















































软件

产品


OpenPose人体姿态识别项目是美国卡耐基梅隆大学(CMU)基于卷积神经网络和监督学习并以caffe为框架开发的开源库。可以实现人体动作、面部表情、手指运动等姿态估计。适用于单人和多人,具有极好的鲁棒性。是世界上首个基于深度学习的实时多人二维姿态估计应用,基于它的实例如雨后春笋般涌现。人体姿态估计技术在体育健身、动作采集、3D试衣、舆情监测等领域具有广阔的应用前景,人们更加熟悉的应用就是抖音尬舞机。
提出Part Affinity Fields (PAFs),每个像素是2D的向量,用于表征位置和方向信息。基于检测出的关节点和关节联通区域,使用greedy inference算法,可以将这些关节点快速对应到不同人物个体。
OpenPose是基于卷积神经网络和监督学习并以caffe为框架写成的开源库,可以实现人的面部表情、躯干和四肢甚至手指的跟踪,不仅适用于单人也适用于多人,同时具有较好的鲁棒性。可以称是世界上第一个基于深度学习的实时多人二维姿态估计,是人机交互上的一个里程碑,为机器理解人提供了一个高质量的信息维度。
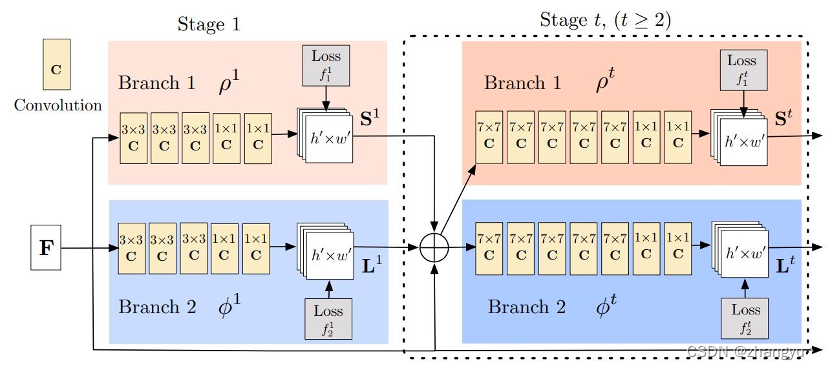
网络分上下两个分支,分别预测关键点热力图和paf图。每个分支都有t个阶段,表示越来越精细,每个阶段都会将feature maps进行融合。其中ρ φ 表示网络。训练时,每个阶段都会产生loss,避免梯度消失;预测时只使用最后一层的输出。
CPM的模型采用的大卷积核来获得大的感受野,这对于推断被遮挡的关节是很有效的。网络结构如下: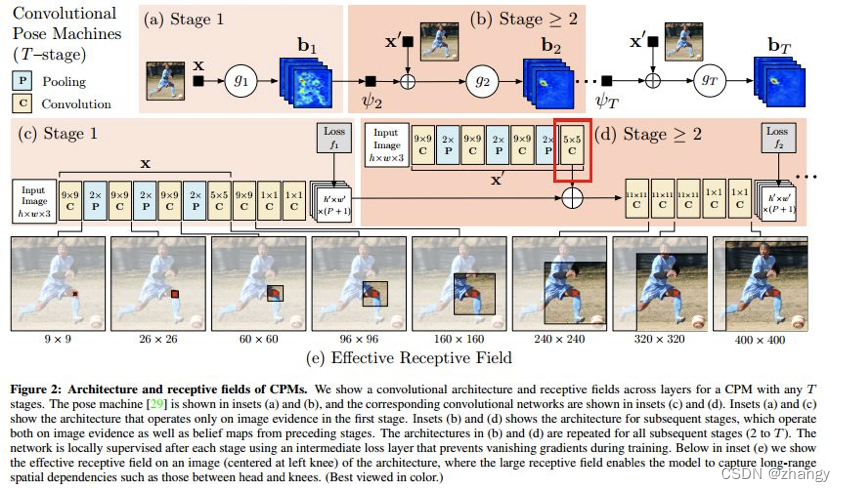
a) 首先对图像的所有出现的人进行回归,回归各个人的关节的点
b) 然后根据center map来去除掉对其他人的响应
c) 最后通过重复地对预测出来的heatmap进行refine得到最终的结果在进行refine的时候,需要引入中间层的loss,从而保证较深的网络仍然可以训练下去,不至于梯度弥散或者爆炸。通过coarse to fine来逐渐提升回归的准确度。
耗显存
计算量很大,为了达到实时的目的,使用了高并行的策略。基于cuda加速,所以非常吃显存,基本劝退显存低于4G的机器了(GTX 980ti+)
特殊场景监测效果差
图像分辨率低、运动模糊、低亮度、检测目标密集、遮挡严重、不完整目标等,效果都不是很理想。

