















































软件

产品


按照惯例,每一个神经网络模型,除了自行编码实现算法外,也要调用Google的开源三方库TensorFlow,对比一下结果。本文将描述如何用TensorFlow封装一个BP网络。
【阅读前提】
一、代码设计
1、目标
与自行编码实现BP算法[3]的要求一样,希望用TensorFlow封装的结果也能提供如下功能:
2、伪码
如图1所示,用TensorFlow封装实现BP网络:类BPnn对外提供的3个接口:

图1 类BPnn的3个接口
训练接口train()是核心接口,调用TensorFlow的API,遵循TensorFlow的编程习惯,其处理过程如图2所示,分为构建阶段和执行阶段。
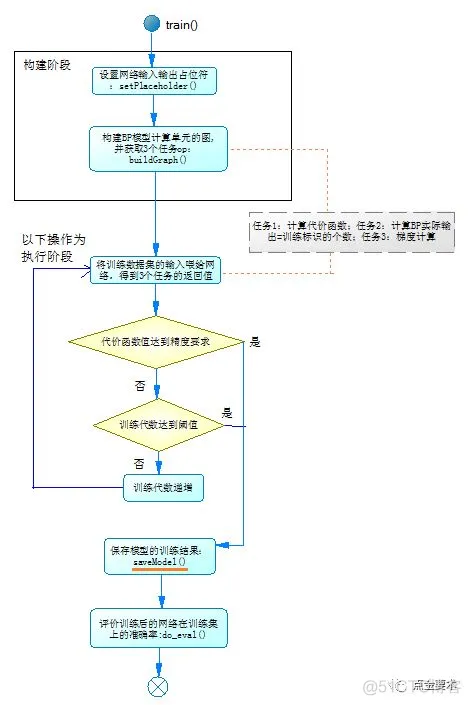
图2 训练接口
构建阶段中有3个任务op,将在执行阶段被执行:
1)计算代价函数,
2) 根据训练集中标识数据,计算BP网络实际输出正确的个数,
3)梯度计算。
执行阶段,将训练集的输入喂给网络,执行上述3个任务,第1个任务得到的代价函数值,判断其在训练迭代中是否满足精度要求,从而判断是否要停止训练。在退出BP网络训练之前,完成2个工作:
1)要将训练的结果保存到模型中,由封装的接口saveModel()完成此功能。
2)评估模型在训练集上的识别率,由封装的接口do_eval()完成此功能。
