















































软件

产品


Tensorflow是一个通过计算图的形式来表述计算的编程系统,计算图也叫数据流图,可以把计算图看做是一种有向图,Tensorflow中的每一个节点都是计算图上的一个Tensor张量,而节点之间的边描述了计算之间的依赖关系(定义时)和数学操作(运算时)。
Tensorflow的关键优势并不在于提供多少的深度神经网络模型,函数或方法,关键的问题是很多神经网络模型从理论上存在,但在实践中,并没有关键的算力去实现它们。
Tensorflow通过Graph和Session的设定,对神经网络模型进行了三重解构,第一层解构是将数据与神经网络模型进行了分离,所以要先设计神经网络模型,再导入数据进行训练,从而得出神经网络节点参数。第二层解构是通Graph将神经网络模型进行结构化分区,通过结构化分区把复杂的神经网络进行了解构,研究人员可以按Graph的结果对特定的神经网络模型组成部分进行局部微调,通过局部微调实现全局复杂神经网络的组建,第三层次的解构就是通过Session的设计,将神经网络的运算拆解到相关的算力中心,这就导致大规模的算力组合训练复杂的人工神经网络模型成为了可能性。
这三点:数据与网络风离,复杂网络模型分区解构,以及执行训练过程中的算力调配,可以将已经发展了60多年的人工神经网络模型的潜力最大化的实现出来,这就是一个划时代的发明创造!
深度学习模型的训练是一个迭代的过程,在每一轮迭代过程中,前向传播算法会根据当前参数的取值,计算出在一小部分训练数据上的预测值,然后反向传播算法,再根据损失函数计算参数的梯度并且更新参数。
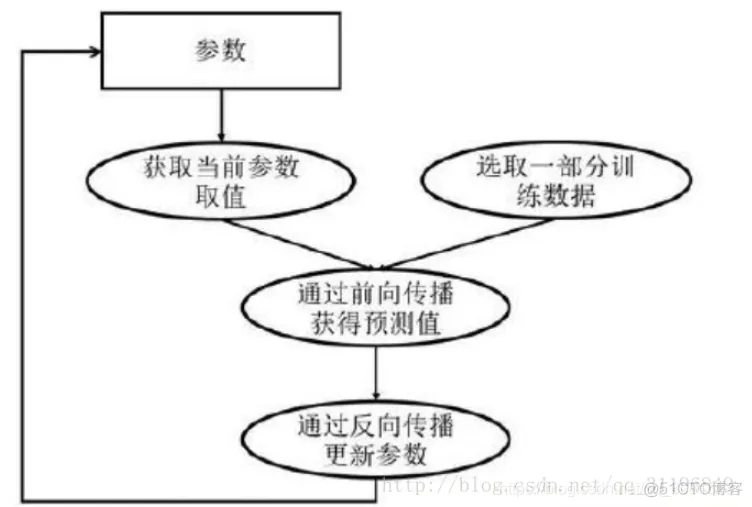
训练方法
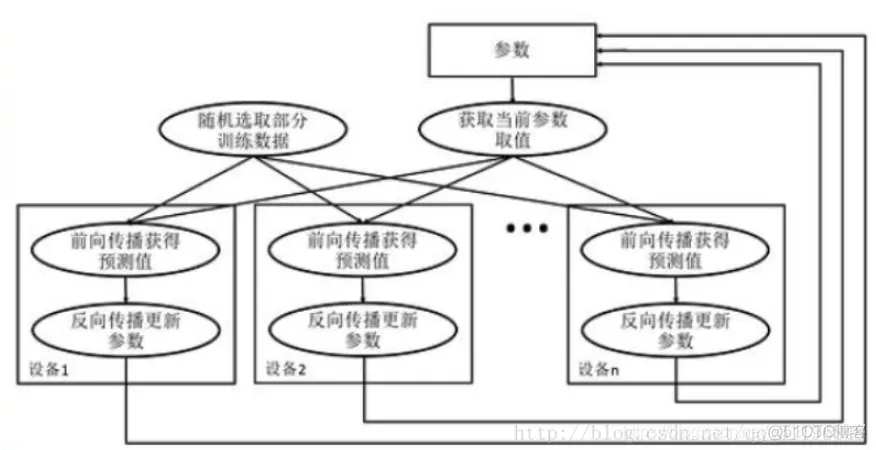
异步模式训练流程图如左图:
* 在每一轮迭代时,不同设备会读取参数最新的取值
* 因为设备不同,读取参数取值时间不一样,所以得到的值也可能不一样
* 根据当前参数的取值,和随机获取的一小部分训练数据,不同设备各自运行反向传播的过程,并且独立地更新参数
* 可以认为异步模式,就是单机模式复制了多份,每一份使用不同的训练数据进行训练。
* 在异步模式下,不同设备之前是完全独立的
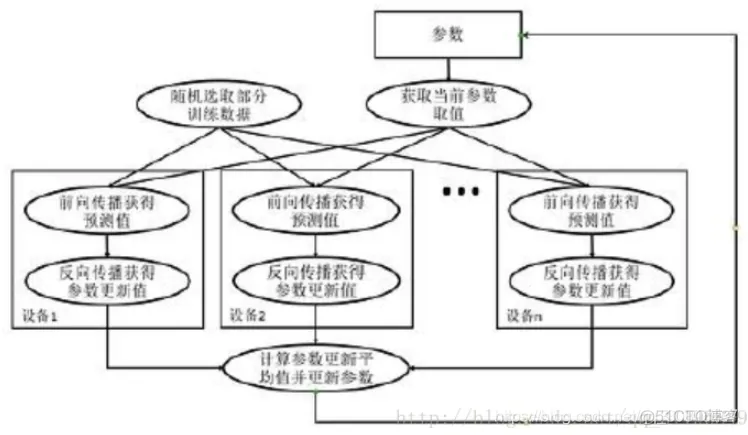
同步模式训练流程图如右图:
* 图中在迭代每一轮时,不同设备统一读取当前参数的取值,并随机获取一小部分数据
* 然后在不同设备上运行反向传播过程得到在各自训练数据上的参数的梯度 ,虽然所有设备使用的参数是一致的,但是因为训练数据不同,所以得到的参数的梯度可能不一样
* 当所有设备完成反向传播的计算之后,需要计算出不同设备上参数梯度的平均值
* 最后再根据平均值对参数进行更新
在同步更新的时候, 每次梯度更新,要等所有分发出去的数据计算完成后,返回回来结果之后,把梯度累加算了均值之后,再更新参数。 这样的好处是loss的下降比较稳定, 但是这个的坏处也很明显, 处理的速度取决于最慢的那个分片计算的时间。
在异步更新的时候, 所有的计算节点,各自算自己的, 更新参数也是自己更新自己计算的结果, 这样的优点就是计算速度快, 计算资源能得到充分利用,但是缺点是loss的下降不稳定, 抖动大。
