















































软件

产品


1.算法仿真效果
matlab2022a仿真结果如下: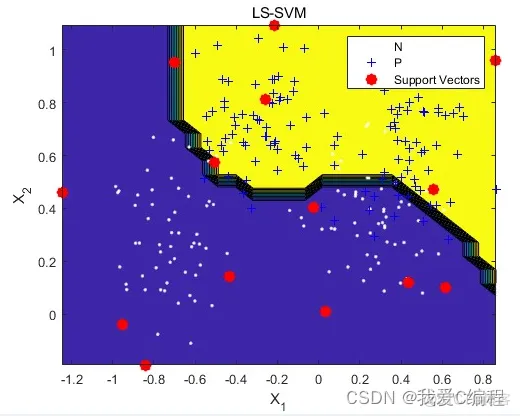

2.算法涉及理论知识概要
LSSVM(Least Square SVM)是将Kernel应用到ridge regression中的一种方法,它通过将所有样本用最小二乘误差进行拟合(这个拟合是在kernel变换过的高维空间),但是LSSVM的缺陷是计算复杂度大概是样本数的三次方量级,计算量非常大。为了解决这个问题于是提出了SVR(支持向量回归),SVR通过支持向量减小了LSSVM的计算复杂度,并且具备LSSVM的能够利用kernel在高纬度拟合样本的能力。
LSSVM的推导过程:

在SVM推导过程中讲到过,合法的Kernel必须是z_n,z_m组成Kernel的矩阵必须是半正定的,因此上面这个求逆过程必定有解。
LSSVM的特性
1) 同样是对原始对偶问题进行求解,但是通过求解一个线性方程组(优化目标中的线性约束导致的)来代替SVM中的QP问题(简化求解过程),对于高维输入空间中的分类以及回归任务同样适用;
2) 实质上是求解线性矩阵方程的过程,与高斯过程(Gaussian processes),正则化网络(regularization networks)和费雪判别分析(Fisher discriminant analysis)的核版本相结合;
3) 使用了稀疏近似(用来克服使用该算法时的弊端)与稳健回归(稳健统计);
4) 使用了贝叶斯推断(Bayesian inference);
5) 可以拓展到非监督学习中:核主成分分析(kernel PCA)或密度聚类;
6) 可以拓展到递归神经网络中。
3.MATLAB核心程序
% train model
if isempty(model.gam) && isempty(model.kernel.pars)
error('Please tune model first with ''tunelssvm'' to obtain tuning parameters');
end
model = trainlssvm(model);
s = smootherlssvm(model);
Yhat = simlssvm(model,x);
% bias: double smoothing with fourt order kernel RBF4
modelb = initlssvm(x,y,'f',[],[],'RBF4_kernel','o');
modelb = tunelssvm(modelb,'simplex','crossvalidatelssvm',{10,'mse'});
modelb = trainlssvm(modelb);
biascorr = (s-eye(size(x,1)))*simlssvm(modelb,x);
% construct approximate 100(1-alpha)% confidence interval
%1) estimate variance nonparametrically
sigma2 = varest(model);
%2) calculate var-cov matrix
s = s*diag(sigma2)*s';
%2b) find standardized absolute maxbias
delta = max(abs(biascorr./sqrt(diag(s))));
%3) pointwise or simultaneous?
if conftype(1)=='s'
z = tbform(model,alpha) + delta;
elseif conftype(1)=='p'
z = norminv(alpha/2);
Yhat = Yhat - biascorr;
else
error('Wrong type of confidence interval. Please choose ''pointwise'' or ''simultaneous''');
end
ci = [Yhat+z*sqrt(diag(s)) Yhat-z*sqrt(diag(s))];
function [var,modele] = varest(model)
% if preprocessed data, construct original data
if model.preprocess(1)=='p'
[x,y] = postlssvm(model,model.xtrain,model.ytrain);
else
x = model.xtrain; y = model.ytrain;
end
model = trainlssvm(model);
Yh = simlssvm(model,x);
% Squared normalized residuals
e2 = (y-Yh).^2;
% Make variance model
if model.nb_data <= 200
costfun = 'leaveoneoutlssvm'; costargs = {'mae'};
else
costfun = 'crossvalidatelssvm'; costargs = {10,'mae'};
end
modele = initlssvm(x,e2,'f',[],[],'RBF_kernel');
modele = tunelssvm(modele,'simplex',costfun,costargs);
modele = trainlssvm(modele);
% variance model
var = max(simlssvm(modele,x),0);
% make estimate of var unbiased in homoscedastic case if regression
% estimate is unbiased
L = smootherlssvm(model);
S = smootherlssvm(modele);
var = var./(ones(size(x,1),1)+S*diag(L*L'-L-L'));
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