预测接口不放在类BPnn中,其处理过程如图3所示。predict()中有一个输入参数为训练好的模型文件,读取此文件加载训练好的模型,该功能由封装的接口restoreModel()实现。
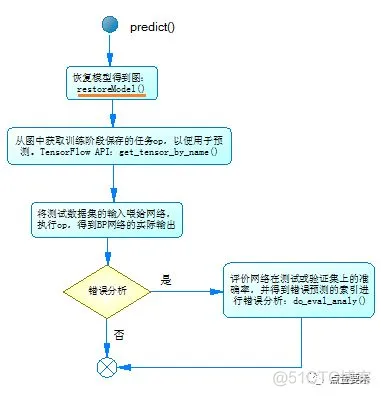
图3 预测接口
加载模型后,将测试/验证集的输入喂给模型,得到实际预测值。如果需要评估模型在测试集/验证集上的识别率,并进行错误分析,由封装的接口do_eval_analy()实现该功能。
二、模型保存于加载
模型保存saveModel()与加载restoreModel(),可以用多种方法实现。在《BP神经网络的原理及其代码实现(三)-python实现》[3]一文中,是将训练好的权值W和偏置b,以及代价函数保存在pickle文件中(参考此文的图22)。在预测阶段,通过读取pickle文件,再加载权值W和偏置b(参考此文的图23),根据测试集的输入,计算得到BP网络的实际预测值。
TensorFlow也提供了模型保存和加载的API:tf.train.Saver().save(),tf.train.Saver().restore()。在《TensorFlow的模型与名称域》[2]一文中,详细讲解了TensorFlow有关模型API的使用方法。
本文提供了一个model模块,对TensorFlow模型API进一步封装。
1、模型保存
