















































软件

产品


TensorFlow是什么
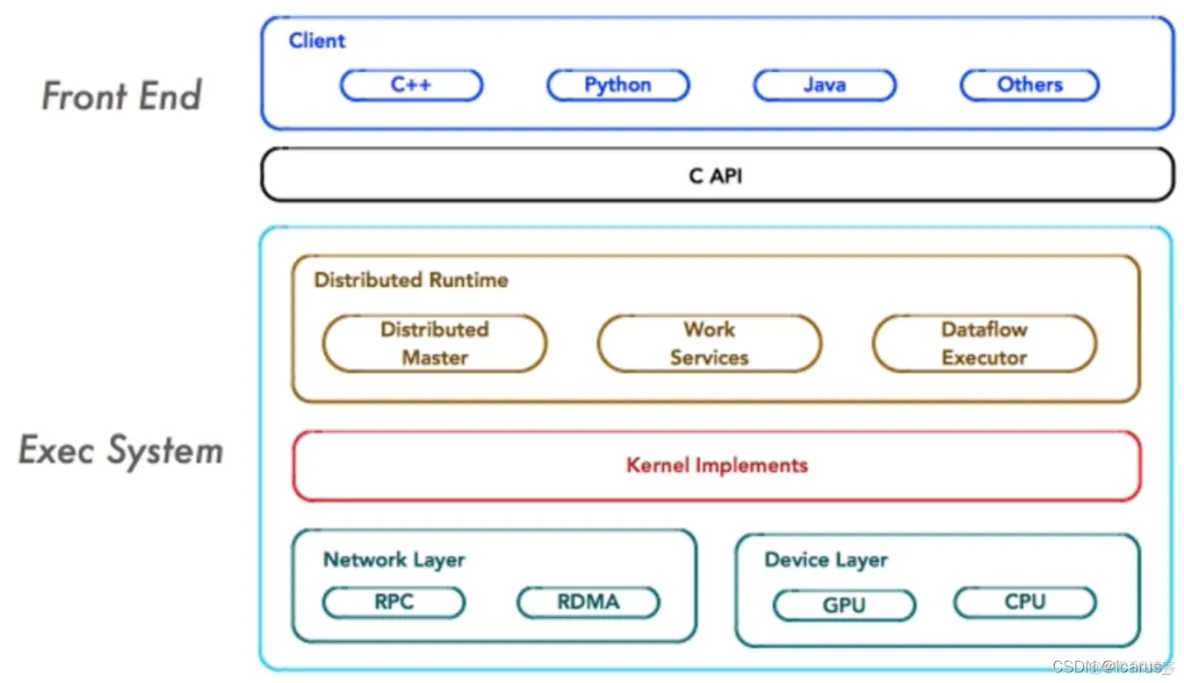
从图中可以看到有三大部分组成,第一部分是一个前端框架,Front End。第二部分,就是中间的这个capi。第三部分是一个后端的Exec System执行的一个操作系统。
前端系统:它主要是负责提供TensorFlow的一个编程模型,构造计算图和管理session的周期。
什么是TensorFlow的编程模型呢?实际上是我们所训练的模型 。构造计算图,也就是说,我们里面有大量的输入输出,图的计算,图的构造。一些函数,一些激活,一些神经网络这些构造图。还有管理session周期。一个TensorFlow的模型的训练,或者说任何的一个任务的启动,我们都是要通过session,就是会话进行启动的。我们可以把前端框架理解为给TensorFlow底层用户暴露出来的一个api接口,那么开发者可以使用python,Java,c++等多种开发语言。后端的系统中所提供的api基础上根据自身要求,来设计和开发自己所需要的模型,并将模型进行训练。
后端系统:提供运行时环境,负责执行计算图。
后端系统的设计和实现可以进一步分解为 4 层。
TensorFlow中的一个非常基本的一个要素,对神经网络高维度的表达方式。
张量(Tensor)在TensorFlow中,张量的维度被描述为“阶”,但是,张量的阶和矩阵的阶并不是同一个概念,张量的阶,是张量维度的一个数量的描述。
x=3零阶张量 (纯量)
v=[1.1,2.2,3.3] 一阶张量(向量)
t=[[1,2,3],[4,5,6],[7,8,9]] 二阶张量(矩阵)379373142
m=[[[2],[4], [6]],[[8],[10],[12]],[[14],[16],[18]]] 三阶张量(立方体)
一个TensorFlow在运行的过程中,它会有需要进行计算,计算中会有很多节点,很多操作,这些节点和操作就组成了一个图。代表模型的数据流,由多个ops(操作即节点)和tensor(数据流即边)组成,算法都会表示成计算图(数据流图),可看作是有向图,张量就是通过各种操作在有向图中流动。
无论是在TensorFlow也好,或者是来任何框架,任何语言中。都有这么一个会话的概念,会话实际量就是管理着一个模型或者一个函数或者说一个操作开始到结尾整个的这么一场流程。
在TensorFlow中,要想启动一个图的前提是要先创建一个会话(Session) -TensorFlow的所有对图的操作, 都必须放在会话中进行。
import tensorfiow as tf
Hello=tf.constant('Hello Tensorflow!')
sess = tf.Session()
print(sess.run(Hello))
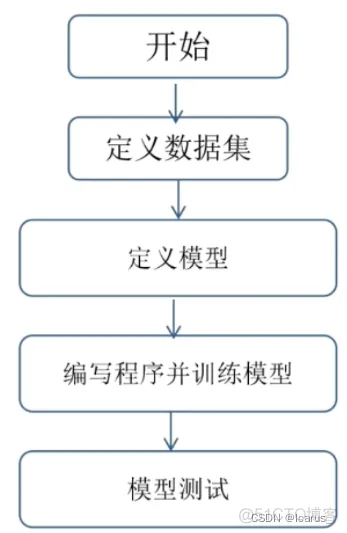
TensorFlow是如何进行模型训练的?首先,我们要定义数据集,无论是图像的一个数据训练也好,还是文本的训练,或者说一些语音,一些视频的训练等等。
第一步要做的就是定义数据集,一般来讲有两种方式,第一种方式呢是我们使用现成的数据集。
