















































软件

产品


MTCNN分为三个网络:PNET,RNET,ONET
下面是该方法的流程图,可以看出也是三阶级联(与CascadeCNN一样)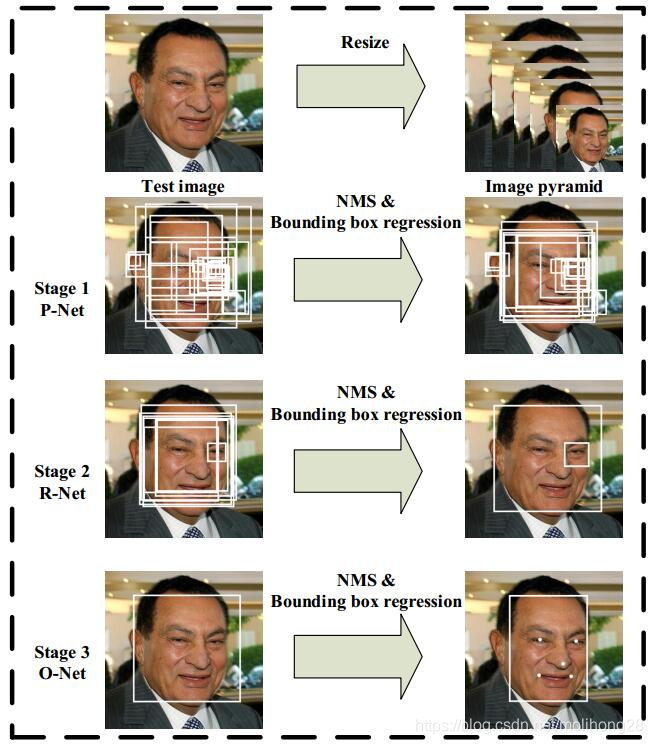
PNET: 在构建图像金字塔的基础上,利用全连接来进行检测,粗略提取脸部的候选框和回归量,然后利用回归 和 NMS来进行修正。(注意:这里的全卷积网络与R-CNN里面带反卷积的网络是不一样的,这里只是指只有卷积层,可以接受任意尺寸的输入,靠网络stride来自动完成滑窗)
RNET: 将通过PNET的所有窗口输入作进一步判断,同时也要做回归和 NMS。
ONET: 和RNET相似,只不过增加了更强的约束:5个人脸关键点。
接下来详细介绍这三个网络
PNET: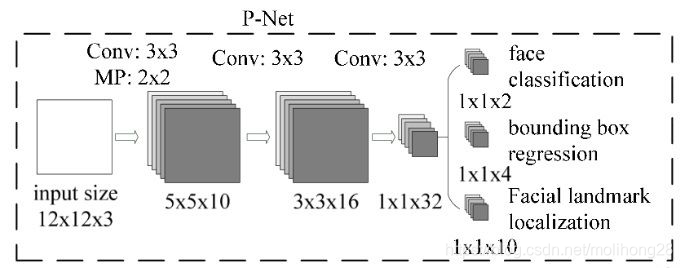
输入是一个12X12大小的图片,所以训练前需要把生成的训练数据(通过生成bounding box,然后把该bounding box 剪切成12X12大小的图片),转换成12X12X3的结构。
1、通过10个3X3X3的卷积核,2X2的Max Pooling(stride=2)操作,生成10个5*5的特征图
2、通过16个3X3X10的卷积核,生成16个3X3的特征图
3、通过32个3X3X16的卷积核,生成32个1X1的特征图。
4、针对32个1X1的特征图,可以通过2个1X1X32的卷积核,生成2个1X1的特征图用于分类;4个1X1X32的卷积核,生成4个1X1的特征图用于回归框判断;10个1X1X32的卷积核,生成10个1X1的特征图用于人脸轮廓点的判断。