如果模型名称为:modelName,模型文件存放父目录为modelParentDirPath,则生成的4个模型文件存放在目录:$modelParentDirPath/$modelName,4个文件名分别是:model-$globalStep.meta,model-$globalStep.index,model-$globalStep.data-000000-of-000001,checkpoint。封装的模型接口model.saveModel()如图4所示。
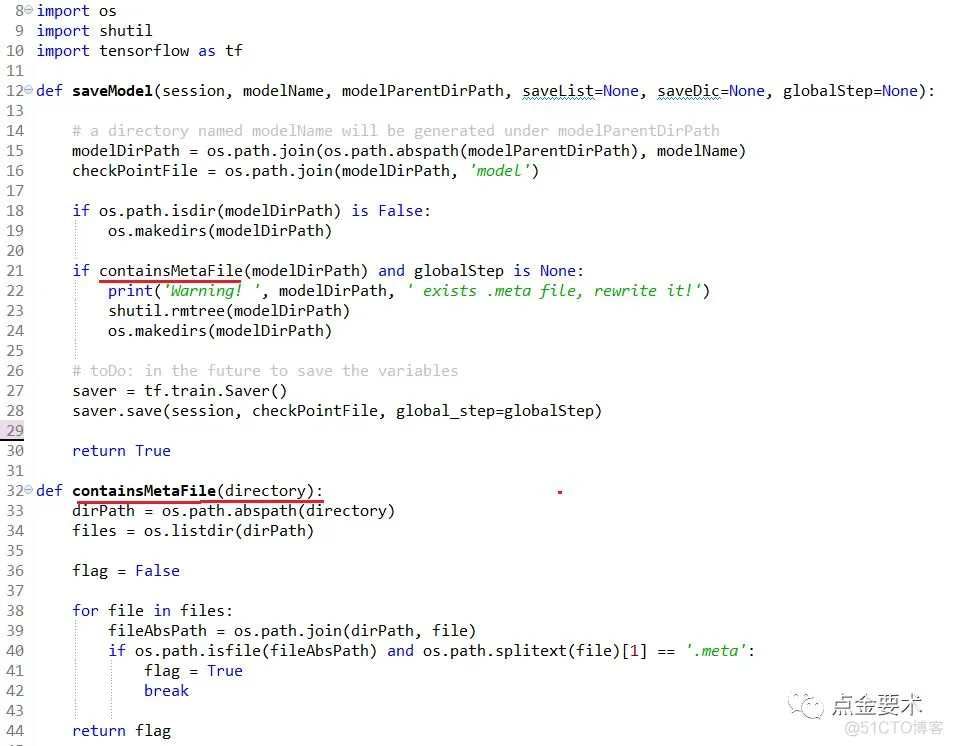
图4 封装的模型保存接口
【注】图4封装的接口,只是针对2种场景:需要将TensorFlow图中所有的张量、变量、操作保存下来的场景;以及每隔几代保存上述模型信息的场景。如果需要保存指定张量,或者每隔多长时间保存模型,读者朋友可以自行尝试更新model.saveModel()接口。
2、模型加载
如果模型名称为:modelName,模型文件存放父目录为modelParentDirPath,则读取目录$modelParentDirPath/$modelName下的最新.meta文件(model-$globalStep.meta),还原模型。封装的model.restoreModel()接口实现如图5所示。其中model.getLatestMetaFile()是获取该模型最新的.meta文件,其实现见图6。
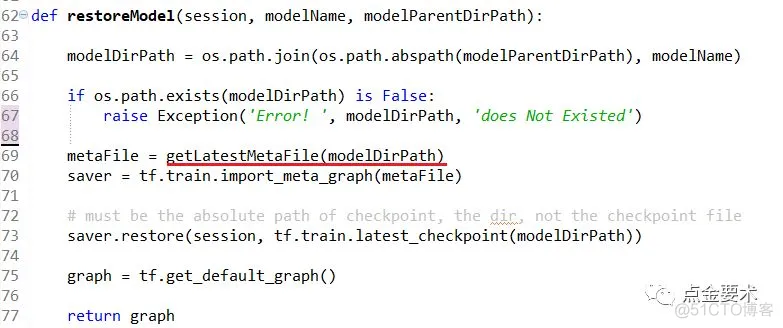
图5 封装的模型加载接口
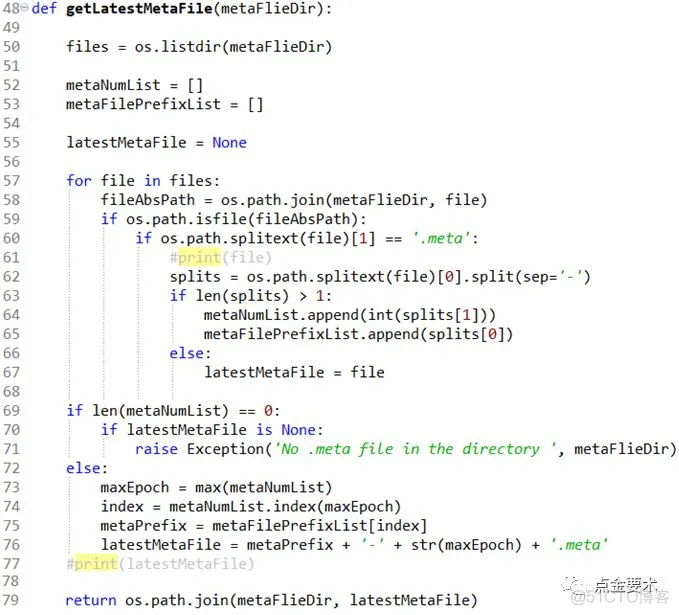
