















































软件

产品


SLAM (simultaneous localization and mapping),也称为CML (Concurrent Mapping and Localization), 即时定位与地图构建,或并发建图与定位。问题可以描述为:将一个机器人放入未知环境中的未知位置,是否有办法让机器人一边移动一边逐步描绘出此环境完全的地图,所谓完全的地图(a consistent map)是指不受障碍行进到房间可进入的每个角落。
整个视觉 SLAM 流程包括以下步骤。
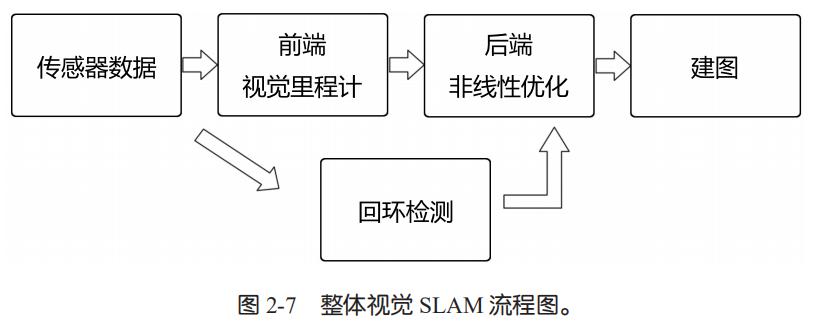
1. 传感器信息读取。在视觉 SLAM 中主要为相机图像信息的读取和预处理。如果是在机器人中,还可能有码盘、惯性传感器等信息的读取和同步。
2. 视觉里程计(Visual Odometry,VO)。视觉里程计的任务是估算相邻图像间相机的运动,以及局部地图的样子。VO 又称为前端(Front End)。
3. 后端优化(Optimization)。后端接受不同时刻视觉里程计测量的相机位姿,以及回环检测的信息,对它们进行优化,得到全局一致的轨迹和地图。由于接在 VO 之后,又称为后端(Back End)。
4. 回环检测(Loop Closing)。回环检测判断机器人是否到达过先前的位置。如果检测到回环,它会把信息提供给后端进行处理。
5. 建图(Mapping)。它根据估计的轨迹,建立与任务要求对应的地图。
SLAM问题的数学表述
相机通常是在离散的采集数据的,把一段连续时间的运动变成了离散时刻 t = 1, · · · , K 当中发生的事情。在这些时刻,用 x 表示机器人自身的位置,于是各时刻的位置记为 x1, · · · , xK,它们构成了机器人的轨迹。地图方面,假设地图是由许多个路标(Landmark)组成的,而每个时刻,传感器会测量到一部分路标点,得到它们的观测数据。不妨设路标点一共有 N 个,用 y1, · · · , yN 表示它们。路标顾名思义就是标志物,即场景中比较有辨识度的物体或者区域。在视觉SLAM中,每一个特征点就是一个landmark。
这里说的位置,其实是位姿,即位置和姿态。在平面运动中,机器人可用一个二维坐标加一个转角将位置形式化。而三维空间中运动的机器人则可以用相对与世界坐标系的变换矩阵描述(或四元数、旋转向量等)。
“机器人携带着传感器在环境中运动”由运动和观测描述。运动:要考察从k−1时刻到k时刻,机器人的位置 x 是如何变化的。观测:假设机器人在 k 时刻于xk处探测到了某一个路标yj。使用一个通用的、抽象的数学模型来描述运动,即运动方程:
xk=f(xk-1,uk,wk)
SLAM (simultaneous localization and mapping),也称为CML (Concurrent Mapping and Localization), 即时定位与地图构建,或并发建图与定位。问题可以描述为:将一个机器人放入未知环境中的未知位置,是否有办法让机器人一边移动一边逐步描绘出此环境完全的地图,所谓完全的地图(a consistent map)是指不受障碍行进到房间可进入的每个角落。
