前言
MTCNN算法是经典的人脸检测算法,本篇讲述内容包含两个部分:MTCNN论文的核心要点以及github上运用Pytorch框架复现的源码。
本系列所有代码是用python3编写,可在平台Anaconda中运行实现,在使用代码时,默认你已经安装相关的python库。本篇对源码的解析完全是基于我的个人理解,如有问题,欢迎指出。
一、MTCNN论文阅读
1.1 论文信息
- 论文名称:《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》《同时用于人脸检测和对齐的多任务级联卷积网络》
- 发表时间:2016年4月11日
- 作者:Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Senior Member, IEEE, and Yu Qiao, Senior Member, IEEE
- 下载地址:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
1.2 论文 摘要 翻译
由于不同姿势,照明和遮挡,无约束环境中的面部检测和对齐具有挑战性。最近的研究表明, 深度学习 方法可以在这两项任务上取得极好的性能。 在本文中,我们提出了一个深度级联的多任务框架,它利用了检测和对齐之间的内在联系来提高它们的性能。特别是,我们的框架利用级联架构,通过三个阶段精心设计的深度卷积网络,从粗到细的方式检测人脸和人脸关键点。此外,在学习过程中我们提出了一种新的在线难例样本挖掘策略,可自动提高实践中的性能而不需要人工的样本选择。我们的方法在人脸检测具有挑战性的FDDB和WIDER FACE基准以及面部对齐的AFLW基准测试中实现了超过最先进技术的卓越精度,同时保持了实时性能。
1.3 论文核心(三级级联网络)
如下图1.1为MTCNN算法网络的三级级联框架:
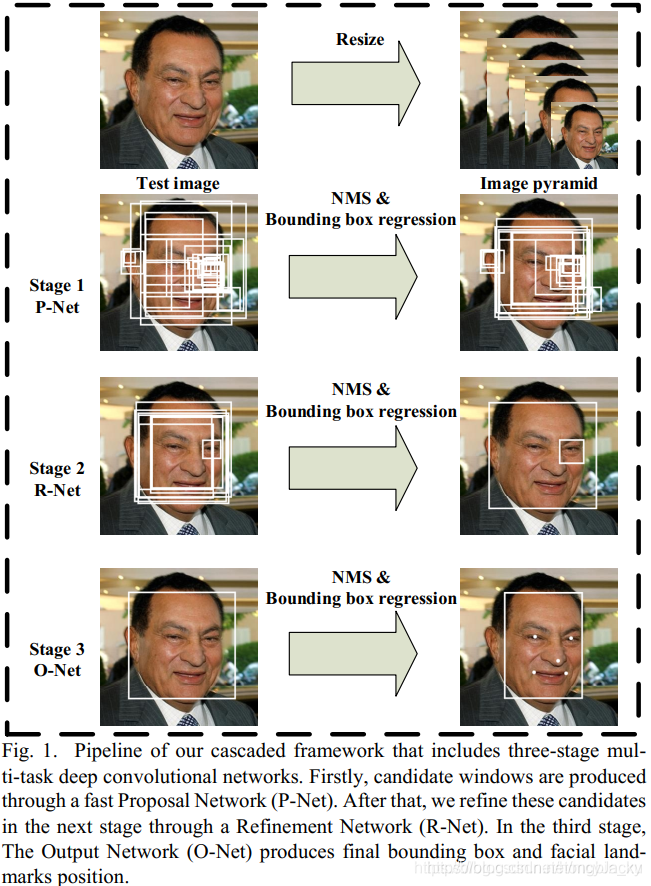
图1.1 MTCNN级联网络框架
结构解析:
- 先将原始图片缩放到不同尺度,形成一个图像金字塔(Image Pyramid);
- 阶段一:P-Net(Proposal Net)区域候选网络,先使用卷积网络获取人脸框和边界框回归向量(Bounding Box Regression),再用边界框回归向量进行人脸框校准,之后用非极大抑制(NMS)去除重合度高的候选框
- 阶段二:R-Net(Refine Net),将P-Net得到的回归框输入到R-Net中,再对回归框进行校准,并使用NMS去重
- 阶段三:O-Net(Output Net),将R-Net输出的回归框输入到O-Net中,再对回归框进行校准,并使用NMS去重,同时会输出5个人脸的特征点。(从最终输出结果可以看出在此网络中不仅输出了人脸检测框,而且还输出了人脸特征关键点)
1.4 论文核心(级联子网络结构)
- P-Net网络结构
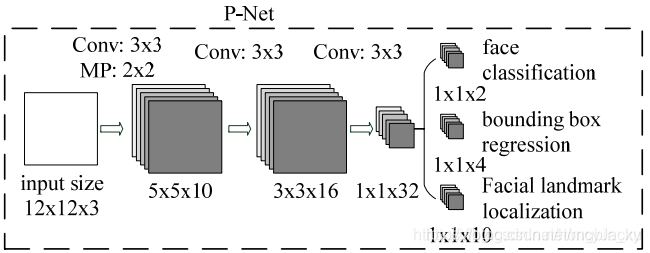
图2.1 P-Net网络
- 将原图压缩到不同尺度的图像金字塔输入到P-Net中(可以更大程度确保不同大小的人脸都被检测到)。
- 取图片12x12x3的区域作为输入,通过卷积和池化输出:人脸分类(2个输出)、边界框回归(回归框的左上和右下坐标,4个输出)、人脸关键点定位(P-Net中不输出)。
- R-Net网络结构
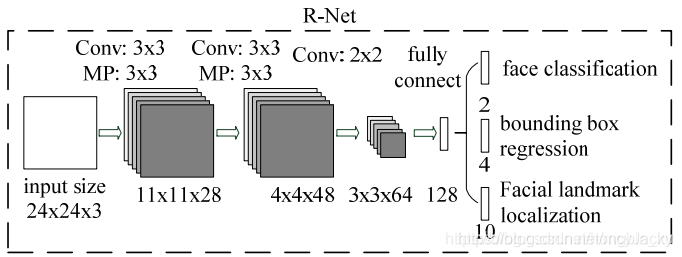
图2.2 R-Net网络
- P-Net网络简单速度快,但准确率较低,所有用R-Net来进一步做检测。把P-Net人脸检测窗口resize为24x24x3大小,再传入R-Net中,可消除很多误判。