图6 获取模型最新.meta文件的接口
三、源码解释
本节详细解释如何用TensorFlow封装BP神经网络模型。import模块以及类BPnn的部分成员变量见图7。类BPnn中引入了自行实现的4个模块:
1、超参设置接口
在类BPnn的构造方法中设置参数,见图8。第100行的checkSupportedParameter()是parametersCheck模块的方法,其实现见图9。成员变量supportedOptimizerDic存储的是BPnn支持的TensorFlow优化器字典,其定义见图16。
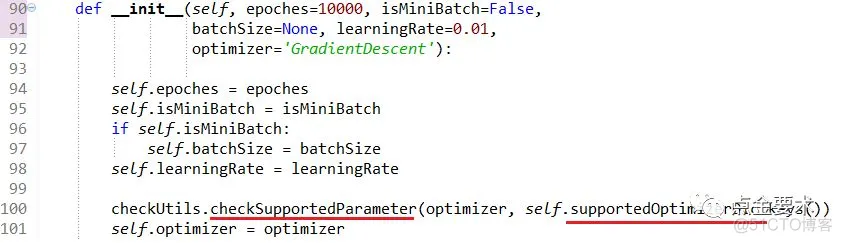
图8超参设置接口
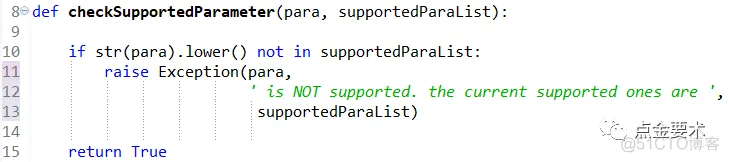
图9 参数校验接口
2、网络结构设置接口
如图10所示,在网络结构设置接口中,有2个参数,其中networkStructureList设置网络的层数与每层激活单元的个数。activationFuncList设置每层的激活函数。

图10 网络结构设置接口
BPnn实例化见图11,第15行、16行设置的BP网络结构为3层结构,输入层(第0层)有784个激活单元,第1层128个激活单元,第2层32个激活单元,第3层1个激活单元,且每层的激活函数都是sigmoid函数。实际上,每层的激活函数可以是不一样的,后续会有一个激活函数的专题文章,介绍不同激活函数的原理与代码实现。