在数据量小的情况下, 各个节点的计算能力比较均衡的情况下, 推荐使用同步模式;数据量很大,各个机器的计算性能掺差不齐的情况下,推荐使用异步的方式。
手写DNN的计算过程:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
#使用numpy生成200个随机点
x_data=np.linspace(-0.5,0.5,200)[:,np.newaxis]
noise=np.random.normal(0,0.02,x_data.shape)
y_data=np.square(x_data)+noise
#定义两个placeholder存放输入数据
x=tf.placeholder(tf.float32,[None,1])
y=tf.placeholder(tf.float32,[None,1])
#定义神经网络中间层
Weights_L1=tf.Variable(tf.random_normal([1,10]))
biases_L1=tf.Variable(tf.zeros([1,10])) #加入偏置项
Wx_plus_b_L1=tf.matmul(x,Weights_L1)+biases_L1
L1=tf.nn.tanh(Wx_plus_b_L1) #加入激活函数
#定义神经网络输出层
Weights_L2=tf.Variable(tf.random_normal([10,1]))
biases_L2=tf.Variable(tf.zeros([1,1])) #加入偏置项
Wx_plus_b_L2=tf.matmul(L1,Weights_L2)+biases_L2
prediction=tf.nn.tanh(Wx_plus_b_L2) #加入激活函数
#定义损失函数
loss=tf.reduce_mean(tf.square(y-prediction))
#定义反向传播算法(使用梯度下降算法训练)
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
with tf.Session() as sess:
#变量初始化
sess.run(tf.global_variables_initializer())
#训练2000次
for i in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
#获得预测值
prediction_value=sess.run(prediction,feed_dict={x:x_data})
#画图
plt.figure()
plt.scatter(x_data,y_data) #散点是真实值
plt.plot(x_data,prediction_value,'r-',lw=5) #曲线是预测值
plt.show()
写一个DNN实现手写数字识别:
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300 # reused
n_hidden2 = 50 # reused
n_hidden3 = 50 # reused
n_hidden4 = 20 # new!
