















































软件

产品


今天解读我阅读的一篇论文 retinaface 。
retinaface是一款继mtcnn以后的,single-stage人脸检测框架,并利用强监督和自监督信号的多任务损失计算,提出了一种most state-of-the- art 的密集人脸定位方法。它加入了五个人脸Landmark对人脸关键点进行了定位。
1.采用了多任务学习,人脸分类,人脸框回归,人脸的landmark(人脸关键点定位)同时计算出。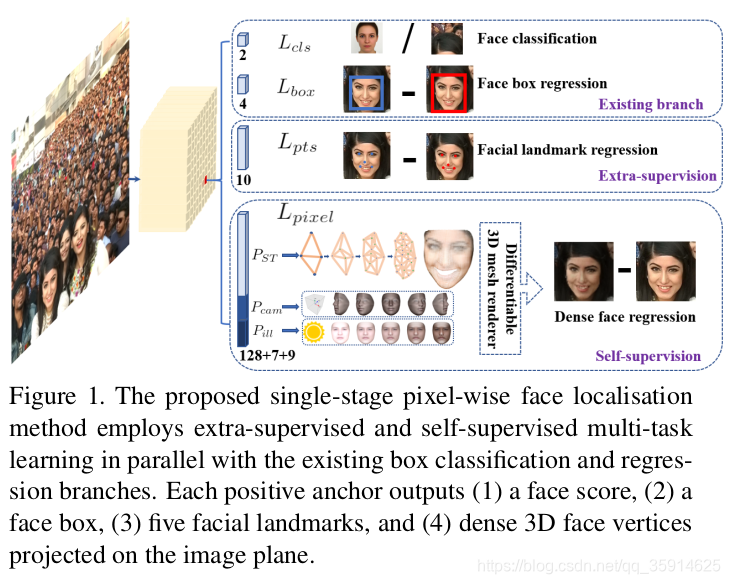
2.使用 ResNet -152,提升了精度(AP 91.8% 在WIDER FACE hard set),使用小的特征提取网络MobilenetV1-0.25(AP78.25 在WIDER FACE hard set)),实现了 cpu 实时检测。
3.利用特征金字塔,加强了特征融合。
4.加入了ssh结构横向结构,利用33的卷积替换55和7*7的卷积,进一步加强了模型特征提取的感受野。
https://github.com/yanjingke/retinaface-keras
链接: https://pan.baidu.com/s/15WqLbrNzFJXxZ7zwP-FkOQ 提取码: 3msf 复制这段内容后打开百度网盘手机 App ,操作更方便哦
在本文特征提取部分主要介绍mobilenetV1-0.25。mobilenet是一款很好的在移动端进行运行的框架。它主要利用了 深度 可分离卷积。
其中深度可分离卷积是怎么减少计算量的啦?
假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。具体为,32个3×3大小的卷积核会遍历16个通道中的每个数据,最后可得到所需的32个输出通道,所需参数为16×32×3×3=4608个。
应用深度可分离卷积,用16个3×3大小的卷积核分别遍历16通道的数据,得到了16个特征图谱。在融合操作之前,接着用32个1×1大小的卷积核遍历这16个特征图谱,所需参数为16×3×3+16×32×1×1=656个。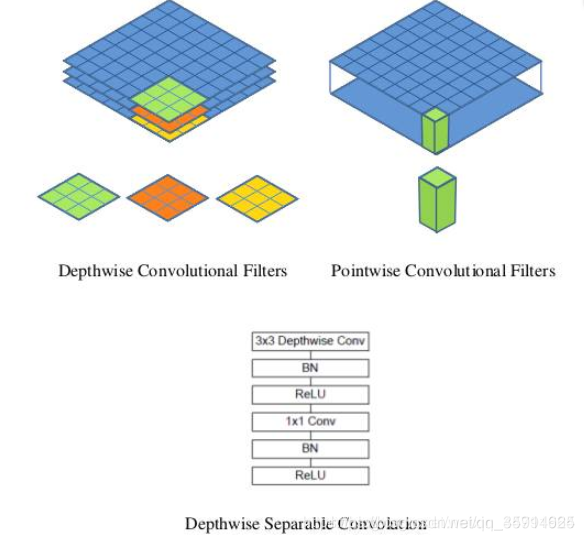
在我们的结构里面用DepthwiseConv2D代表深度可分离卷积,1*1的卷积主要是调整通道数的。这是mobilenetv1的结构图: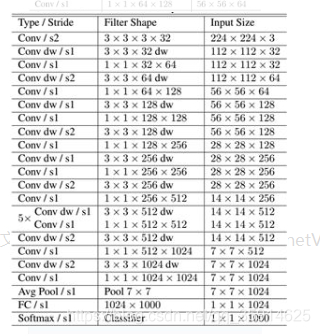
而mobilenetV1-0.25将通道数缩减到了4分之一,使参数下降到20w参数。
深度可分离卷积代码:
def _depthwise_conv_block(inputs, pointwise_conv_filters,
depth_multiplier=1, strides=(1, 1), block_id=1):
x = DepthwiseConv2D((3, 3),
padding='same',
depth_multiplier=depth_multiplier,
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(inputs)
x = BatchNormalization(name='conv_dw_%d_bn' % block_id)(x)
x = Activation(relu6, name='conv_dw_%d_relu' % block_id)(x)
x = Conv2D(pointwise_conv_filters, (1, 1),
padding='same',
use_bias=False,
strides=(1, 1),
name='conv_pw_%d' % block_id)(x)
x = BatchNormalization(name='conv_pw_%d_bn' % block_id)(x)