第二步对定义模型。有了数据集之后。那我们会先对这个数据进行一个处理,处理成我们所想要的所需要的这么一个数理集。
第三步就是定义模型,比如说这个模型的输入是什么,输出是什么?输入和输出之间。我这个模型是如何运算的,是如何进行处理,比如说图像的话,我可能需要用卷积用池化做一些操作。 训练这个模型的之前,我们就要把这个模型的定义好。
第四步就可以编写程序。那么这个模型我们要去练多少轮,用多少数据。训练数据是多少?测试数据是多少?训练数据是什么样。数据什么样的,一般来讲,我们训练数据和测试数据是一个互斥关系,也就是说。训练数据一般不会包含测试数据的内容,测试数据集中呢,也不会包含训练数据内容。
第五步模型训练好之后。进的一个测试。测试数据集局,或者说用一些正常的或者我们最终真要使用的这个数据进行一个测试来验证一下我们这个模型准确率有多少。效果如何等等。
训练模型这个过程中,我们有几点要注意的。
注意数据集。训练图像和文本,它的数据集是不同的,我们要保证第一训练集和测试集要给它区分开,第二。训练集尽可能要大,一般是先用大批量的数据来进行训练。比如说。我训练一个文本处理任务,那几十条或者说100多条要进行训练,这个时候训练给可能不是很堵准,因为深度学习实际是让计算机自己学习一个规律,找到他的特征。我们给他的训练集比较少的时候呢,他学习到的特征可能不是特别明显,特学习到的特征不是特别多,我们用一个新的测试集进行测试的时候,会导致这个测试的不准确。我们要注意的就是说,我们这个训练集要尽可能比较大,或者说尽可能力要一定得统一性,也可以说是有一定的多样化,但是要有比较大批量的数据才能给他进行训练。
另外,我们来编写模型和训练模型的时候呢,我们也要去调里面的一些参数。比如说训练多少轮,并不说我训练的轮次多越好。有的人说我这数据量很多,那么我一次性给他训练个一百万,200万轮,训练完了之后我们拿测试集来测,发现结果100%。很好,是我想要的,但是呢,跑到真实环境中就会发现为什么真实环境准确率不高呢。
训练的轮次很多,这导致它的拟和程度很强。这个时候,我们把这个训练称之为过你和。 就是用我们理想化的数据进行训练。这个理想化的数据进行验证。当我们用普通化的或者一般形式的数据区验证去进行测试的时候,他的效果就不是很好。这个就是过拟合的概念。
训练轮次少就是一个欠拟合的概念。整个就是反着的,在TensorFlow的这个模型训练里,我们主要就是要注意这几点。一个是数据集,第二个是数据的一个大小,种类,还有结构。还有就是这个模型训练的训练轮次,还有一点在模型训练过程中,比如说我们训练到一半,或者说训练出来的结果发现他这个损失不下降。 因为我们的训面有一个loss就么一个参数,它不下降,这或者说下降的非常快,或者说下降非常慢或者下降到一半又升上去了,这个时候就要去找损失函数是否用的对,是不会要换一种优化系,所以说这个是在深度学习过程中叫做参数调优过程,TensorFlow的训练,或者任和深度学习的训练,他最主要的一个是对数命级的训练,第二个是对模型的参数的一个优化,一个调优,使它能够达到一个最理理想的,或者说我们最需要的这么一个状态,整个这么一套就是TensorFlow基本的原理和基本的一个训练模型。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















