















































软件

产品


神经网络中的参数是神经网络实现分类或回归问题中重要的部分。在tensorflow中,变量(tf.Variable)的作用就是保存和更新神经网络中的参数的。在tensorflow中,变量(tf.Variable)的作用就是保存和更新神经网络的参数。和其他编程语言类似,tensorflow中的变量也需要指定初始值。因为在神经网络中,给参数赋予随机初始值最为常见,所以一般也使用随机数给tensorflow中的变量初始化。下面一段代码给出了一种在tensorflow中声明一个2*3矩阵变量的方法:
weights = tf.Variable(tf.random_normal([2, 3], stddev = 2))
这段代码调用了tensorflow变量的声明函数tf.Variable。在变量声明函数中给出了初始化这个变量的方法。tensorflow中变量的初始值可以设置成随机数、常数或者是通过其他变量的初始值计算得到。在上面的样例中,tf.random_normal([2 ,3], stddev=2)会产生一个2x3的矩阵,矩阵中的元素是均值为0,标准差为2的随机数。tf.random_normal函数可以通过参数mean来指定平均值,在没有指定时默认为0。通过满足正太分布的随机数来初始化神经网络中的参数是一个非常有用的方法。除了正太分布的随机数,tensorflow还提供了一些其他的随机数发生器,下表列出了tensorflow目前支持的所有随机数发生器。
| 函数名称 | 随机数分布 | 主要参数 |
| tf.random_normal | 正太分布 | 平均值、标准差、取值类型 |
| tf.truncated_normal | 正太分布,但如果随机出来的值超过两个标准差,那么这个数将会被重新随机 | 平均值、标准差、取值类型 |
| tf.random_uniform | 均匀分布 | 最小取值、最大取值、取值类型 |
| tf.random_gamma | Gamma分布 | 形状参数alpha、尺度参数beta、取值类型 |
tensorflow也支持通过常量来初始化一个变量,下表给出了tensorflow中常用的变量声明方法。
| 函数名称 | 功能 | 样例 |
| tf.zeros | 产生全0的数组 | tf.zeros([2, 3], int32) -> [[0,0,0],[0,0,0]] |
| tf.ones | 产生全1的数组 | tf.ones([2, 3], int32) -> [[1,1,1],[1,1,1]] |
| tf.fill | 产生一个全部为给定数字的数组 | tf.fill([2, 3], 9) -> [[9, 9, 9],[9, 9, 9]] |
| tf.constant | 产生一个给定值的常数 |
在神经网络中,偏置值(bias)通常会使用常数来设置初始值。以下代码给出了一个样例:
biases = tf.Variable(tf.zeros([3]))
以上代码将会生成一个初始值全部为0且长度为3的变量。除了使用随机数或常数,tensorflow也支持通过其他变量的初始值来初始化新的变量。以下代码给出了具体的方法。
w2 = tf.Variable(weights.initialized_value())
w3 = tf.Variable(weights.initialized_value() * 2.0)
以上代码中,w2的初始值被设置成了与weights变量相同。w3的初始值则是weights初始值的两倍。在tensorflow中,一个变量的值在被使用之前,这个变量的初始化过程需要被明确地调用。以下样例介绍了如何通过变量实现神经网络的参数并实现前向传播过程。
import tensorflow as tf
# 声明w1、w2两个变量。这里还通过seed参数设定了随机种子。
# 这样可以保证每次运行得到的结果是一样的。
w1 = tf.Variable(tf.random_normal((2,3), stddev = 1, seed = 1 ))
w2 = tf.Variable(tf.random_normal((3,1), stddev = 1, seed = 1 ))
# 暂时将输入的随机向量定义为一个常量。注意这里x是一个1*2的矩阵。
x = tf.constant([0.7, 0.9])
# 描述前向传播算法获得神经网络的输出
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
sess = tf.Session()
# 这里不能直接通过sess.run(y)来获取y的取值
# 因为w1和w2都还没有运行初始化过程。以下两行分别初始化了w1和w2两个变量。
sess.run(w1.initializer) #初始化w1。
sess.run(w2.initializer) #初始化w2。
#输出[[3.95757794]]
print(sess.run(y))
sess.close()
以上程序实现了神经网络的前向传播过程。从这段代码可以看出,当声明了变量w1、w2之后,可以通过w1和w2来定义神经网络的前向传播过程并得到中间结果a和最后答案y。