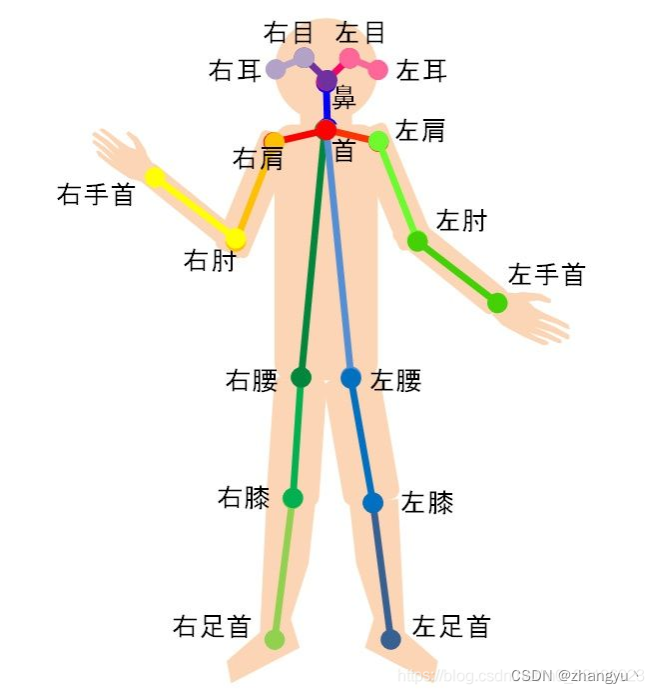
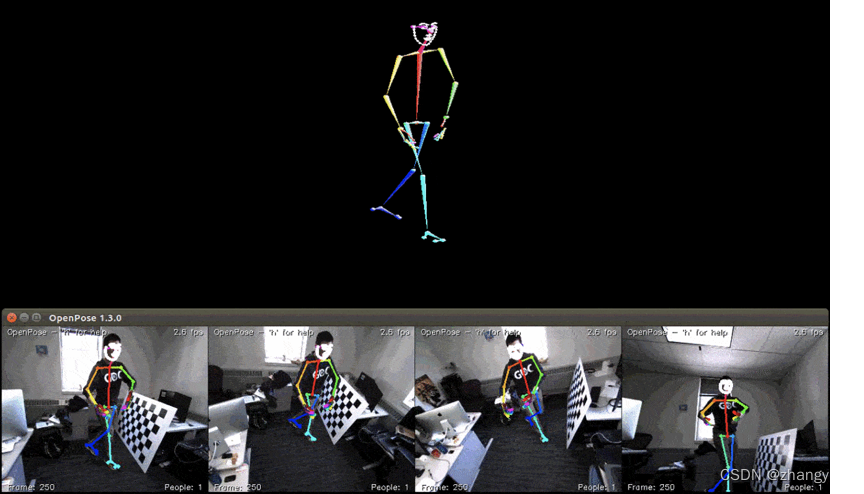
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















