















































软件

产品


本文主要对吴恩达深度学习中卷积神经网络的课程进行了学习,下面是CNN工作原理总结。
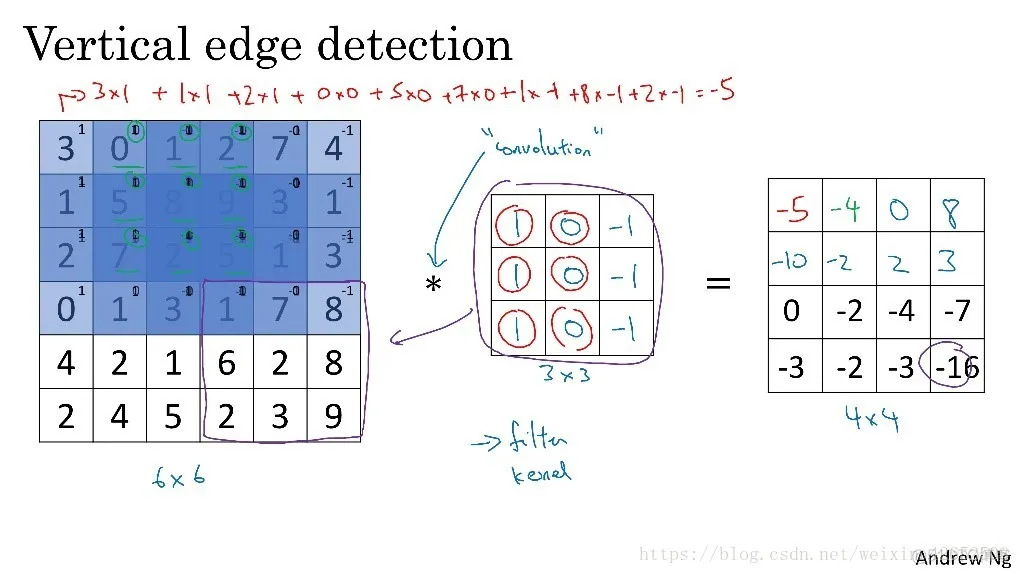
在学习CNN的工作原理时首先从图像识别入手。要想让计算机识别一张图片上有什么物体,首先要做的就是对图片的边缘检测。这里就用到一个过滤器,如下图所示,我们把图像以6x6的像素以矩阵的形式作为网络的输入,这时候定义一个垂直边缘过滤器,过滤器filter尺寸为3x3,定义过滤器的步长stride为1,为过滤器设定初始超级参数。过滤器在图像上逐步滑动,对整个图像进行卷积计算得到一个4x4的图像。以左上角的-5为例
3*1+0*0+1*-1+1*1+5*0+8*-1+2*1+7*0+2*-1 = -5(这里的*表示乘积运算)
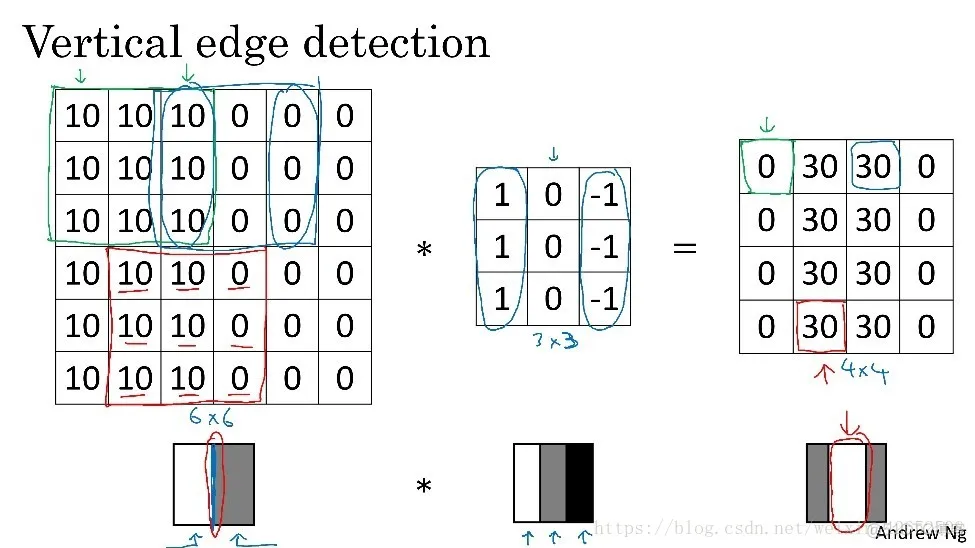
那么为什么进过过滤器的卷积计算就可以识别出图像的边缘,如下图所示,0表示图像暗色区域,10为图像比较亮的区域,同样用一个3x3过滤器,对图像进行卷积,得到的图像中间亮,两边暗,亮色区域就对应图像边缘。 这里的边缘看起来有点粗是因为我们当前输入的图片比较小,如果如果输入时一个1000x1000的图像或者更大一些效果就会很好。