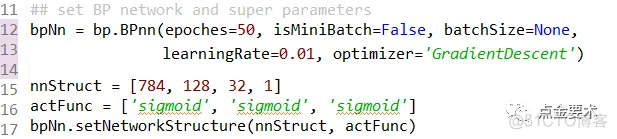
图11 BPnn实例化
【注】在计算神经网络的层数时,输入层不算在总层数内,输入层作为第0层。所以图10代码的107行BP的层数layerNum是networkStructureList长度-1。
3、训练接口
类BPnn的核心接口train(),其处理流程说明参考图2,代码实现参考图12,X为训练集的输入,Y为训练集的输出label。
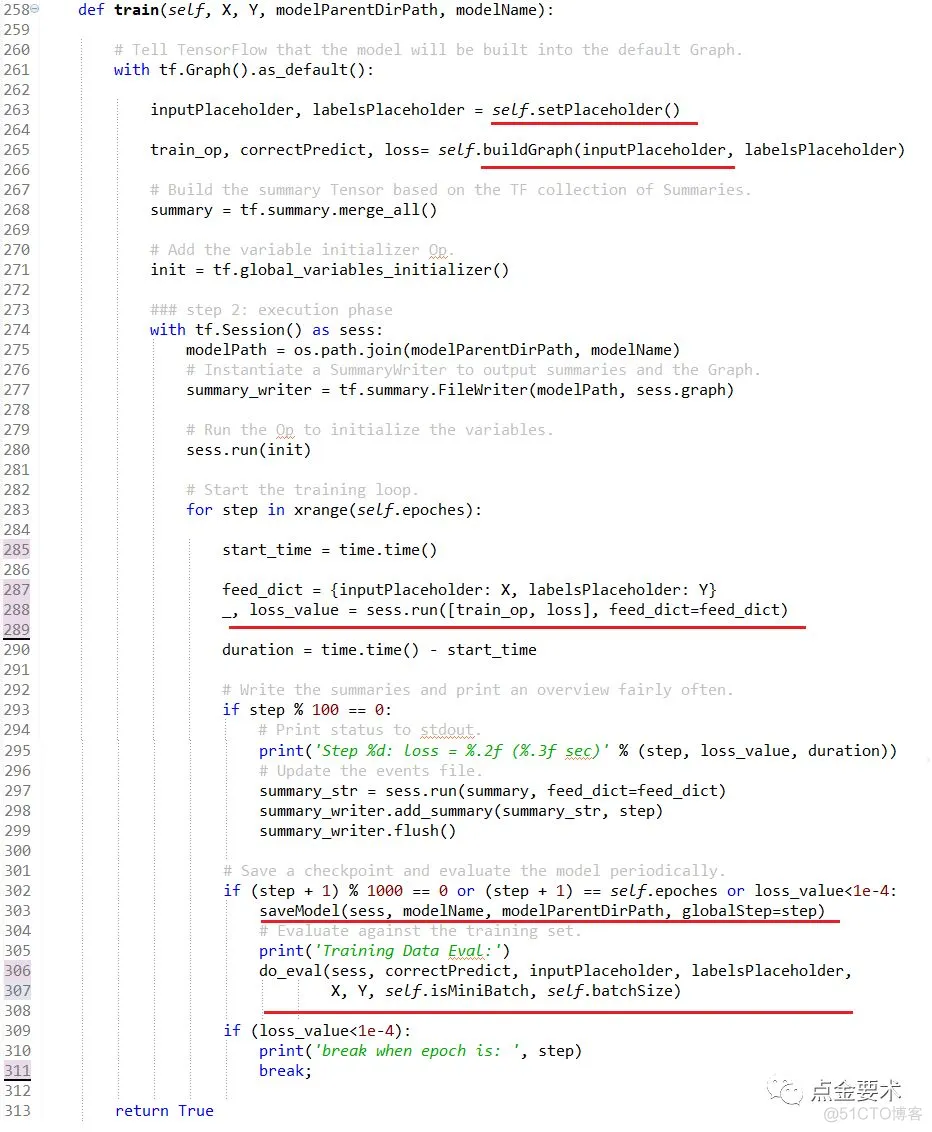
图12 BP模型训练接口
图12中的红色下划线部分是训练接口的5个核心步骤。其中

图13设置输入与输出占位符的接口
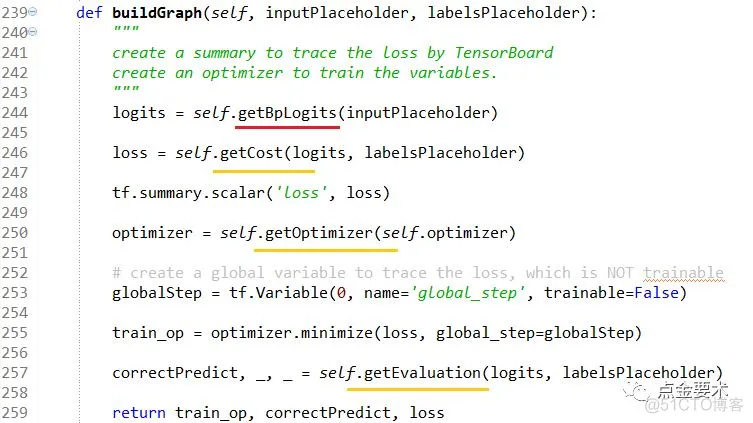
图14 构建BP模型的图
buildGraph()接口中的核心方法是getBpLogits():返回BP网络最后一层的线性输出Z[L]= W[L]A[L-1] +b[L] (注:不是BP网络的实际预测输出A[L]),其代码实现见图15。其他橘色下划线标识的方法是为支持新的超参预留的接口,其代码实现见图16。
【说明】可能会有读者问在buildGraph()中,计算代价函数时(图14的246行),为何用BP网络最后一层的线性输出logits,即Z[L],而不是用BP网络的实际输出A[L]?这是因为为了减少计算量,TensorFlow在计算代价函数时,其API用模型的非线性输出logtis作为输入可以减少一步计算量。有兴趣的读者可以阅读tf.nn.sigmoid_cross_entropy_with_logits()的源码。
