















































软件

产品


1.算法描述
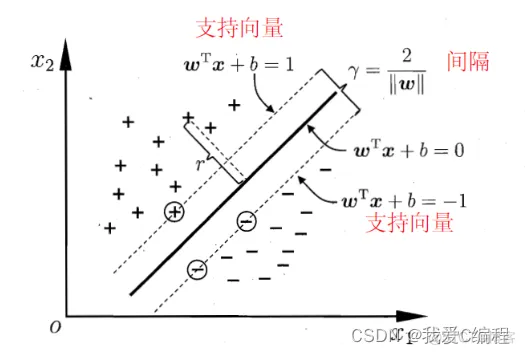
支持向量机(support vector machines, SVM)是二分类算法,所谓二分类即把具有多个特性(属性)的数据分为两类,目前主流机器学习算法中,神经网络等其他机器学习模型已经能很好完成二分类、多分类,学习和研究SVM,理解SVM背后丰富算法知识,对以后研究其他算法大有裨益;在实现SVM过程中,会综合利用之前介绍的一维搜索、KKT条件、惩罚函数等相关知识。本篇首先通过详解SVM原理,后介绍如何利用python从零实现SVM算法。
实例中样本明显的分为两类,黑色实心点不妨为类别一,空心圆点可命名为类别二,在实际应用中会把类别数值化,比如类别一用1表示,类别二用-1表示,称数值化后的类别为标签。每个类别分别对应于标签1、还是-1表示没有硬性规定,可以根据自己喜好即可,需要注意的是,由于SVM算法标签也会参与数学运算,这里不能把类别标签设为0。
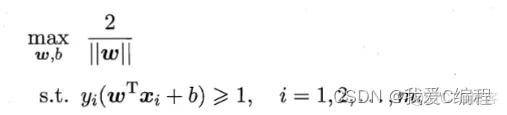
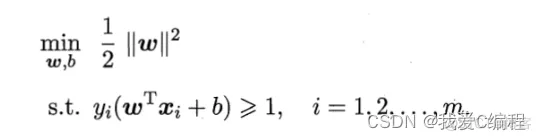
线性核:
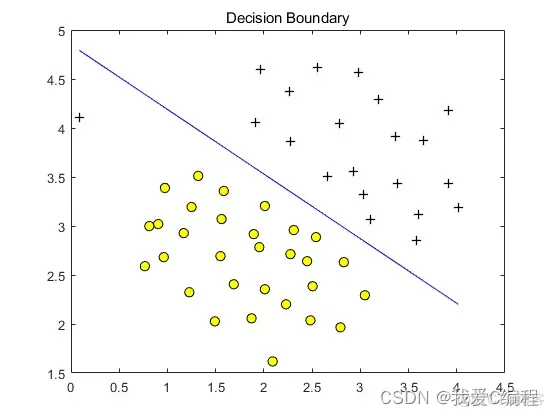
主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的,其参数少速度快,对于线性可分数据,其分类效果很理想
通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的
优点:方案首选、简单、可解释性强:可以轻易知道哪些feature是重要的
缺点:只能解决线性可分的问题
高斯核:
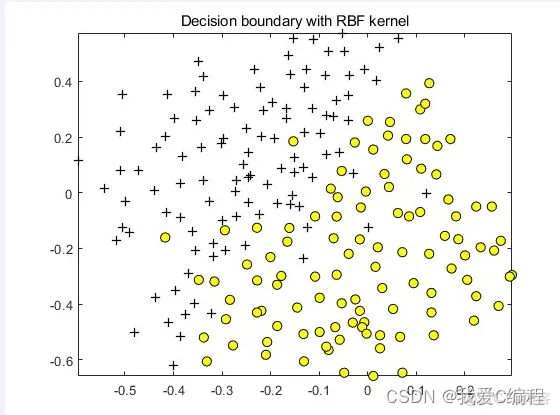
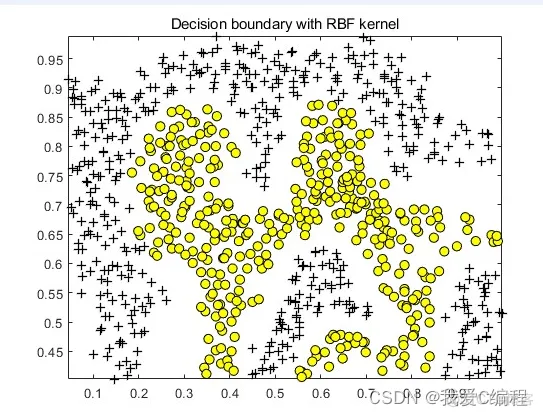
通过调控参数,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。
如果σ \sigmaσ选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;
如果σ \sigmaσ选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。
优点:可以映射到无限维、决策边界更为多维、只有一个参数
缺点:可解释性差、计算速度慢、容易过拟合
多项式核
多项式核函数可以实现将低维的输入空间映射到高纬的特征空间,
但是多项式核函数的参数多
当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算。
优点:可解决非线性问题、主观设置
缺点:多参数选择、计算量大
sigmoid核
采用sigmoid核函数,支持向量机实现的就是只包含一个隐层,激活函数为 Sigmoid 函数的神经网络。
应用SVM方法,隐含层节点数目(它确定神经网络的结构)、隐含层节点对输入节点的权值都是在设计(训练)的过程中自动确定的。
而且支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最小值,也保证了它对于未知样本的良好泛化能力而不会出现过学习现象。
如图, 输入层->隐藏层之间的权重是每个支撑向量,隐藏层的计算结果是支撑向量和输入向量的内积,隐藏层->输出层之间的权重是支撑向量对应的
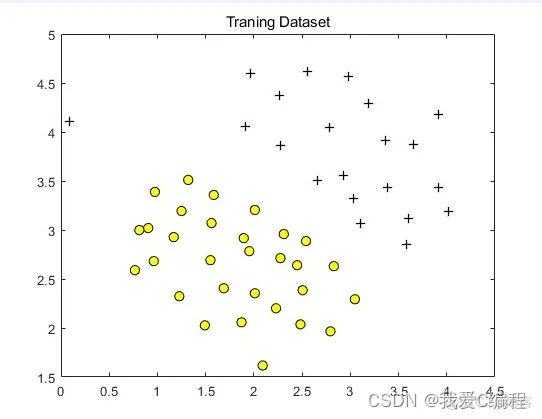
2.仿真效果预览
matlab2022a仿真结果如下:
3.MATLAB核心程序
plotData(X, y);
title('Traning Dataset');
C = 1;
model = svmTrain(X, y, C, @linearKernel, 1e-3, 20);
figure;
visualizeBoundaryLinear(X, y, model);
title('Decision Boundary');
load('example2.mat');
figure,
plotData(X, y);
title('Traning Dataset');
C = 1; sigma = 0.1;
figure,
visualizeBoundary(X, y, model);
title('Decision boundary with RBF kernel');
load('example3.mat');
% Plot training data
figure,
plotData(X, y);
% Training SVM with RBF Kernel (Dataset 3)
load('example3.mat');
[C, sigma] = example3parameters(X, y, Xval, yval);
% Train the SVM
model= svmTrain(X, y, C, @(x1, x2) gaussianKernel(x1, x2, sigma));
figure,
visualizeBoundary(X, y, model);
title('Decision boundary with RBF kernel');
a97
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