整个视觉 SLAM 流程包括以下步骤。
1. 传感器信息读取。在视觉 SLAM 中主要为相机图像信息的读取和预处理。如果是在机器人中,还可能有码盘、惯性传感器等信息的读取和同步。
2. 视觉里程计(Visual Odometry,VO)。视觉里程计的任务是估算相邻图像间相机的运动,以及局部地图的样子。VO 又称为前端(Front End)。
3. 后端优化(Optimization)。后端接受不同时刻视觉里程计测量的相机位姿,以及回环检测的信息,对它们进行优化,得到全局一致的轨迹和地图。由于接在 VO 之后,又称为后端(Back End)。
4. 回环检测(Loop Closing)。回环检测判断机器人是否到达过先前的位置。如果检测到回环,它会把信息提供给后端进行处理。
5. 建图(Mapping)。它根据估计的轨迹,建立与任务要求对应的地图。
SLAM问题的数学表述
相机通常是在离散的采集数据的,把一段连续时间的运动变成了离散时刻 t = 1, · · · , K 当中发生的事情。在这些时刻,用 x 表示机器人自身的位置,于是各时刻的位置记为 x1, · · · , xK,它们构成了机器人的轨迹。地图方面,假设地图是由许多个路标(Landmark)组成的,而每个时刻,传感器会测量到一部分路标点,得到它们的观测数据。不妨设路标点一共有 N 个,用 y1, · · · , yN 表示它们。路标顾名思义就是标志物,即场景中比较有辨识度的物体或者区域。在视觉SLAM中,每一个特征点就是一个landmark。
这里说的位置,其实是位姿,即位置和姿态。在平面运动中,机器人可用一个二维坐标加一个转角将位置形式化。而三维空间中运动的机器人则可以用相对与世界坐标系的变换矩阵描述(或四元数、旋转向量等)。
“机器人携带着传感器在环境中运动”由运动和观测描述。运动:要考察从k−1时刻到k时刻,机器人的位置 x 是如何变化的。观测:假设机器人在 k 时刻于xk处探测到了某一个路标yj。使用一个通用的、抽象的数学模型来描述运动,即运动方程:
xk=f(xk-1,uk,wk)
其中xk是机器人或者说传感器的位姿,uk是运动传感器(码盘、惯性传感器)的读数或输入,wk是噪声。噪声的存在使得这个模型变成了随机模型。观测方程:在xk位姿看到某个路标点yj,产生观测数据 zk,j,vk,j是观测里的噪声:
zk,j=h(yj,xk,vk,j)
举例
上面两个方程都是抽象的,可以根据真实的机器人进行参数化。机器人在平面中运动,那么位姿可由坐标和转角描述,uk是两个时间间隔位置和转角的变化量,运动方程具体化为:
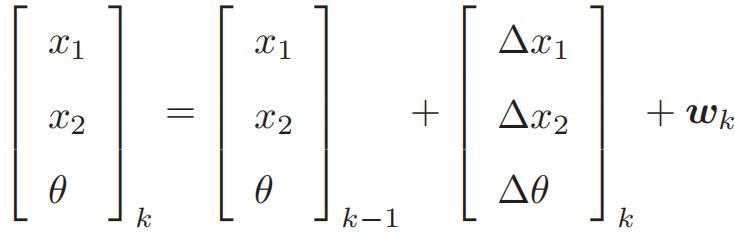
假设有一个二维激光传感器,激光传感器观测一个 2D 路标点时,能够测到两个量:路标点与小萝卜本体之间的距离 r 和夹角 ϕ。上式中,路标点为yj=[y1,y2],机器人位姿为xk=[x1,x2],观测数据为zk,j=[rk,j,ϕk,j]。
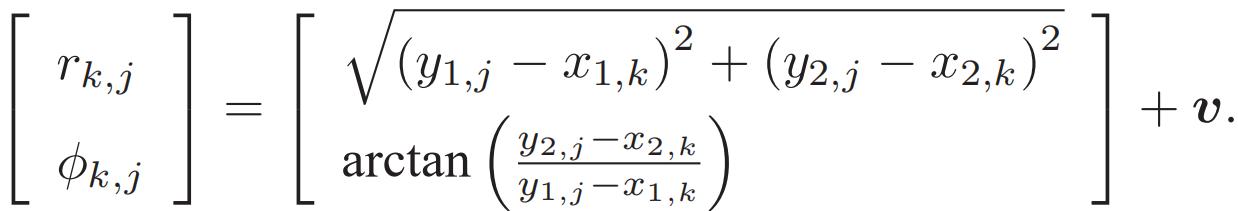
而在视觉SLAM中,观测方程就是是“对路标点拍摄后,得到图像中的像素”的过程。
因此SLAM的通用方程:
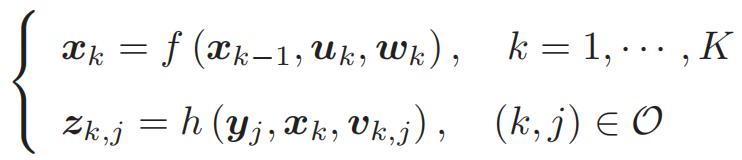
