















































软件

产品


以VGG-16作为特征提取层实现SSD网络的代码,解读SSD网络代码实现的各个细节,从输入参数、默认框的位置匹配、宽高比率、放缩比率、各层默认框的生成、到损失函数计算、整个SSD网络框架代码实现都一一解读。
源代码中对SSD网络需要的6个层大小,默认框大小、最小与最大放缩比率、默认框不同宽高比、步长感受野、并交比等参数给出了相关默认值。代码如下:
img_shape=(300, 300),
num_classes=21,
no_annotation_label=21,
feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],
feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)],
anchor_size_bounds=[0.15, 0.90],
# anchor_size_bounds=[0.20, 0.90],
anchor_sizes=[(21., 45.),
(45., 99.), # 0.18
(99., 153.),
(153., 207.),
(207., 261.),
(261., 315.)],
# anchor_sizes=[(30., 60.),
# (60., 111.),
# (111., 162.),
# (162., 213.),
# (213., 264.),
# (264., 315.)],
anchor_ratios=[[2, .5],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5],
[2, .5]],
anchor_steps=[8, 16, 32, 64, 100, 300],
anchor_offset=0.5,
normalizations=[20, -1, -1, -1, -1, -1],
prior_scaling=[0.1, 0.1, 0.2, 0.2]
img_shape表示输入图像大小为300x300大小
num_classes 表示识别种类是21种
feat_layers表示特征提取使用VGG-16卷积层的4、7、8、9、10、11层
feat_shape表示各个层宽高大小
anchor_sizes表示各个层对于的默认框的宽与高
anchor_ratios表示支持的宽高比例,SSD论文支持的宽高比例[1,2,3,1/2,1/3]具体到各个层可以选择的。
Anchor_steps表示的每个grid的大小,或者是感受野的大小,grid越小的感受野越大,对应只能检测更大的对象,比如最后卷积层11层,只能检测比较大的对象。这个在SSD算法作者的论文有一张图可以说明这个问题: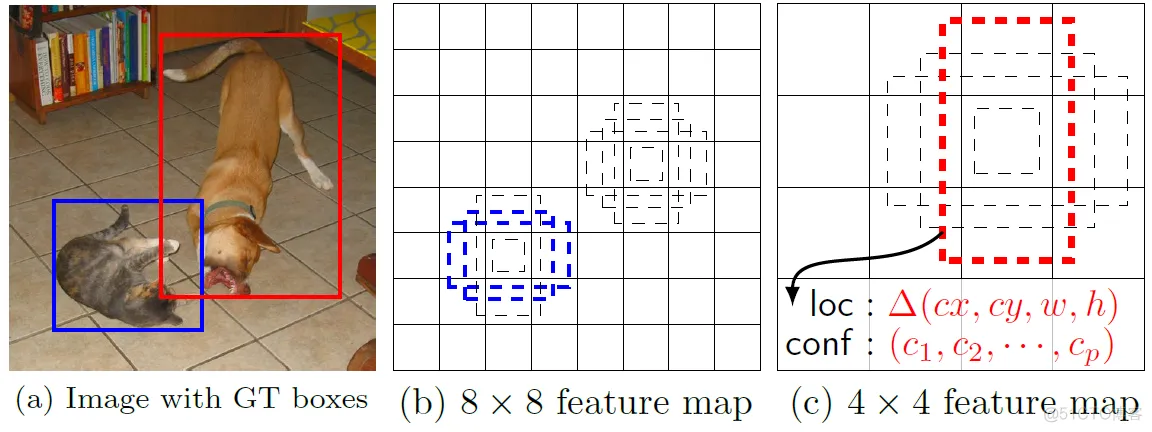
图-1
图a表示输入图像,有两个正确标注框、b表示在grid是8x8的cell上,在每个cell有5个不同比率的默认框,最终计算并交比率,表示蓝色框大于0.5(就是参数anchor_offset=0.5),成功匹配,而对狗在grid是8x8的上面无法匹配,在它的下一层4x4grid上面成功匹配-红色的框。
方法ssd_anchors_all_layers生成所有层所有的默认框,代码实现如下:
def ssd_anchors_all_layers(img_shape,
layers_shape,
anchor_sizes,
anchor_ratios,
anchor_steps,
offset=0.5,
dtype=np.float32):
"""Compute anchor boxes for all feature layers.
