















































软件

产品


Insight Face(RetinaFace)在2019年提出的最新人脸检测模型,原模型使用了deformable convolution和dense regression loss, 在 WiderFace 数据集上达到SOTA。截止2019年8月,原始模型尚未全部开源,目前开源的简化版是基于传统物体检测网络RetinaNet的改进版,添加了SSH网络的检测模块,提升检测精度,作者提供了三种基础网络,基于ResNet的ResNet50和ResNet152版本能提供更好的精度,以及基于mobilenet(0.25)的轻量版本mnet,检测速度更快。
Multi-task loss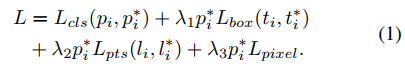
对于每一个anchor i:
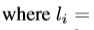
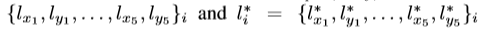
代表预测的五个面部关键点坐标和positive anchor 的五个真实坐标点,把关键点也给基于anchor centre 进行归一化
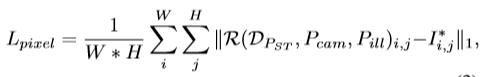
RetinaFace的mnet本质是基于RetinaNet的结构,采用了特征金字塔的技术,实现了多尺度信息的融合,对检测小物体有重要的作用,RetinaNet的结构如下: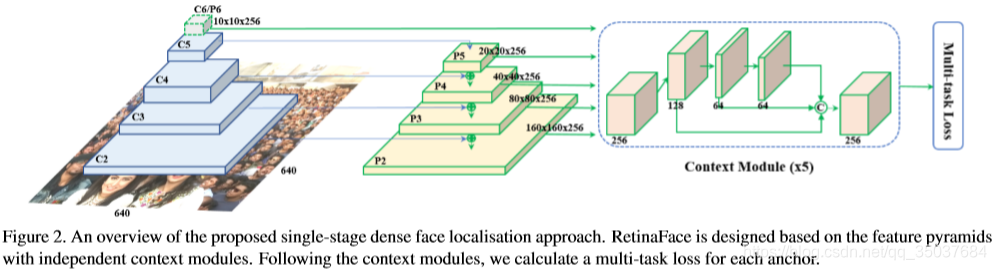
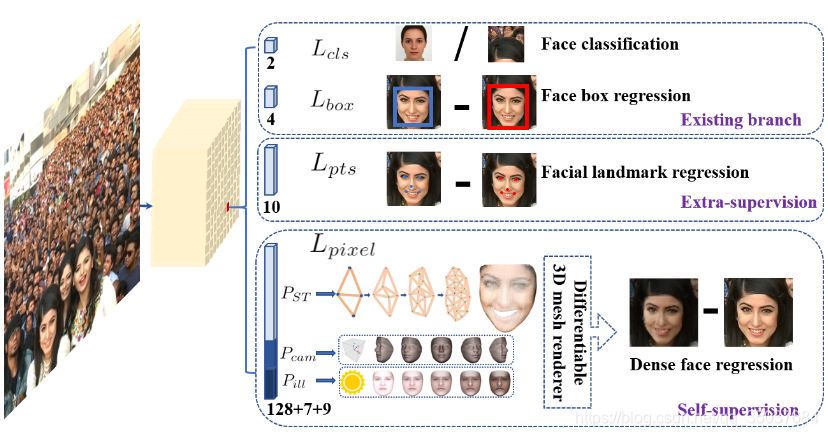
上图是原版RetinaFace论文中的检测分支图,注意在开源简化版的不包含self-supervision部分,但是有5个关键点的extra-supervision部分。
(1)生成框住人脸的anchor
简化版的RetinaFace在特征金字塔上有3个检测分支,分别对应3个stride: 32, 16和8。stride32可以用来检测较大的区域人脸,同理stride16和stride8可用于中等和较小人脸区域的检测。默认设置为每个stride对应一个ratio,每个ratio对应两个scale,即每个stride对应的feature map的每个位置会在原图上生成两个anchor box,anchor box默认设置代码如下:
_ratio = (1.,)
self._feat_stride_fpn = [32, 16, 8]
self.anchor_cfg = {
'32': {'SCALES': (32,16), 'BASE_SIZE': 16, 'RATIOS': _ratio, 'ALLOWED_BORDER': 9999},
'16': {'SCALES': (8,4), 'BASE_SIZE': 16, 'RATIOS': _ratio, 'ALLOWED_BORDER': 9999},
'8': {'SCALES': (2,1), 'BASE_SIZE': 16, 'RATIOS': _ratio, 'ALLOWED_BORDER': 9999},
}
在每个stride上对应的feature map的每个像素点对应的原图位置上生成两个anchor, 假设采取训练的默认输入大小640 × 640, stride32 对应的feature map大小为20 × 20 (640 / 32),那么在stride32对应的feature map上一共可以得到 20 × 20 × 2 = 800个anchor, 同理在stride16对应的feature map可以生成 大小128 × 128和64 × 64的anchor,共有40 × 40 × 2 = 3200个, 在stride8对应的feature map可以生成大小为32 × 32 和 16 × 16的feature map,共有80 × 80 × 2 = 12800个,3个scale总共可以生成800 + 3200 + 12800 = 16800个anchor, 在每个feature map上生成anchor时可以调用rcnn/cython/anchors_cython(),代码如下:
def anchors_cython(int height, int width, int stride, np.ndarray[DTYPE_t, ndim=2] base_anchors):
"""
Parameters
----------
height: height of plane
width: width of plane
stride: stride ot the original image
anchors_base: (A, 4) a base set of anchors
Returns
-------
all_anchors: (height, width, A, 4) ndarray of anchors spreading over the plane
"""
cdef unsigned int A = base_anchors.shape[0]
cdef np.ndarray[DTYPE_t, ndim=4] all_anchors = np.zeros((height, width, A, 4), dtype=DTYPE)
cdef unsigned int iw, ih
cdef unsigned int k
cdef unsigned int sh
cdef unsigned int sw
for iw in range(width):
sw = iw * stride
for ih in range(height):
sh = ih * stride