最基本的 SLAM 问题:当知道运动测量的读数 u,以及传感器的读数 z 时,如何求解定位问题(估计 x)和建图问题(估计 y)。这时,我们就把 SLAM 问题建模成了一个状态估计问题:如何通过带有噪声的测量数据,估计内部的、隐藏着的状态变量。
按照运动和观测方程是否为线性,噪声是否服从高斯分布进行分类,分为线性/非线性和高斯/非高斯系统。其中线性高斯系统(Linear Gaussian,LG 系统)是最简单的,它的无偏的最优估计可以由卡尔曼滤波器(Kalman Filter,KF)给出。而在复杂的非线性非高斯系统(Non-Linear Non-Gaussian,NLNG 系统)中,我们会使用以扩展卡尔曼滤波器(Extended Kalman Filter,EKF)和非线性优化两大类方法去求解。
前端
视觉里程计(VO)也称为前端。VO 根据相邻图像的信息估计出粗略的相机运动,给后端提供较好的初始值。VO 的算法主要分为两个大类:特征点法和直接法。
VO 的核心问题是如何根据图像来估计相机运动。从图像中选取比较有代表性的点,这些点在相机视角发生少量变化后会保持不变,于是我们能在各个图像中找到相同的点。然后,在这些点的基础上,讨论相机位姿估计问题,以及这些点的定位问题。在经典 SLAM 模型中,我们称这些点为路标(Landmark)。而在视觉 SLAM 中,路标则是指图像特征点(Feature)。一般采用角点作为特征点:
角点的提取算法有很多,比较早的有Harris 角点、FAST 角点、GFTT 角点等等。后来发现单纯的角点不能满足需求,于是人们设计了一些更稳定的特征点,比如SIFT、SURF、ORB等。人工设计的特征点的特点如下:
1.可重复性(Repeatability):相同的特征可以在不同的图像中找到。 2.可区别性(Distinctiveness):不同的特征有不同的表达。 3.高效率(Efficiency):同一图像中,特征点的数量应远小于像素的数量。 4.本地性(Locality):特征仅与一小片图像区域相关。
特征点由关键点(Key-point)和描述子(Descriptor)两部分组成。关键点是指该特征点在图像里的位置,有些特征点还具有朝向、大小等信息。描述子通常是一个向量,按照某种人为设计的方式,描述了该关键点周围像素的信息。描述子是按照“外观相似的特征应该有相似的描述子”的原则设计的。因此,只要两个特征点的描述子在向量空间上的距离相近,就可以认为它们是同样的特征点
ORB 特征亦由关键点和描述子两部分组成。它的关键点称为“Oriented FAST”,是一种改进的 FAST 角点。它的描述子称为BRIEF(Binary Robust Independent Elementary Feature)。
特征匹配是视觉 SLAM 中极为关键的一步,宽泛地说,特征匹配解决了 SLAM中的数据关联问题(data association),即确定当前看到的路标与之前看到的路标之间的对应关系。考虑两个时刻的图像。如果在图像 It 中提取到特征点 x_m_t, m = 1, 2, ..., M,在图像 It+1 中提取到特征点 x_n_t+1, n =1, 2, ..., N,然后将这两组特征点一一匹配起来。