"""
layers_anchors = []
for i, s in enumerate(layers_shape):
anchor_bboxes = ssd_anchor_one_layer(img_shape, s,
anchor_sizes[i],
anchor_ratios[i],
anchor_steps[i],
offset=offset, dtype=dtype)
layers_anchors.append(anchor_bboxes)
return layers_anchors
ssd_anchor_one_layer方法实现了生成每一层的默认框,代码如下:
def ssd_anchor_one_layer(img_shape,
feat_shape,
sizes,
ratios,
step,
offset=0.5,
dtype=np.float32):
"""Computer SSD default anchor boxes for one feature layer.
Determine the relative position grid of the centers, and the relative
width and height.
Arguments:
feat_shape: Feature shape, used for computing relative position grids;
size: Absolute reference sizes;
ratios: Ratios to use on these features;
img_shape: Image shape, used for computing height, width relatively to the
former;
offset: Grid offset.
Return:
y, x, h, w: Relative x and y grids, and height and width.
"""
# Compute the position grid: simple way.
# y, x = np.mgrid[0:feat_shape[0], 0:feat_shape[1]]
# y = (y.astype(dtype) + offset) / feat_shape[0]
# x = (x.astype(dtype) + offset) / feat_shape[1]
# Weird SSD-Caffe computation using steps values...
y, x = np.mgrid[0:feat_shape[0], 0:feat_shape[1]]
y = (y.astype(dtype) + offset) * step / img_shape[0]
x = (x.astype(dtype) + offset) * step / img_shape[1]
# Expand dims to support easy broadcasting.
y = np.expand_dims(y, axis=-1)
x = np.expand_dims(x, axis=-1)
# Compute relative height and width.
# Tries to follow the original implementation of SSD for the order.
# 默认支持+支持的宽高比率,得到该层总的支持boxes数目
num_anchors = len(sizes) + len(ratios)
h = np.zeros((num_anchors, ), dtype=dtype)
w = np.zeros((num_anchors, ), dtype=dtype)
# Add first anchor boxes with ratio=1.
h[0] = sizes[0] / img_shape[0]
w[0] = sizes[0] / img_shape[1]
di = 1
# 默认支持的default boxes
if len(sizes) > 1:
h[1] = math.sqrt(sizes[0] * sizes[1]) / img_shape[0]
w[1] = math.sqrt(sizes[0] * sizes[1]) / img_shape[1]
di += 1
# 通过比率支持的anchor boxes
for i, r in enumerate(ratios):
h[i+di] = sizes[0] / img_shape[0] / math.sqrt(r)
w[i+di] = sizes[0] / img_shape[1] * math.sqrt(r)
# 返回该层总的anchor boxes数目(每个boxes的中心位置(y, x), 高度h与宽度x)
return y, x, h, w
对源代码我已经做了中文注解、方便大家阅读,其实这里大家最重要的是要明白计算中心位置是使用原著论文中计算default box的中心位置的公式,其次就是生成default box。
对于每个default box如果最终的并交比超过0.5以上的进行匹配预测会生成(C+4)个值,其中C就是各个种类的得分向量,多少与种类num_classes相同、另外4个值位置信息,这里不会预测box的中心位置与宽高,而是预测它们的offset或者delta。可以参看图-1。最终计算的损失分为两个部分,分别是位置信息损失与预测种类损失。对于grid是MXN大小的卷积层来说,假设有K个default box,最终输出的预测数据为(C+4)kM*N。多个box预测层的代码实现如下:
def ssd_multibox_layer(inputs,
num_classes,
sizes,
ratios=[1],
normalization=-1,
bn_normalization=False):
"""Construct a multibox layer, return a class and localization predictions.