在tensorflow程序的第二步回声明(session),并通过会话计算结果。在上面的样例中,当会话定义完成之后就可以真正运行定义好的计算了。但在计算y之前,需要将所有用到的变量初始化。也就是说,虽然在变量定义时给出了变量初始化的方法,但这个方法并没有被真正运行。但在计算y之前,需要通过运行w1.initializer和w2.initializer来给变量赋值。虽然直接调用每个变量的初始化过程是一个可行的方案,但是当变量数目增多,或者变量之间存在依赖关系时,耽搁调用的方案就比较麻烦了。为了解决这个问题,tensorflow提供了一种更加便捷的方式来完成变量初始化过程。以下程序展示了通过tf.global_variables_initializer函数实现初始化所有变量的过程。
init_op = tf.global_variables_initializer()
sess.run(init_op)
通过tf.global_variables_initializer函数,就不需要将变量一个一个初始化了。这个函数也会自动处理变量之间的依赖关系。
变量和张量的关系:
tensorflow的核心概念是张量(tensor),所有的数据都是通过张量的形式来组织的,那么变量和张量之间的关系时什么呢?在tensorflow中,变量的声明函数tf.Variable是一个运算。这个运算的输出结果是一个张量,这个张量也就是变量,所以变量是一种特殊的张量。
下面进一步介绍tf.Variable操作在tensorflow中底层是如何实现的。下图给出了神经网络前向传播样例程序的tensorflow计算图的一个部分,这个部分显示了和变量w1相关的操作。
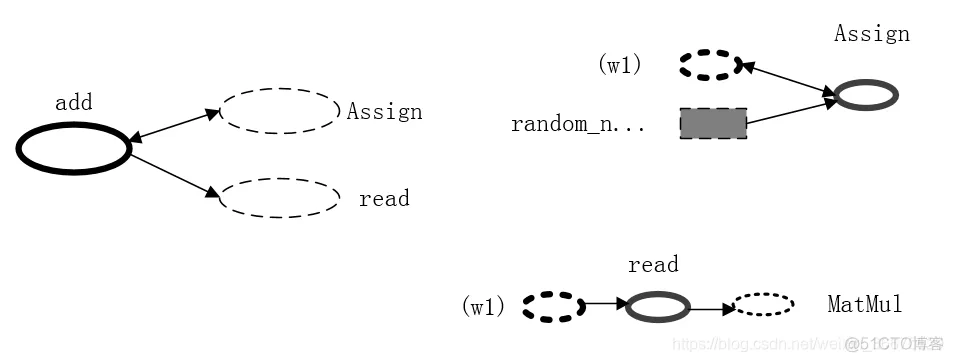
上图中黑色的椭圆代表了变量w1,可以看到w1是一个Variable运算。在这张图的下方可以看到w1通过一个read操作将值直接提供给了一个乘法运算,这个乘法运算就是tf.matmul(x, w1)。初始化变量w1的操作是通过Assign操作完成的。从上图可以看到Assign这个节点的输入为随机数生成函数的输出,而且输出赋给了变量w1。这样就完成了变量初始化的过程。
所有变量都被自动地加入到GraphKeys.VARIBALES这个集合中。通过tf.global_variable()函数可以拿到当前计算图上所有的变量。拿到计算图上所有的变量有助于持久化这个计算图的运行状态。当构建机器学习模型时,比如神经网络,可以通过变量声明函数中的trainable参数来区分需要优化的参数(比如神经网络中的参数)和其他参数(比如迭代的轮数)。如果声明变量时参数trainable为True,那么这个变量将会被自动加入到GraphKeys.TRAINABLE_VARIABLES集合。tensorflow中提供的神经网络优化算法会将GraphKeys.TRAINABLE_VARIABLES集合中的变量作为默认的优化对象。
类似张量,维度(shape)和类型(type)也是变量最重要的两个属性。和大部分程序语言类似,变量的类型是不可改变的。一个变量在构建之后,它的类型就不能再改变了。比如在上面给出的前向传播样例中,w1的类型为random_normal结果的默认类型为tf.float32,那么它将不能被赋予其他类型的值。以下代码将会报出类型不匹配的错误。
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1), name= "w1")
w2 = tf.Variable(tf.random_normal([2, 3], dtype=tf.float64, stddev = 1), name= "w2")
w1.assign(w2)
'''
程序将报错:
TypeError:Input 'value' of 'Assign' Op has type float64 that does not match type float32 of argument 'ref'
'''
维度是变量另一个重要的属性。和类型不大一样的是,维度在程序运行中是有可能改变的,但是需要通过设置参数validate_shape=False,下面给出了一段示范代码。
w1 = tf.Variable(tf.random_normal([2 ,3], stddev=1), name="w1")
w2 = tf.Variable(tf.random_normal([2 ,2], stddev=1), name="w2")
# 下面这句话会报维度不匹配的错误:
# ValueError: Dimension 1 in both shapes must be equal, but are 3 and 2
# for 'Assign_1' (op: 'Assign') with input shapes: [2, 3], [2, 2].
tf.assign(w1 ,w2)
#这句话可以被成功执行
tf.assign(w1, w2, validate_shape=False)
虽然tensorflow支持更改变量的维度,但是这种用法在实践中比较罕见。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