RNET: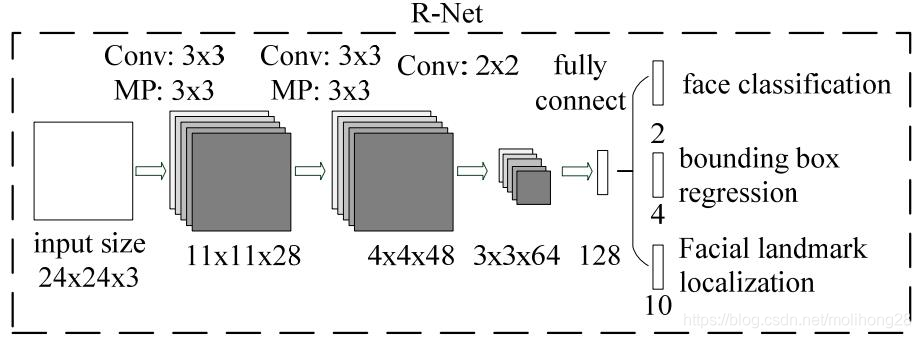
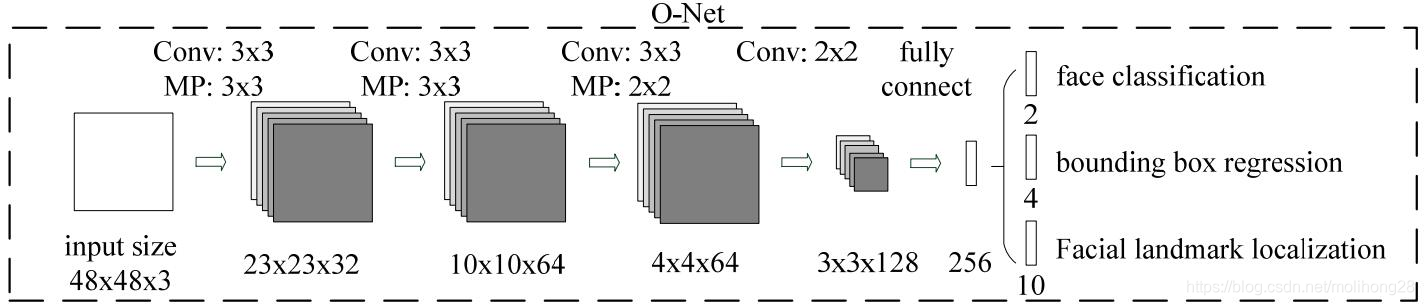
TRAING:
我们利用三项任务来训练我们的CNN探测器:面部/非面部分类,边界框回归和面部地标定位。
1、class:交叉熵,二分法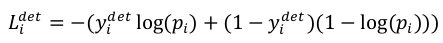
2、box:l2_loss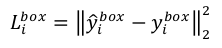
3、landmark:l2_loss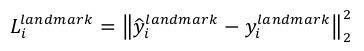
4、多源训练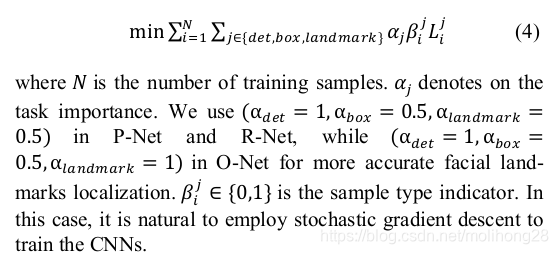
因为在训练时并不是对每个输入都计算上面的三个loss,因此通过4来控制不同输入计算不同loss,ONET的alpha最大,因为只有ONET才输出landmark,P、R重点在过滤beta:比如非人脸输入,则只计算class loss。
5、在线硬样本挖掘:与原始分类器训练后进行传统硬样本挖掘不同,我们在面部分类任务中进行在线硬样本挖掘,以适应训练过程。
特别是,在每个小批量中,我们对来自所有样本的前向传播阶段计算的损失进行排序,并选择其中前70%作为硬样本。 然后我们只计算后向传播阶段中硬样本的梯度。 这意味着我们忽略了在训练时不太有助于加强探测器的简单样本。 实验表明,该策略无需手动选择样本即可获得更好的性能。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