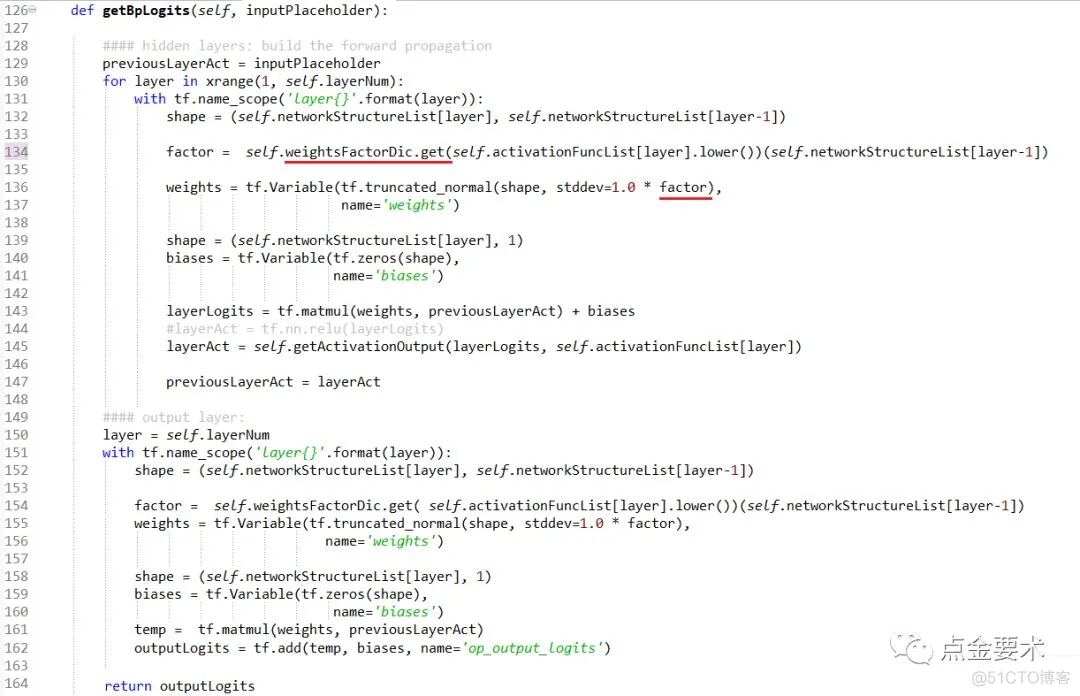
图15 获取BP网络最后一层的线性输出
图15中BPnn成员变量weightsFactorDic存储的是权重因子模块的处理方法,计划在将来专题讲解,不在本文赘述。读者可以将134行,136行的factor换成一个很小的浮点数,如0.01。getBpLogits()方法中用到了TensorFlow的名称域[2]。
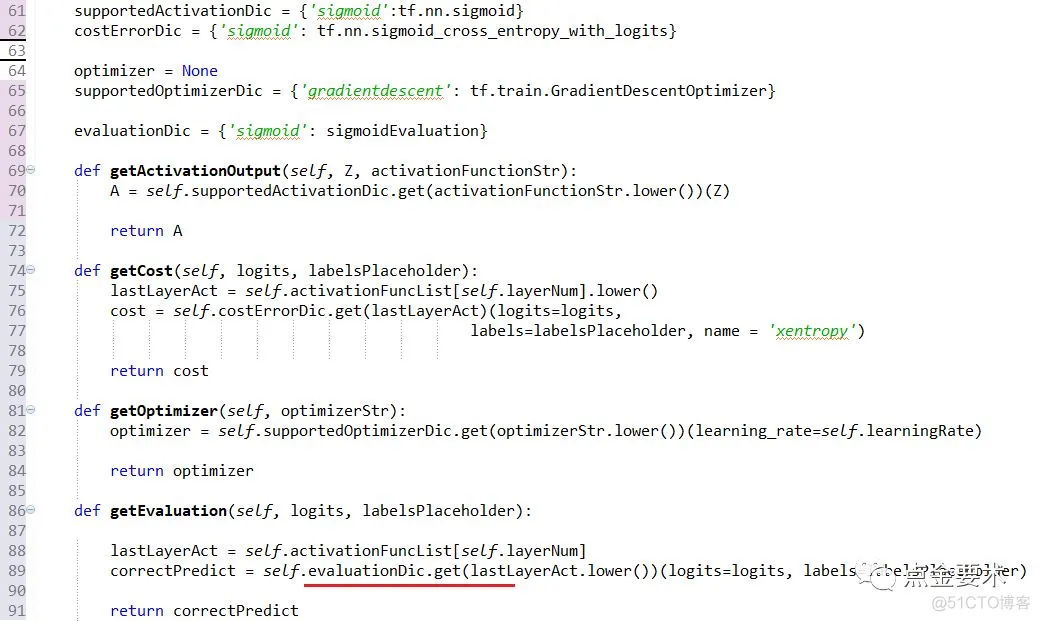
图16 支持新的超参预留的可扩展接口
如果未来支持新的激活函数softmax,图16中第61行增加新的元素supportedActivationDic={‘sigmoid’:tf.nn.sigmoid,‘softmax’:tf.nn.softmax},tf.nn.softmax是TensorFlow实现的softmax函数,读者可以想想costErrorDic应该增加什么元素?同时evaluationDic={‘sigmoid’:sigmoidEvaluation,‘softmax’:softmaxEvaluation},其中softmaxEvaluation是新增的方法,其实现代码与sigmoidEvaluation一样是放在evaluation模块中。
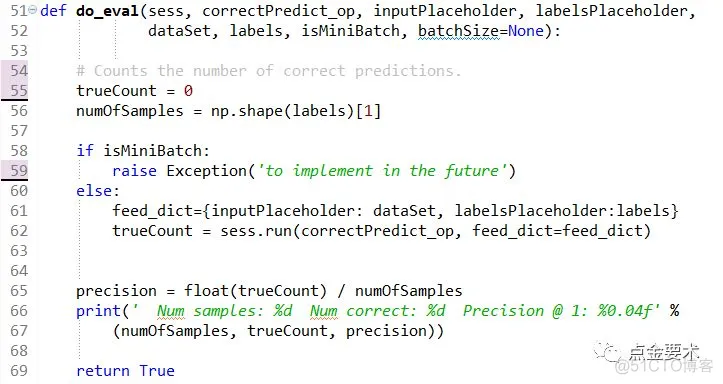