最简单的特征匹配方法就是暴力匹配(Brute Force Matcher)。即对每一个特征点 xmt 与所有的 xnt+1 测量描述子的距离,然后排序,取最近的一个作为匹配点。描述子距离表示了两个特征之间的相似程度,实际运用中可以取不同的距离度量范数。对于浮点类型的描述子,使用欧氏距离进行度量即可。而对于二进制的描述子(比如BRIEF 这样的),往往使用汉明距离(Hamming distance)作为度量:两个二进制串之间的汉明距离,指的是其不同位数的个数。
当特征点数量很大时,暴力匹配法的运算量将变得很大,特别是当想要匹配某个帧和一张地图的时候。此时快速近似最近邻(FLANN)算法更加适合于匹配点数量极多的情况。
有了匹配好的点后,接下来,根据点对来估计相机的运动。有下列几种情况:
1. 当相机为单目时,我们只知道 2D 的像素坐标,因而问题是根据两组 2D 点估计运动。该问题用对极几何来解决。
2. 当相机为双目、RGB-D 时,或者通过某种方法得到了距离信息,那么问题就是根据两组 3D点估计运动。该问题通常用 ICP 来解决。
3. 如果一组为 3D,一组为 2D,即,我们得到了一些 3D 点和它们在相机的投影位置,也能估计相机的运动。该问题通过 PnP 求解。
通过特征点估计相机运动的方法虽然是主流,但是有如下缺点:1.关键点的提取和描述子的计算非常耗时;2.使用特征点时,忽略除特征点以外的所有信息;3.有时会运动到没有纹理的地方,无法计算特征点。解决上述缺点的思路:
A.保留特征点,但只计算关键点,不计算描述子,使用光流法(Optical Flow)来跟踪特征点的运动。
B.只计算关键点,不计算描述子,使用直接法(Direct Method)来计算特征点在下一时刻图像中的位置。
C.不使用特征点,而是根据像素灰度的差异,直接计算相机运动。
后端
前端能给出一个短时间内的轨迹和地图,但由于不可避免的误差累计,这个地图在长时间内是不准确的。所以在VO的基础上,我们希望构建一个尺度、规模更大的优化问题,以考虑长时间内的最优轨迹和地图。
待续。。
回环检测
背景:前端提供特征点的提取和轨迹、地图的初值,而后端负责对这所有的数据进行优化。然而,如果像 VO 那样仅考虑相邻时间上的关联,那么,之前产生的误差将不可避免地累计到下一个时刻,使得整个 SLAM 会出现累积误差。长期估计的结果将不可靠,或者说,我们无法构建全局一致的轨迹和地图。
概念:回环检测能够给出除了相邻帧之外的,一些时隔更加久远的约束:例如 x1 − x100 之间的位姿变换。存在约束的原因是:我们察觉到相机经过了同一个地方,采集到了相似的数据。因此回环检测的关键,是如何有效地检测出相机经过同一个地方这件事。如果我们能够成功地检测这件事,就可以为后端的 Pose Graph 提供更多的有效数据,使之得到更好的估计,特别是得到一个全局一致(Global Consistent)的估计。
重要性:回环检测关系到我们估计的轨迹和地图在长时间下的正确性。由于回环检测提供了当前数据与所有历史数据的关联,在跟踪算法丢失之后,我们还可以利用回环检测进行重定位。因此,回环检测对整个 SLAM 系统精度与鲁棒性的提升,是非常明显的。甚至在某些时候,我们把仅有前端和局部后端的系统称为VO,而把带有回环检测和全局后端的称为 SLAM。