for k in range(A):
all_anchors[ih, iw, k, 0] = base_anchors[k, 0] + sw
all_anchors[ih, iw, k, 1] = base_anchors[k, 1] + sh
all_anchors[ih, iw, k, 2] = base_anchors[k, 2] + sw
all_anchors[ih, iw, k, 3] = base_anchors[k, 3] + sh
return all_anchors
(2)图像金字塔
图像金字塔即将图像resize的各种不同的大小输入到检测网络得到各个尺度的检测结果,是检测中常用的提取多尺度的方式,使模型能有更有效的检测到不同大小尺度的人脸。简化版的retinaface在测试时也使用这个方式来提升精度。
由于检测时对输入图片的大小没有要求,在检测时定义了target_size和max_size两个参数。target_size定义了模型输入图片短边的长度,max_size定义的输入数据长边的最大范围。
在单尺度测试时(即不采用图像金字塔),优先考虑target_size,当图像短边达到target_size而长边没有超出max_size时,即将图像缩放为短边target_size的大小,否则缩放为长边是max_size的大小。而在多尺度测试时,这个target_size被定义为各个不同的大小,如在源代码测试widerface数据集时,target_size被定义为[500, 800, 1100, 1400, 1700],由此也得到了不同的图像缩放系数im_scale,对缩放各个不同尺度的图片做检测,得到关于这幅图片的所有检测框,具体实现即上文提到的retinaface.py中的detect()方法里的scale参数(即scale = im_scale)。
在测试中运用图像金字塔的做法也被广泛应用在各种人脸检测的模型中,有时也被成为multi-scale testing,在S3FD和SRN以及最新的SOTA模型AFD_HP等模型中都有应用。
(3)训练
训练过程中所有图片的大小均为640×640×3。开源版的github采用了crop的方式实现了图片尺寸的一致性,主要的实现代码在io/image.py中的get_crop_image1(roidb)中:
def get_crop_image1(roidb):
"""
preprocess image and return processed roidb
:param roidb: a list of roidb
:return: list of img as in mxnet format
roidb add new item['im_info']
0 --- x (width, second dim of im)
|
y (height, first dim of im)
"""
#roidb and each roi_rec can not be changed as it will be reused in next epoch
num_images = len(roidb)
processed_ims = []
processed_roidb = []
for i in range(num_images):
roi_rec = roidb[i]
if 'stream' in roi_rec:
im = cv2.imdecode(roi_rec['stream'], cv2.IMREAD_COLOR)
else:
assert os.path.exists(roi_rec['image']), '{} does not exist'.format(roi_rec['image'])
im = cv2.imread(roi_rec['image'])
if roidb[i]['flipped']:
im = im[:, ::-1, :]
if 'boxes_mask' in roi_rec:
#im = im.astype(np.float32)
boxes_mask = roi_rec['boxes_mask'].copy()
boxes_mask = boxes_mask.astype(np.int)
for j in range(boxes_mask.shape[0]):
m = boxes_mask[j]
im[m[1]:m[3],m[0]:m[2],:] = 127
#print('find mask', m, file=sys.stderr)
SIZE = config.SCALES[0][0] ###640
PRE_SCALES = [0.3, 0.45, 0.6, 0.8, 1.0]
#PRE_SCALES = [0.3, 0.45, 0.6, 0.8, 1.0, 0.8, 1.0, 0.8, 1.0]
_scale = random.choice(PRE_SCALES)
#_scale = np.random.uniform(PRE_SCALES[0], PRE_SCALES[-1])
size = int(np.min(im.shape[0:2])*_scale)
#size = int(np.round(_scale*np.min(im.shape[0:2])))
im_scale = float(SIZE)/size
im = cv2.resize(im, None, None, fx=im_scale, fy=im_scale, interpolation=cv2.INTER_LINEAR)
训练数据集的准备引入了数据增强的策略,对于图片做不同尺度的缩放,图片的基准尺寸用的是网络的输入大小640,首先将输入图片较短的维度缩放成基础尺寸640, 在此基础上根据PRE_SCALES = [0.3, 0.45, 0.6, 0.8, 1.0]再进行缩放,每张图片都会随机匹配一个PRE_SCALE,将图像短边缩放成640 / PRE_SCALE, 即图像的短边尺寸的取值包括。在调整了原图的尺寸后,要根据图片的尺寸调整标注位置框和面部关键点的尺寸,如下程序段所示:
assert im.shape[0]>=SIZE and im.shape[1]>=SIZE
#print('image size', origin_shape, _scale, SIZE, size, im_scale)
new_rec = roi_rec.copy()
new_rec['boxes'] = roi_rec['boxes'].copy() * im_scale
if config.FACE_LANDMARK:
new_rec['landmarks'] = roi_rec['landmarks'].copy()
new_rec['landmarks'][:,:,0:2] *= im_scale
调整人脸框bbox和特征点landmark的尺寸非常容易,只要将原来的坐标位置×缩放尺度im_scale,就能得到尺度调整后的bbox和landmark坐标。得到了调整完的图片和bbox,landmark坐标后,下一步就可以对图片进行裁剪以适应网络的输入大小640 × 640,如下程序段所示:
retry = 0
LIMIT = 25
size = SIZE
while retry<LIMIT:
up, left = (np.random.randint(0, im.shape[0]-size+1), np.random.randint(0, im.shape[1]-size+1))
boxes_new = new_rec['boxes'].copy()
im_new = im[up:(up+size), left:(left+size), :]
#print('crop', up, left, size, im_scale)
boxes_new[:,0] -= left
boxes_new[:,2] -= left
boxes_new[:,1] -= up
boxes_new[:,3] -= up
if config.FACE_LANDMARK:
landmarks_new = new_rec['landmarks'].copy()
landmarks_new[:,:,0] -= left
landmarks_new[:,:,1] -= up
valid_landmarks = []
valid = []
valid_boxes = []
for i in range(boxes_new.shape[0]):
box = boxes_new[i]
#center = np.array(([box[0], box[1]]+[box[2], box[3]]))/2
centerx = (box[0]+box[2])/2
centery = (box[1]+box[3])/2
box_size = max(box[2]-box[0], box[3]-box[1])
if centerx<0 or centery<0 or centerx>=im_new.shape[1] or centery>=im_new.shape[0]:
continue
if box_size<config.TRAIN.MIN_BOX_SIZE:
continue
#filter by landmarks? TODO
valid.append(i)
valid_boxes.append(box)
if config.FACE_LANDMARK:
valid_landmarks.append(landmarks_new[i])
if len(valid)>0 or retry==LIMIT-1:
im = im_new
new_rec['boxes'] = np.array(valid_boxes)
new_rec['gt_classes'] = new_rec['gt_classes'][valid]
if config.FACE_LANDMARK:
new_rec['landmarks'] = np.array(valid_landmarks)
if config.HEAD_BOX:
face_box = new_rec['boxes']
head_box = expand_bboxes(face_box, image_width=im.shape[1], image_height=im.shape[0])
new_rec['boxes_head'] = np.array(head_box)
break
retry+=1
if config.COLOR_MODE>0 and config.COLOR_JITTERING>0.0:
im = im.astype(np.float32)
im = color_aug(im, config.COLOR_JITTERING)
im_tensor = transform(im, config.PIXEL_MEANS, config.PIXEL_STDS, config.PIXEL_SCALE)
processed_ims.append(im_tensor)
#print('boxes', new_rec['boxes'], file=sys.stderr)
im_info = [im_tensor.shape[2], im_tensor.shape[3], im_scale]
new_rec['im_info'] = np.array(im_info, dtype=np.float32)
processed_roidb.append(new_rec)
return processed_ims, processed_roidb