n_outputs = 10 # new!
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
# reused
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
# reused
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3")
# reused
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4")
# new!
logits = tf.layers.dense(hidden4, n_outputs, name="outputs")
# new!
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
#创建一个restore_saver来恢复预训练模型(为其提供要恢复的变量列表,否则它会抱怨图形不匹配)
reuse_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope="hidden[123]") # regular expression
restore_saver = tf.train.Saver(reuse_vars) # to restore layers 1-3
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
init.run()
restore_saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs):
# not shown in the book
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
# not shown
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
# not shown
accuracy_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
# not shown
print(epoch, "Validation accuracy:", accuracy_val)
# not shown
save_path = saver.save(sess, "./my_new_model_final.ckpt")
写一个CNN实现手写数字识别:
import tensorflow as tf
import numpy as np
height=28
width=28
channels = 1
n_inputs = height * width
conv1_fmaps = 32 #卷积核个数
conv1_ksize = 3 #卷积核宽高
conv1_stride = 1 #步幅
conv1_pad = "SAME"
conv2_fmaps = 64
conv2_ksize = 3
conv2_stride = 2
conv2_pad = "SAME"
pool3_fmaps = 64
n_fc1 = 64
n_outputs = 10
reset_graph()
with tf.name_scope("inputs"):
X=tf.placeholder(tf.float32,shape=[None,n_inputs],name="X")
X_reshaped=tf.reshape(X,shape=[-1,height,width,channels])
y=tf.placeholder(tf.int32,shape=[None],name="y")
conv1 = tf.layers.conv2d(X_reshaped, filters=conv1_fmaps, kernel_size=conv1_ksize,
strides=conv1_stride, padding=conv1_pad,
activation=tf.nn.relu, name="conv1")
conv2 = tf.layers.conv2d(conv1, filters=conv2_fmaps, kernel_size=conv2_ksize,
strides=conv2_stride, padding=conv2_pad,
activation=tf.nn.relu, name="conv2")
with tf.name_scope("pool3"):
pool3=tf.nn.max_pool(conv2,ksize=[1,2,2,1],strides=[1,2,2,1],padding="VALID")
pool3_flat=tf.reshape(pool3,shape=[-1,pool3_fmaps*7*7])
#卷积核个数*7*7,池化之后要把二维图像转化为一维列向量
with tf.name_scope("fc1"):
fc1=tf.layers.dense(pool3_flat,n_fc1,activation=tf.nn.relu,name="fc1")
#全链接,每个特征图的一维列向量均与64个神经元相连
with tf.name_scope("output"):
logits=tf.layers.dense(fc1,n_outputs,name="output")
Y_proba=tf.nn.softmax(logits,name="Y_proba")
with tf.name_scope("train"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y)
#损失函数:计算交叉熵
loss = tf.reduce_mean(xentropy) #平均交叉熵
optimizer = tf.train.AdamOptimizer()
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
with tf.name_scope("init_and_save"):
init = tf.global_variables_initializer()
saver = tf.train.Saver()
def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:]
n_epochs = 10
batch_size = 100
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test})
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