图17 模型预测准确率接口
图17中输入参数corrrectPredict_op是个张量,它是BP网络在某个数据集上预测值准确的个数,它是buildGraph()接口的一个返回值,见图14第257行,由图16的89行可知,corrrectPredict_op实际来自于evaluation模块的sigmoidEvaluation(),见图18。

图18 sigmoidEvaluation接口
4、预测接口
预测接口见图19,首先恢复模型,restoreModel()实现见图5。然后,从模型的图中恢复数据集输入的placeholder变量、数据集输出标识的placeholder变量,以及计算实际预测值正确个数的操作。最后调用do_eval()评价BP网络在测试集、验证集上的预测准确率,do_eval()的实现见图17。
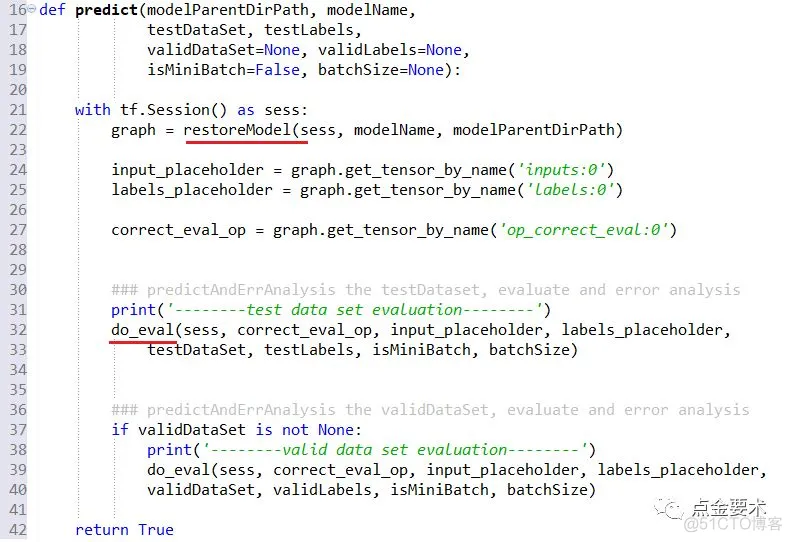
图19 预测接口
图19的predict()接口主要是为了统计训练好的模型在测试集和验证集上的预测准确率,明确模型训练的是否足够健壮,方便后续的误差分析,解决偏差[5]或方差[5]问题。
但是在实际应用中,训练好的模型,要对输入做预测,且没有输出label。此时在predict()接口中应该恢复模型中的什么张量?请读者思考,并尝试更新代码。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