这里设置LIMIT=25对每张图片做25次随机裁剪,每次裁剪的大小即为640 × 640 × 3,同时同样需要对bbox和landmark的标注进行调整,即减去随机裁剪图片的在原图中的左上角位置left和up,得到标注坐标在crop中的位置。验证新的bbox是否有效,即中心点位置是否在裁剪后的图中,大小是否小于预定义的人脸最小大小,筛选符合要求的人脸。之后再对裁剪后的图片做常规的数据增强和特征归一化等操作,得到了用于网络输入的图片processed_ims,以及尺度和位置调整过的bbox和landmark坐标processed_roidb。
# label: 1 is positive, 0 is negative, -1 is dont care
labels = np.empty((len(inds_inside),), dtype=np.float32)
labels.fill(-1)
if gt_boxes.size > 0:
# overlap between the anchors and the gt boxes
# overlaps (ex, gt)
overlaps = bbox_overlaps(anchors.astype(np.float), gt_boxes.astype(np.float))
argmax_overlaps = overlaps.argmax(axis=1)
max_overlaps = overlaps[np.arange(len(inds_inside)), argmax_overlaps]
gt_argmax_overlaps = overlaps.argmax(axis=0)
gt_max_overlaps = overlaps[gt_argmax_overlaps, np.arange(overlaps.shape[1])]
gt_argmax_overlaps = np.where(overlaps == gt_max_overlaps)[0]
if not config.TRAIN.RPN_CLOBBER_POSITIVES:
# assign bg labels first so that positive labels can clobber them
labels[max_overlaps < config.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
# fg label: for each gt, anchor with highest overlap
if config.TRAIN.RPN_FORCE_POSITIVE:
labels[gt_argmax_overlaps] = 1
# fg label: above threshold IoU
labels[max_overlaps >= config.TRAIN.RPN_POSITIVE_OVERLAP] = 1
if config.TRAIN.RPN_CLOBBER_POSITIVES:
# assign bg labels last so that negative labels can clobber positives
labels[max_overlaps < config.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
else:
labels[:] = 0
fg_inds = np.where(labels == 1)[0]
label中用1表示正例,0表示负例,-1表示丢弃,即IOU在0.3到0.5之间。
labels的长度是与inds_inside(之后解释)相同的向量,是网络中所有anchor box的总数,原版实现中为20 × 20 × 2 + 40 × 40 × 2 + 80 × 80 × 2 = 16800个, 在确定label的时候需要计算每个anchor和每个标注检测框gt_bbox的IOU,对于每个anchor,取IOU最大的gt_bbox作为相匹配的标注框,这个IOU>0.5即为正例,<0.3即为负例。
这里的inds_inside是生成所有的anchor后保留不超出边界的anchor的index,之前anchor设置中提到的ALLOWED_BORDER参数决定了这个边界,ALLOWED_BORDER默认为9999,即anchor长宽坐标在-9999到9999之间的所有anchor都将被保留,即可认为所有的anchor都将被保留。
这样的做法实质将所有的anchor在feature map输出按照一定的顺序(reshape,concat的默认顺序)排列成了一个一维向量,训练的loss可以直接在这个向量上求得,所以要注意在训练时网络结果出来后也要按照相同的顺序排列,以免发生输入数据和label的不匹配。在实现了分类label的生成之后,还需要实现label对应的bbox和landmark坐标的label,代码如下所示:
bbox_targets = np.zeros((len(inds_inside), bbox_pred_len), dtype=np.float32)
if gt_boxes.size > 0:
bbox_targets[:,:] = bbox_transform(anchors, gt_boxes[argmax_overlaps, :])
bbox_weights = np.zeros((len(inds_inside), bbox_pred_len), dtype=np.float32)
#bbox_weights[labels == 1, :] = np.array(config.TRAIN.RPN_BBOX_WEIGHTS)
bbox_weights[labels == 1, 0:4] = 1.0
if bbox_pred_len>4:
bbox_weights[labels == 1, 4:bbox_pred_len] = 0.1