"""
net = inputs
if normalization > 0:
net = custom_layers.l2_normalization(net, scaling=True)
# Number of anchors.
num_anchors = len(sizes) + len(ratios)
# Location.
num_loc_pred = num_anchors * 4
loc_pred = slim.conv2d(net, num_loc_pred, [3, 3], activation_fn=None,
scope='conv_loc')
loc_pred = custom_layers.channel_to_last(loc_pred)
loc_pred = tf.reshape(loc_pred,
tensor_shape(loc_pred, 4)[:-1]+[num_anchors, 4])
# Class prediction.
num_cls_pred = num_anchors * num_classes
cls_pred = slim.conv2d(net, num_cls_pred, [3, 3], activation_fn=None,
scope='conv_cls')
cls_pred = custom_layers.channel_to_last(cls_pred)
cls_pred = tf.reshape(cls_pred,
tensor_shape(cls_pred, 4)[:-1]+[num_anchors, num_classes])
return cls_pred, loc_pred
损失计算的代码如下:
def ssd_losses(logits, localisations,
gclasses, glocalisations, gscores,
match_threshold=0.5,
negative_ratio=3.,
alpha=1.,
label_smoothing=0.,
device='/cpu:0',
scope=None):
with tf.name_scope(scope, 'ssd_losses'):
lshape = tfe.get_shape(logits[0], 5)
num_classes = lshape[-1]
batch_size = lshape[0]
# Flatten out all vectors!
flogits = []
fgclasses = []
fgscores = []
flocalisations = []
fglocalisations = []
for i in range(len(logits)):
flogits.append(tf.reshape(logits[i], [-1, num_classes]))
fgclasses.append(tf.reshape(gclasses[i], [-1]))
fgscores.append(tf.reshape(gscores[i], [-1]))
flocalisations.append(tf.reshape(localisations[i], [-1, 4]))
fglocalisations.append(tf.reshape(glocalisations[i], [-1, 4]))
# And concat the crap!
logits = tf.concat(flogits, axis=0)
gclasses = tf.concat(fgclasses, axis=0)
gscores = tf.concat(fgscores, axis=0)
localisations = tf.concat(flocalisations, axis=0)
glocalisations = tf.concat(fglocalisations, axis=0)
dtype = logits.dtype
# Compute positive matching mask...
pmask = gscores > match_threshold
fpmask = tf.cast(pmask, dtype)
n_positives = tf.reduce_sum(fpmask)
# Hard negative mining...
no_classes = tf.cast(pmask, tf.int32)
predictions = slim.softmax(logits)
nmask = tf.logical_and(tf.logical_not(pmask),
gscores > -0.5)
fnmask = tf.cast(nmask, dtype)
nvalues = tf.where(nmask,
predictions[:, 0],
1. - fnmask)
nvalues_flat = tf.reshape(nvalues, [-1])
# Number of negative entries to select.
max_neg_entries = tf.cast(tf.reduce_sum(fnmask), tf.int32)
n_neg = tf.cast(negative_ratio * n_positives, tf.int32) + batch_size
n_neg = tf.minimum(n_neg, max_neg_entries)
val, idxes = tf.nn.top_k(-nvalues_flat, k=n_neg)
max_hard_pred = -val[-1]
# Final negative mask.
nmask = tf.logical_and(nmask, nvalues < max_hard_pred)
fnmask = tf.cast(nmask, dtype)
# Add cross-entropy loss.
with tf.name_scope('cross_entropy_pos'):
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=gclasses)
loss = tf.div(tf.reduce_sum(loss * fpmask), batch_size, name='value')
tf.losses.add_loss(loss)
with tf.name_scope('cross_entropy_neg'):
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=no_classes)
loss = tf.div(tf.reduce_sum(loss * fnmask), batch_size, name='value')
tf.losses.add_loss(loss)
# Add localization loss: smooth L1, L2, ...
with tf.name_scope('localization'):