return Activation(relu6, name='conv_pw_%d_relu' % block_id)(x)
def relu6(x):
return K.relu(x, max_value=6)
mobilenet代码:
def _conv_block(inputs, filters, kernel=(3, 3), strides=(1, 1)):
x = Conv2D(filters, kernel,
padding='same',
use_bias=False,
strides=strides,
name='conv1')(inputs)
x = BatchNormalization(name='conv1_bn')(x)
return Activation(relu6, name='conv1_relu')(x)
def MobileNet(img_input, depth_multiplier=1):
# 640,640,3 -> 320,320,8
x = _conv_block(img_input, 8, strides=(2, 2))
# 320,320,8 -> 320,320,16
x = _depthwise_conv_block(x, 16, depth_multiplier, block_id=1)
# 320,320,16 -> 160,160,32
x = _depthwise_conv_block(x, 32, depth_multiplier, strides=(2, 2), block_id=2)
x = _depthwise_conv_block(x, 32, depth_multiplier, block_id=3)
# 160,160,32 -> 80,80,64
x = _depthwise_conv_block(x, 64, depth_multiplier, strides=(2, 2), block_id=4)
x = _depthwise_conv_block(x, 64, depth_multiplier, block_id=5)
feat1 = x
# 80,80,64 -> 40,40,128
x = _depthwise_conv_block(x, 128, depth_multiplier, strides=(2, 2), block_id=6)
x = _depthwise_conv_block(x, 128, depth_multiplier, block_id=7)
x = _depthwise_conv_block(x, 128, depth_multiplier, block_id=8)
x = _depthwise_conv_block(x, 128, depth_multiplier, block_id=9)
x = _depthwise_conv_block(x, 128, depth_multiplier, block_id=10)
x = _depthwise_conv_block(x, 128, depth_multiplier, block_id=11)
feat2 = x
# 40,40,128 -> 20,20,256
x = _depthwise_conv_block(x, 256, depth_multiplier, strides=(2, 2), block_id=12)
x = _depthwise_conv_block(x, 256, depth_multiplier, block_id=13)
feat3 = x
return feat1, feat2, feat3
def RetinaFace(cfg
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