- R-Net的输出和P-Net的输出结果一样:人脸分类(2个输出)、边界框回归(回归框的左上和右下坐标,4个输出)、人脸关键点定位(R-Net中不输出)。
- O-Net网络结构
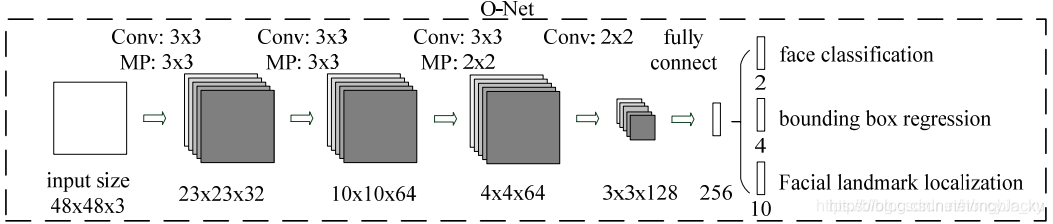
图2.3 O-Net网络
- 把R-Net得到窗口resize为48x48x3大小,再传入O-Net进行检测。
- O-Net的输出为:人脸分类(2个输出)、边界框回归(回归框的左上和右下坐标,4个输出)、人脸关键点定位(10个输出)。
1.5 损失函数
- 人脸分类损失,预测输入框是否有人脸,使用交叉熵损失(cross-entropy loss): L i d e t = − ( y i d e t log ( p i ) + ( 1 − y i d e t ) ( 1 − log ( p i ) ) ) L_i^{det} = -(y_i^{det}\log(p_i) + (1-y_i^{det})(1-\log(p_i))) Lidet=−(yidetlog(pi)+(1−yidet)(1−log(pi))) 其中, p i p_i pi是预测值, y i d e t ∈ { 0 , 1 } y_i^{det} \in \{0,1\} yidet∈{ 0,1}是实际值。
- 边界框回归损失,计算边界框和Ground Truth之间的偏差: L i b o x = ∥ y ^ i b o x − y i b o x ∥ 2 2 L_i^{box}={\Vert \hat y_i^{box} - y_i^{box}\Vert}_2^2 Libox=∥y^ibox−yibox∥22 其中, y ^ i b o x \hat y_i^{box} y^ibox是预测框, y i b o x y_i^{box} yibox是Ground Truth框。
- 人脸关键点回归损失,预测了人脸5个关键点坐标,使用L2损失: L i l a n d m a r k = ∥ y ^ i l a n d m a r k − y i l a n d m a r k ∥ 2 2 L_i^{landmark}={\Vert \hat y_i^{landmark} - y_i^{landmark}\Vert}_2^2 Lilandmark=∥y^ilandmark−yilandmark∥22 其中, y ^ i l a n d m a r k \hat y_i^{landmark} y^ilandmark是预测关键点, y i l a n d m a r k y_i^{landmark} yilandmark是实际关键点。
- Mult-source training,由于使用多个数据集进行训练,对于不同的训练数据,三类误差要有不同的权重: min ∑ i = 1 N ∑ j ∈ { d e t , b o x , l a n d m a r k } α j β i j L i j \min \sum_{i=1}^N \sum_{j \in \{det, box, landmark\}} \alpha_j\beta_i^jL_i^j mini=1∑Nj∈{ det,box,landmark}∑αjβijLij 其中, α j \alpha_j
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删



















































 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