实现方法:直观的方法是将当前帧与前面所有的帧都进行特征匹配,根据正确匹配的数量确定哪两张图像存在关联,但是这种方法过于低效。目前大体分为两种思路:基于里程计的几何关系(Odometry based),或基于外观(Appearance based)。基于几何关系是说,当我们发现当前相机运动到了之前的某个位置附近时,检测它们有没有回环关系——这自然是一种直观的想法,但是由于累积误差的存在,我们往往没法正确地发现“运动到了之前的某个位置附近”这件事实,回环检测也无从谈起。基于外观的回环检测,它和前端后端的估计都无关,仅根据两张图像的相似性确定回环检测关系。这种做法摆脱了累计误差,使回环检测模块成为 SLAM 系统中一个相对独立的模块(当然前端可以为它提供特征点)。基于外观的回环检测方式能够有效地在不同场景下工作,成为了视觉 SLAM 中主流的做法,其中最经典是词袋模型。
在 SLAM 中,对准确率要求更高,而对召回率则相对宽容一些。在选择回环检测算法时,我们更倾向于把参数设置地更严格一些,或者在检测之后再加上回环验证的步骤。
相似性评分的处理:对任意两个图像,词袋模型都能给出一个相似性评分,但是只利用这个分值的绝对大小,不好判断。譬如说,有些环境的外观本来就很相似,像办公室往往有很多同款式的桌椅;另一些环境则各个地方都有很大的不同。因此,一般会取一个先验相似度 s(vt, vt−∆t),它表示某时刻关键帧图像与上一时刻的关键帧的相似性。然后,其他的分值都参照这个值进行归一化:s(vt, vtj)′= s(vt, vtj) / s(vt, vt−∆t) 。如果当前帧与之前某关键帧的相似度,超过当前帧与上一个关键帧相似度的 3 倍,就认为可能存在回环。这个步骤避免了引入绝对的相似性阈值,使得算法能够适应更多的环境。
关键帧的处理:在检测回环时,必须考虑到关键帧的选取。如果关键帧选得太近,那么导致两个关键帧之间的相似性过高,相比之下不容易检测出历史数据中的回环。所以用于回环检测的帧最好是稀疏一些,彼此之间不太相同,又能涵盖整个环境。另一方面,如果成功检测到了回环,比如说出现在第 1 帧和第 n 帧。那么很可能第n + 1 帧,n + 2 帧都会和第 1 帧构成回环。但是,确认第 1 帧和第 n 帧之间存在回环,对轨迹优化是有帮助的,但再接下去的第 n + 1 帧,n + 2 帧都会和第 1 帧构成回环,产生的帮助就没那么大了,因为我们已经用之前的信息消除了累计误差,更多的回环并不会带来更多的信息。所以,我们会把“相近”的回环聚成一类,使算法不要反复地检测同一类的回环。
检测之后的验证:词袋的回环检测算法完全依赖于外观而没有利用任何的几何信息,这导致外观相似的图像容易被当成回环。并且,由于词袋不在乎单词顺序,只在意单词有无的表达方式,更容易引发感知偏差(即假阳性,把不是回环的帧误判为回环)。所以,在回环检测之后,我们通常还会有一个验证步骤。验证的方法有很多。其一是设立回环的缓存机制,认为单次检测到的回环并不足以构成良好的约束,而在一段时间中一直检测到的回环,才认为是正确的回环。这可以看成时间上的一致性检测。另一方法是空间上的一致性检测,即是对回环检测到的两个帧进行特征匹配,估计相机的运动。然后,再把运动放到之前的 Pose Graph 中,检查与之前的估计是否有很大的出入。验证部分通常是必须的。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