if landmark:
landmark_targets = np.zeros((len(inds_inside), landmark_pred_len), dtype=np.float32)
#landmark_weights = np.zeros((len(inds_inside), 10), dtype=np.float32)
landmark_weights = np.zeros((len(inds_inside), landmark_pred_len), dtype=np.float32)
#landmark_weights[labels == 1, :] = np.array(config.TRAIN.RPN_LANDMARK_WEIGHTS)
if landmark_pred_len==10:
landmark_weights[labels == 1, :] = 1.0
elif landmark_pred_len==15:
v = [1.0, 1.0, 0.1] * 5
assert len(v)==15
landmark_weights[labels == 1, :] = np.array(v)
else:
assert False
if gt_landmarks.size > 0:
a_landmarks = gt_landmarks[argmax_overlaps,:,:]
landmark_targets[:] = landmark_transform(anchors, a_landmarks)
invalid = np.where(a_landmarks[:,0,2]<0.0)[0]
#assert len(invalid)==0
#landmark_weights[invalid, :] = np.array(config.TRAIN.RPN_INVALID_LANDMARK_WEIGHTS)
landmark_weights[invalid, :] = 0.0
在确定了每个anchor对应的标注框argmax_overlaps之后,anchor和标注框的坐标就可以一一对应起来,这个时候需要得到训练过程中计算loss使用的bbox_target。这个bbox_target的计算的是中心点坐标的相对距离以及长宽比的对数,这一点和其他的检测模型都是相同的,代码如下:
def nonlinear_transform(ex_rois, gt_rois):
"""
compute bounding box regression targets from ex_rois to gt_rois
:param ex_rois: [N, 4]
:param gt_rois: [N, 4]
:return: [N, 4]
"""
assert ex_rois.shape[0] == gt_rois.shape[0], 'inconsistent rois number'
ex_widths = ex_rois[:, 2] - ex_rois[:, 0] + 1.0
ex_heights = ex_rois[:, 3] - ex_rois[:, 1] + 1.0
ex_ctr_x = ex_rois[:, 0] + 0.5 * (ex_widths - 1.0)
ex_ctr_y = ex_rois[:, 1] + 0.5 * (ex_heights - 1.0)
gt_widths = gt_rois[:, 2] - gt_rois[:, 0] + 1.0
gt_heights = gt_rois[:, 3] - gt_rois[:, 1] + 1.0
gt_ctr_x = gt_rois[:, 0] + 0.5 * (gt_widths - 1.0)
gt_ctr_y = gt_rois[:, 1] + 0.5 * (gt_heights - 1.0)
targets_dx = (gt_ctr_x - ex_ctr_x) / (ex_widths + 1e-14)
targets_dy = (gt_ctr_y - ex_ctr_y) / (ex_heights + 1e-14)
targets_dw = np.log(gt_widths / ex_widths)
targets_dh = np.log(gt_heights / ex_heights)
if gt_rois.shape[1]<=4:
targets = np.vstack(
(targets_dx, targets_dy, targets_dw, targets_dh)).transpose()
return targets
else:
targets = [targets_dx, targets_dy, targets_dw, targets_dh]
#if config.USE_BLUR:
# for i in range(4, gt_rois.shape[1]):
# t = gt_rois[:,i]
# targets.append(t)
targets = np.vstack(targets).transpose()
return targets
bbox_transform得到了网络检测框的训练目标,即中心点的相对位置target_dx, target_dy, 以及长宽比的对数值target_dw, target_dh。在带有关键点检测的模型中,同事还需要计算各个关键点的位置,代码如下:
def landmark_transform(ex_rois, gt_rois):
assert ex_rois.shape[0] == gt_rois.shape[0], 'inconsistent rois number'
ex_widths = ex_rois[:, 2] - ex_rois[:, 0] + 1.0
