















































软件

产品


【实验目的】
理解神经网络原理,掌握神经网络前向推理和后向传播方法;
掌握使用pytorch框架训练和推理全连接神经网络模型的编程实现方法。
【实验内容】
1.使用pytorch框架,设计一个全连接神经网络,实现Mnist手写数字字符集的训练与识别。
【实验报告要求】
修改神经网络结构,改变层数观察层数对训练和检测时间,准确度等参数的影响;
修改神经网络的学习率,观察对训练和检测效果的影响;
修改神经网络结构,增强或减少神经元的数量,观察对训练的检测效果的影响。
1 #构建一个类线性模型类,继承自nn.Module,nn.m中封装了许多方法
2 #本模型所用的包含库
3 import torch
4 import torch.nn as nn
5 import torch.nn.functional as F
6 import matplotlib.pyplot as plt
7 import torchvision
8 import numpy as np
9 import torch.optim as optim
10 from torch.utils.data import Dataset #这是一个抽象类,无法实例化
11 from torch.utils.data import DataLoader
12 from torchvision import transforms
13 from torchvision import datasets
14 import os
15 #构建一个compose类的实例,包含转tensor(张量),后面那个是标准化,两个参数分别是均值和标准差
16 train_transform = transforms.Compose([
17 transforms.RandomAffine(degrees = 0,translate=(0.1, 0.1)),#对照片进行随机平移
18 transforms.RandomRotation((-10,10)), #随机旋转
19 transforms.ToTensor(),
20 transforms.Normalize((0.1307,),(0.3081,))])
21 test_transform = transforms.Compose([transforms.ToTensor(),
22 transforms.Normalize((0.1307,),(0.3081,))])
23 #这2个值也是调参重灾区……
24 train_batch_size = 256
25 learning_rate = 0.006
26 test_batch_size = 100
27 random_seed = 2 # 随机种子,设置后可以得到稳定的随机数
28 torch.manual_seed(random_seed)
29 torch.cuda.manual_seed_all(random_seed) #为gpu提供随机数
30 # 下载训练集 MNIST 手写数字训练集
31 # 数据是datasets类型的
32 train_dataset = datasets.FashionMNIST(
33 root='../datasets', train=True, transform=transforms.ToTensor(), download=False)
34
35 test_dataset = datasets.FashionMNIST(
36 root='../datasets', train=False, transform=transforms.ToTensor(),download=False)
37
38 train_loader = DataLoader(dataset=train_dataset,batch_size=train_batch_size,shuffle=True,pin_memory=True)
39 test_loader = DataLoader(dataset=test_dataset,batch_size=test_batch_size,shuffle=False,pin_memory=True)
40 class Net(nn.Module):
41 def __init__(self):
42 super(Net, self).__init__()
43 #卷积层
44 self.conv1 = nn.Conv2d(1 ,32, kernel_size=5,padding=2)
45 self.conv2 = nn.Conv2d(32 ,64, kernel_size=5,padding=2)
46 self.conv3 = nn.Conv2d(64 ,128,kernel_size=5,padding=2)
47 self.conv4 = nn.Conv2d(128,192,kernel_size=5,padding=2)
48
49 #残差神经网络层,其中已经包含了relu
50 self.rblock1 = ResidualBlock(32)
51 self.rblock2 = ResidualBlock(64)
52 self.rblock3 = ResidualBlock(128)
53 self.rblock4 = ResidualBlock(192)
54
55 #BN层,归一化,使数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
56 self.bn1 = nn.BatchNorm2d(32)
57 self.bn2 = nn.BatchNorm2d(64)
58 self.bn3 = nn.BatchNorm2d(128)
59 self.bn4 = nn.BatchNorm2d(192)
60
61 #最大池化,一般最大池化效果都比平均池化好些
62 self.mp = nn.MaxPool2d(2)
63
64 #fully connectected全连接层
65 self.fc1 = nn.Linear(192*7*7, 256) # 线性
66 self.fc6 = nn.Linear(256, 10) # 线性
67
68 def forward(self, x):
69 in_size = x.size(0)
70
71 x = self.conv1(x) #channels:1-32 w*h:28*28
72 x = self.bn1(x)
73 x = F.relu(x)
74 x = self.rblock1(x)
75
76 x = self.conv2(x) #channels:32-64 w*h:28*28
77 x = F.relu(x)
78 x = self.bn2(x)
79 x = self.rblock2(x)
80
81 x = self.mp(x) #最大池化,channels:64-64 w*h:28*28->14*14
82
83
84 x = self.conv3(x) #channels:64-128 w*h:14*14
85 x = self.bn3(x)
86 x = F.relu(x)
87 x = self.rblock3(x)
88
89 x = self.conv4(x) #channels:128-192 w*h:14*14
90 x = self.bn4(x)
91 x = F.relu(x)
92 x = self.rblock4(x)
93
94 x = self.mp(x) #最大池化,channels:192-192 w*h:14*14->7*7
95
96 x = x.view(in_size, -1) #展开成向量
97 x = F.relu(self.fc1(x)) # 使用relu函数来激活
98
99 return self.fc6(x)
100
101 #调用GPU
102 os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
103 torch.backends.cudnn.benchmark = True #启用cudnn底层算法
104 device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
105 #print(device)
106 torch.cuda.empty_cache() #释放显存
107
108 model.to(device)
