap
为了实现交叉重建训练,应该提供相同内容, 相同长度的不同情绪的成对句子, 但是现实场景中是不可能的,为此使用Dynamic Time Warping (DTW) 帮助使用对齐的不等长 语料库 形成伪训练对。
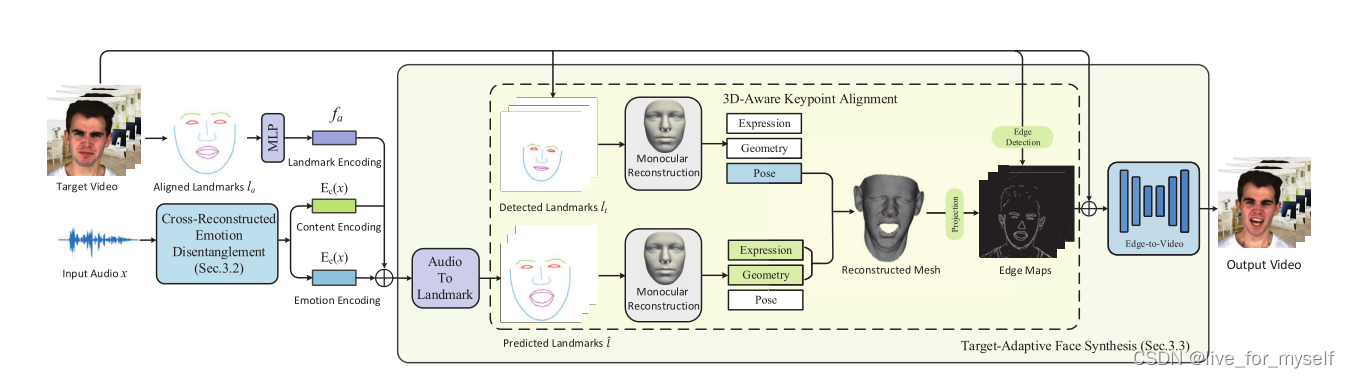
首先从音频信号中提取分离的内容和情感 信息 。是通过DTW算法生成的伪训练对,然后用交叉重构损失来学习解耦。
算法的第二部分是目标自适应人脸合成, 它将从 音频 中推断的landmark适配到目标视频中。具体是设计了一种3D-Aware Keypoint Alignment算法, 在三维空间中旋转landmarks,从而使landmarks能够适应各种姿势和运动。最后通过edge合成图片
可以把最后的edge变成cycle形式的
从音频信号中提取两个独立的潜在音频空间:i)与持续时间无关的空间情感编码;ii)与持续时间相关的空间,它对音频的语音内容进行编码。
但是这样的训练对比较难得,所以需要首先构建伪训练对。然后再进行交叉重构。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