ex_heights = ex_rois[:, 3] - ex_rois[:, 1] + 1.0
ex_ctr_x = ex_rois[:, 0] + 0.5 * (ex_widths - 1.0)
ex_ctr_y = ex_rois[:, 1] + 0.5 * (ex_heights - 1.0)
targets = []
for i in range(gt_rois.shape[1]):
for j in range(gt_rois.shape[2]):
#if not config.USE_OCCLUSION and j==2:
# continue
if j==2:
continue
if j==0: #w
target = (gt_rois[:,i,j] - ex_ctr_x) / (ex_widths + 1e-14)
elif j==1: #h
target = (gt_rois[:,i,j] - ex_ctr_y) / (ex_heights + 1e-14)
else: #visibile
target = gt_rois[:,i,j]
targets.append(target)
targets = np.vstack(targets).transpose()
return targets
关键点的训练目标同样是相对偏移量,如代码所示,计算的是关键点和检测框中心点的相对距离。注意关键点坐标回归与检测框位置回归相同,只存在于标注的正例中,因此所有的负例的landmark_weights都会被置0, 在标注的数据中有时会出现关键点漏标或是不可见的情况,这种情况下关键点将被丢弃,即landmark_weight置为0。
至此,训练中每一个anchor的所对应的label,bbox_targets, bbox_weights, landmark_targets, landmark_weights都已经准备完毕,label是一个Na 维向量, bbox_targets是Na * 4和landmark_targets是Na * 10的向量(5个关键点),之前提到这些向量是按照anchor的id对应顺序所排列的,为了和网络输出anchor的顺序相一致,需要再通过reshape的步骤调整顺序,代码如下:
for i in range(len(feat_strides)):
stride = feat_strides[i]
feat_height, feat_width = feat_infos[i]
A = A_list[i]
_label = labels[sum(anchors_num_range[:i+1]):sum(anchors_num_range[:i+1])+anchors_num_range[i+1]]
bbox_target = bbox_targets[sum(anchors_num_range[:i+1]):sum(anchors_num_range[:i+1])+anchors_num_range[i+1]]
bbox_weight = bbox_weights[sum(anchors_num_range[:i+1]):sum(anchors_num_range[:i+1])+anchors_num_range[i+1]]
if landmark:
landmark_target = landmark_targets[sum(anchors_num_range[:i+1]):sum(anchors_num_range[:i+1])+anchors_num_range[i+1]]
landmark_weight = landmark_weights[sum(anchors_num_range[:i+1]):sum(anchors_num_range[:i+1])+anchors_num_range[i+1]]
_label = _label.reshape((1, feat_height, feat_width, A)).transpose(0, 3, 1, 2)
_label = _label.reshape((1, A * feat_height * feat_width))
bbox_target = bbox_target.reshape((1, feat_height*feat_width, A * bbox_pred_len)).transpose(0, 2, 1)
bbox_weight = bbox_weight.reshape((1, feat_height*feat_width, A * bbox_pred_len)).transpose((0, 2, 1))
label['%s_label_stride%d'%(prefix, stride)] = _label
label['%s_bbox_target_stride%d'%(prefix,stride)] = bbox_target
label['%s_bbox_weight_stride%d'%(prefix,stride)] = bbox_weight
if landmark:
landmark_target = landmark_target.reshape((1, feat_height*feat_width, A * landmark_pred_len)).transpose(0, 2, 1)
landmark_weight = landmark_weight.reshape((1, feat_height*feat_width, A * landmark_pred_len)).transpose((0, 2, 1))
label['%s_landmark_target_stride%d'%(prefix,stride)] = landmark_target
label['%s_landmark_weight_stride%d'%(prefix,stride)] = landmark_weight