# Weights Tensor: positive mask + random negative.
weights = tf.expand_dims(alpha * fpmask, axis=-1)
loss = custom_layers.abs_smooth(localisations - glocalisations)
loss = tf.div(tf.reduce_sum(loss * weights), batch_size, name='value')
tf.losses.add_loss(loss)
最终的SSD网络构建代码,默认是基于VGG-16,输入图像大小为300x300。其符合原著SSD论文中作者给出的SSD网络模型图: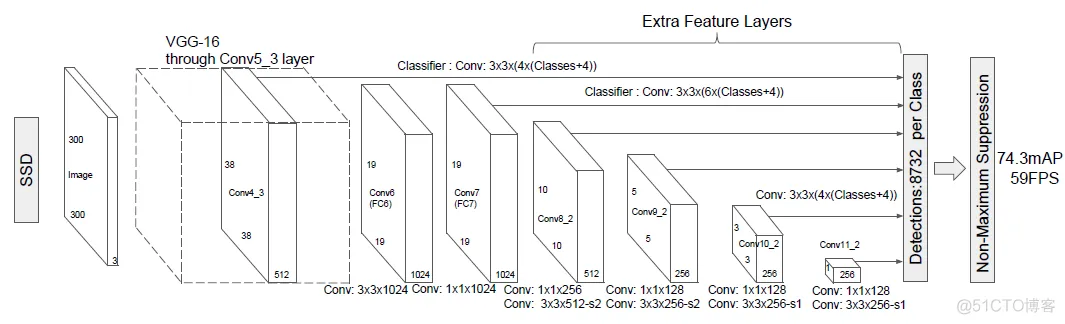
代码如下:
def ssd_net(inputs,
num_classes=SSDNet.default_params.num_classes,
feat_layers=SSDNet.default_params.feat_layers,
anchor_sizes=SSDNet.default_params.anchor_sizes,
anchor_ratios=SSDNet.default_params.anchor_ratios,
normalizations=SSDNet.default_params.normalizations,
is_training=True,
dropout_keep_prob=0.5,
prediction_fn=slim.softmax,
reuse=None,
scope='ssd_300_vgg'):
"""SSD net definition.
"""
# if data_format == 'NCHW':
# inputs = tf.transpose(inputs, perm=(0, 3, 1, 2))
# End_points collect relevant activations for external use.
end_points = {}
with tf.variable_scope(scope, 'ssd_300_vgg', [inputs], reuse=reuse):
# Original VGG-16 blocks.
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
end_points['block1'] = net
net = slim.max_pool2d(net, [2, 2], scope='pool1')
# Block 2.
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
end_points['block2'] = net
net = slim.max_pool2d(net, [2, 2], scope='pool2')
# Block 3.
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
end_points['block3'] = net
net = slim.max_pool2d(net, [2, 2], scope='pool3')
# Block 4.
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
end_points['block4'] = net
net = slim.max_pool2d(net, [2, 2], scope='pool4')
# Block 5.
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
end_points['block5'] = net
net = slim.max_pool2d(net, [3, 3], stride=1, scope='pool5')
# Additional SSD blocks.
# Block 6: let's dilate the hell out of it!
net = slim.conv2d(net, 1024, [3, 3], rate=6, scope='conv6')
end_points['block6'] = net
net = tf.layers.dropout(net, rate=dropout_keep_prob, training=is_training)
# Block 7: 1x1 conv. Because the fuck.
net = slim.conv2d(net, 1024, [1, 1], scope='conv7')
end_points['block7'] = net
net = tf.layers.dropout(net, rate=dropout_keep_prob, training=is_training)
# Block 8/9/10/11: 1x1 and 3x3 convolutions stride 2 (except lasts).
end_point = 'block8'
with tf.variable_scope(end_point):
net = slim.conv2d(net, 256, [1, 1], scope='conv1x1')
net = custom_layers.pad2d(net, pad=(1, 1))
net = slim.conv2d(net, 512, [3, 3], stride=2, scope='conv3x3', padding='VALID')
end_points[end_point] = net
end_point = 'block9'
with tf.variable_scope(end_point):
net = slim.conv2d(net, 128, [1, 1], scope='conv1x1')
net = custom_layers.pad2d(net, pad=(1, 1))
net = slim.conv2d(net, 256, [3, 3], stride=2, scope='conv3x3', padding='VALID')
end_points[end_point] = net
end_point = 'block10'
with tf.variable_scope(end_point):
net = slim.conv2d(net, 128, [1, 1], scope='conv1x1')
net = slim.conv2d(net, 256, [3, 3], scope='conv3x3', padding='VALID')
end_points[end_point] = net
end_point = 'block11'
with tf.variable_scope(end_point):
net = slim.conv2d(net, 128, [1, 1], scope='conv1x1')
net = slim.conv2d(net, 256, [3, 3], scope='conv3x3', padding='VALID')
end_points[end_point] = net
# Prediction and localisations layers.
predictions = []
logits = []
localisations = []
for i, layer in enumerate(feat_layers):
with tf.variable_scope(layer + '_box'):
p, l = ssd_multibox_layer(end_points[layer],
num_classes,
anchor_sizes[i],
anchor_ratios[i],
normalizations[i])
predictions.append(prediction_fn(p))
logits.append(p)
localisations.append(l)
return predictions, localisations, logits, end_points
ssd_net.default_image_size = 300
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