109
110 # #构建损失函数
111 criterion = torch.nn.CrossEntropyLoss() #交叉熵
112 #
113 # #构建优化器,参数1:模型权重,参数二,learning rate
114 optimizer = optim.SGD(model.parameters(),lr=learning_rate,momentum=0.5) #带动量0.5
115
116 #optimizer = optim.RMSprop(model.parameters(),lr=learning_rate,alpha=0.99,momentum = 0.5)
117 # optimizer = torch.optim.Adam(model.parameters(),
118 # lr=0.05,
119 # betas=(0.9, 0.999),
120 # eps=1e-08,
121 # weight_decay=0,
122 # amsgrad=False)
123 #设置学习率梯度下降,如果连续2个epoch测试准确率没有上升,则降低学习率,系数0.5
124 scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=2, verbose=True, threshold=0.00005, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
125 #把训练封装成一个函数
126 def train(epoch):
127 running_loss =0.0
128 for batch_idx,data in enumerate(train_loader,0):
129 inputs,target = data
130 inputs,target = inputs.to(device),target.to(device)
131 optimizer.zero_grad()
132
133 #forward,backward,update
134 outputs = model(inputs)
135 loss = criterion(outputs,target)
136 loss.backward()
137 optimizer.step()
138
139 running_loss+=loss.item()
140 if batch_idx%300==299:
141 train_loss_val.append((running_loss/300))
142 #print('[%d,%5d] loss:%3f'%(epoch+1,batch_idx+1,running_loss/300))
143 print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
144 running_loss = 0.0
145 #把测试封装成函数
146 def test():
147 correct = 0
148 total = 0
149 with torch.no_grad():
150 for data in test_loader:
151 images,labels = data
152 images, labels = images.to(device), labels.to(device)
153 outputs = model(images)
154 #torch.max()返回的是两个值,第一个是用_接受(蚌埠住了),第二个是pre
155 _, predicted = torch.max(outputs.data,dim=1) #从第一维度开始搜索
156 total += labels.size(0)
157 correct += (predicted==labels).sum().item()
158 print('Accuracy on test set: %f %% [%d/%d]' % (100 * correct / total, correct, total))
159
160 return correct/total
161 train_epoch = []
162 model_accuracy = []
163 temp_acc = 0.0
164 train_loss_val = []
165 for epoch in range(30):
166 train(epoch)
167 acc = test()
168
169 print(epoch + 1,acc)
170 train_epoch.append(epoch)
171 model_accuracy.append(acc)
172 scheduler.step(acc)
173
174 plt.figure(1)
175 plt.plot(train_epoch, model_accuracy) # 传入列表,plt类用来画图
176 plt.grid(linestyle=':')
177 plt.ylabel('accuracy') # 定义y坐标轴的名字
178 plt.xlabel('epoch') # 定义x坐标
179 plt.show() # 显示
1 Output exceeds the size limit. Open the full output data in a text editor
2 Accuracy on test set: 89.560000 % [8956/10000]
3 1 0.8956
4 Accuracy on test set: 89.340000 % [8934/10000]
5 2 0.8934
6 Accuracy on test set: 89.360000 % [8936/10000]
7 3 0.8936
8 Accuracy on test set: 89.380000 % [8938/10000]
9 4 0.8938
10 Epoch 4: reducing learning rate of group 0 to 3.0000e-03.
11 Accuracy on test set: 89.340000 % [8934/10000]
12 5 0.8934
13 Accuracy on test set: 89.470000 % [8947/10000]
14 6 0.8947
15 Accuracy on test set: 89.430000 % [8943/10000]
16 7 0.8943
17 Epoch 7: reducing learning rate of group 0 to 1.5000e-03.
18 Accuracy on test set: 89.360000 % [8936/10000]
19 8 0.8936
20 Accuracy on test set: 89.470000 % [8947/10000]
21 9 0.8947
22 Accuracy on test set: 89.440000 % [8944/10000]
23 10 0.8944
24 Epoch 10: reducing learning rate of group 0 to 7.5000e-04.
25 Accuracy on test set: 89.410000 % [8941/10000]
26 11 0.8941
27 ...
28 Accuracy on test set: 89.400000 % [8940/10000]
29 14 0.894
30 Accuracy on test set: 89.510000 % [8951/10000]
31 15 0.8951
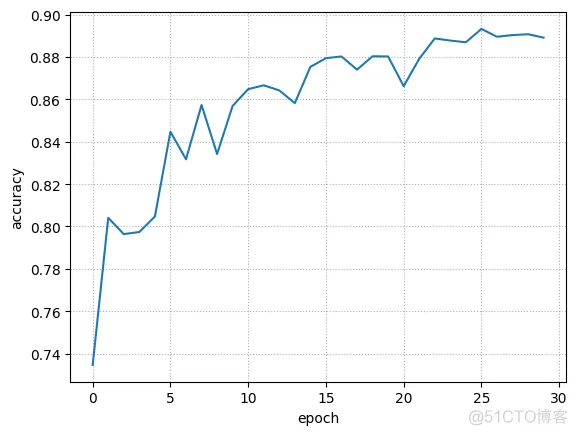
修改神经网络的学习率,观察对训练和检测效果的影响;
在训练神经网络时,需要设置学习率(learning rate)控制参数的更新速度,学习速率设置过小,会极大降低收敛速度,增加训练时间;学习率太大,可能导致参数在最优解两侧来回振荡。学习率和训练次数同样也会影响正确率。学习率太高,代价函数不容易降低到最低点(会不断越过最低点)。
修改神经网络结构,增强或减少神经元的数量,观察对训练的检测效果的影响。
一般来说,在调参合理的情况下,层数和神经元数越多,正确率越高,不过相应地,容易出现过拟合
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