#print('in_rpn', stride,_label.shape, bbox_target.shape, bbox_weight.shape, file=sys.stderr)
label_list.append(_label)
#print('DD', _label.shape)
bbox_target_list.append(bbox_target)
bbox_weight_list.append(bbox_weight)
if landmark:
landmark_target_list.append(landmark_target)
landmark_weight_list.append(landmark_weight)
对各个stride分别调整label形状如下,与对应的label_name匹配后,得到了最终的训练用的label
1)label: (1, A * feat_height * feat_width)
2)bbox_target, bbox_weight: (1, A * bbox_pred_len, feat_height * feat_width)
3)landmark_target, landmark_weight: (1, A * landmark_pred_len, feat_height * feat_width)
其中 A 为输出feature map每个每个像素点对应的anchor个数,源代码中为2, feat_height和feat_width是各个stride分别的feature map的长度和宽度,对比下网络结构代码rcnn/symbol/symbol_common.py中的get_out()中输出部分的大小,具体如下,也可以发现label准备的形状大小和网络的输出也是完全符合的。
# prepare rpn data
rpn_cls_score_reshape = mx.symbol.Reshape(data=rpn_cls_score,
shape=(0, 2, -1),
name="%s_rpn_cls_score_reshape_stride%s" % (prefix,stride))
rpn_bbox_pred_reshape = mx.symbol.Reshape(data=rpn_bbox_pred,
shape=(0, 0, -1),
name="%s_rpn_bbox_pred_reshape_stride%s" % (prefix,stride))
if landmark:
rpn_landmark_pred = conv_only(rpn_relu, '%s_rpn_landmark_pred_stride%d'%(prefix,stride), landmark_pred_len*num_anchors,
kernel=(1,1), pad=(0,0), stride=(1, 1), shared_weight = shared_vars[2][0], shared_bias = shared_vars[2][1])
rpn_landmark_pred_reshape = mx.symbol.Reshape(data=rpn_landmark_pred,
shape=(0, 0, -1),
name="%s_rpn_landmark_pred_reshape_stride%s" % (prefix,stride))
if config.TRAIN.RPN_ENABLE_OHEM>=2:
label, anchor_weight, valid_count = mx.sym.Custom(op_type='rpn_fpn_ohem3', stride=int(stride), network=config.network, dataset=config.dataset, prefix=prefix, cls_score=rpn_cls_score_reshape, labels = label)
_bbox_weight = mx.sym.tile(anchor_weight, (1,1,bbox_pred_len))
_bbox_weight = _bbox_weight.reshape((0, -1, A * bbox_pred_len)).transpose((0,2,1))
bbox_weight = mx.sym.elemwise_mul(bbox_weight, _bbox_weight, name='%s_bbox_weight_mul_stride%s'%(prefix,stride))
if landmark:
_landmark_weight = mx.sym.tile(anchor_weight, (1,1,landmark_pred_len))
_landmark_weight = _landmark_weight.reshape((0, -1, A * landmark_pred_len)).transpose((0,2,1)) #A is anchor number
landmark_weight = mx.sym.elemwise_mul(landmark_weight, _landmark_weight, name='%s_landmark_weight_mul_stride%s'%(prefix,stride))
#if not config.FACE_LANDMARK:
# label, bbox_weight = mx.sym.Custom(op_type='rpn_fpn_ohem', stride=int(stride), cls_score=rpn_cls_score_reshape, bbox_weight = bbox_weight , labels = label)
#else:
# label, bbox_weight, landmark_weight = mx.sym.Custom(op_type='rpn_fpn_ohem2', stride=int(stride), cls_score=rpn_cls_score_reshape, bbox_weight = bbox_weight, landmark_weight=landmark_weight, labels = label)
#cls loss
rpn_cls_prob = mx.symbol.SoftmaxOutput(data=rpn_cls_score_reshape,
label=label,
multi_output=True,
normalization='valid', use_ignore=True, ignore_label=-1,
grad_scale = lr_mult,
name='%s_rpn_cls_prob_stride%d'%(prefix,stride))
网络的3个reshape层将label的输出大小设置为(bs, 2, A * feat_width * feat_height), bbox的输出大小为(bs, A * bbox_pred_len , feat_width * feat_height), landmark输出大小为(bs, A * landmark_pred_len , feat_width * feat_height), bbox和landmark完全符合, label看似不同,但这是mxnet框架二分类问题求SoftmaxOutput损失的正确参数输入规范(请查阅mxnet手册中SoftmaxOutput部分)。注意求分类损失过程中丢弃的anchor也是在SoftmaxOutput中通过定义use_ignore=True, ignore_label=-1实现的。求bbox和landmark回归损失的代码如下:
#bbox loss
bbox_diff = rpn_bbox_pred_reshape-bbox_target
bbox_diff = bbox_diff * bbox_weight
rpn_bbox_loss_ = mx.symbol.smooth_l1(name='%s_rpn_bbox_loss_stride%d_'%(prefix,stride), scalar=3.0, data=bbox_diff)
if config.LR_MODE==0:
rpn_bbox_loss = mx.sym.MakeLoss(name='%s_rpn_bbox_loss_stride%d'%(prefix,stride), data=rpn_bbox_loss_, grad_scale=1.0*lr_mult / (config.TRAIN.RPN_BATCH_SIZE))
else:
rpn_bbox_loss_ = mx.symbol.broadcast_div(rpn_bbox_loss_, valid_count)
rpn_bbox_loss = mx.sym.MakeLoss(name='%s_rpn_bbox_loss_stride%d'%(prefix,stride), data=rpn_bbox_loss_, grad_scale=0.25*lr_mult)
ret_group.append(rpn_bbox_loss)
ret_group.append(mx.sym.BlockGrad(bbox_weight))
#landmark loss
if landmark:
landmark_diff = rpn_landmark_pred_reshape-landmark_target
landmark_diff = landmark_diff * landmark_weight
rpn_landmark_loss_ = mx.symbol.smooth_l1(name='%s_rpn_landmark_loss_stride%d_'%(prefix,stride), scalar=3.0, data=landmark_diff)
if config.LR_MODE==0:
rpn_landmark_loss = mx.sym.MakeLoss(name='%s_rpn_landmark_loss_stride%d'%(prefix,stride), data=rpn_landmark_loss_, grad_scale=0.4*config.LANDMARK_LR_MULT*lr_mult / (config.TRAIN.RPN_BATCH_SIZE))
else:
rpn_landmark_loss_ = mx.symbol.broadcast_div(rpn_landmark_loss_, valid_count)
rpn_landmark_loss = mx.sym.MakeLoss(name='%s_rpn_landmark_loss_stride%d'%(prefix,stride), data=rpn_landmark_loss_, grad_scale=0.1*config.LANDMARK_LR_MULT*lr_mult)
ret_group.append(rpn_landmark_loss)
ret_group.append(mx.sym.BlockGrad(landmark_weight))
回归部分的损失计算用的都是smooth L1,和faster rcnn相同。 label中的只有正例将参与计算回归损失,其余将不参与,这个可以通过之前得到的bbox_weight和landmark_weight实现的(相当于mask的作用)。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