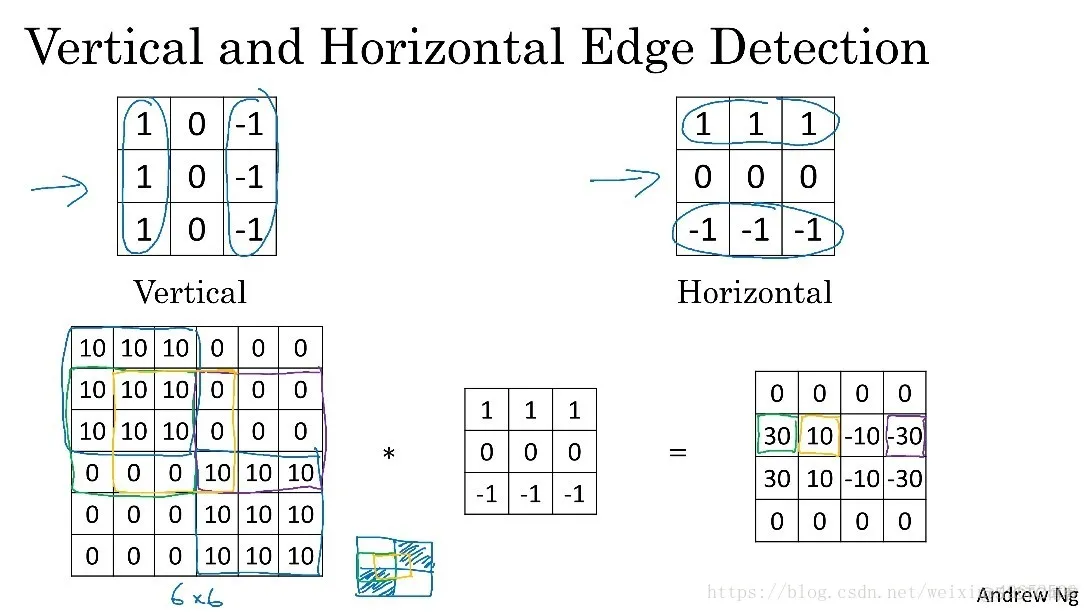
同样的道理我们可以定义水平过滤器如下图所示,这时候我们得到的输出就是对图像水平边缘检测得到的结果。
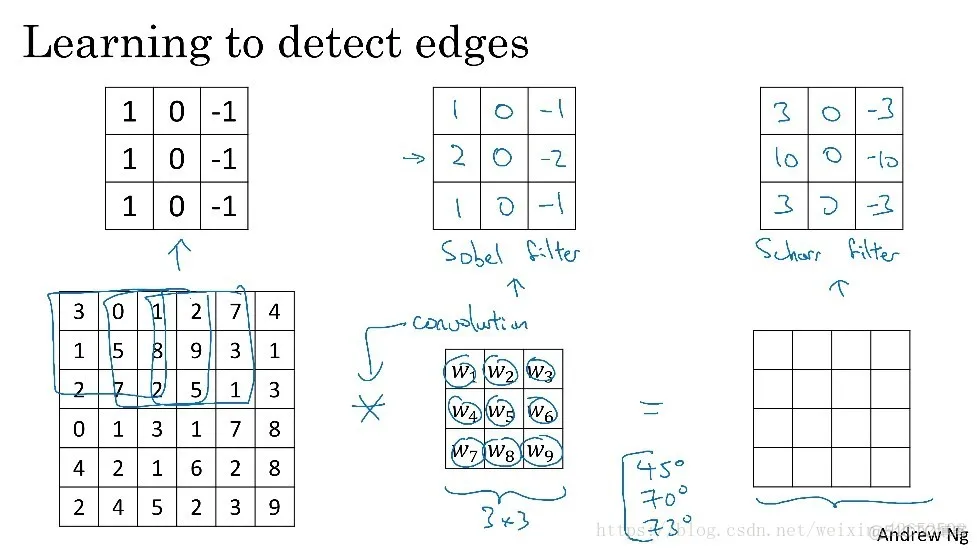
除了上面提到的这种简单的Vertical、Horizontal过滤器之外,还有其它常用的filters,例如Sobel filter和Scharr filter。这两种滤波器的特点是增加图片中心区域的权重,当然这些都是研究者们计算好的过滤器,在检测复杂图像时还可以通过反向传播来让网络学习过滤器的参数,通过学习获得的参数可能是最好的,因为它可以识别任意角度的边缘。
过滤器在图片上进行卷积计算时,图片的边缘位置的信息可能会被忽略,因为经过多次卷积之后图片会越来越小,边缘信息会被遗漏,基于这一问题的解决提出了Padding。为了避免忽略图像中的边缘信息,对输入的图像进行填充之后在进行卷积,如下图所示,填充的像素值用0来代替,这样就可以避免边缘信息由于卷积的次数少而被忽略。

Stride表示filter在原图片中水平方向和垂直方向每次的步进长度。如下图所示。当步长设置为2的时候过滤器在图片上卷积完第一个3x3的矩阵之后向后移动两行进行卷积。
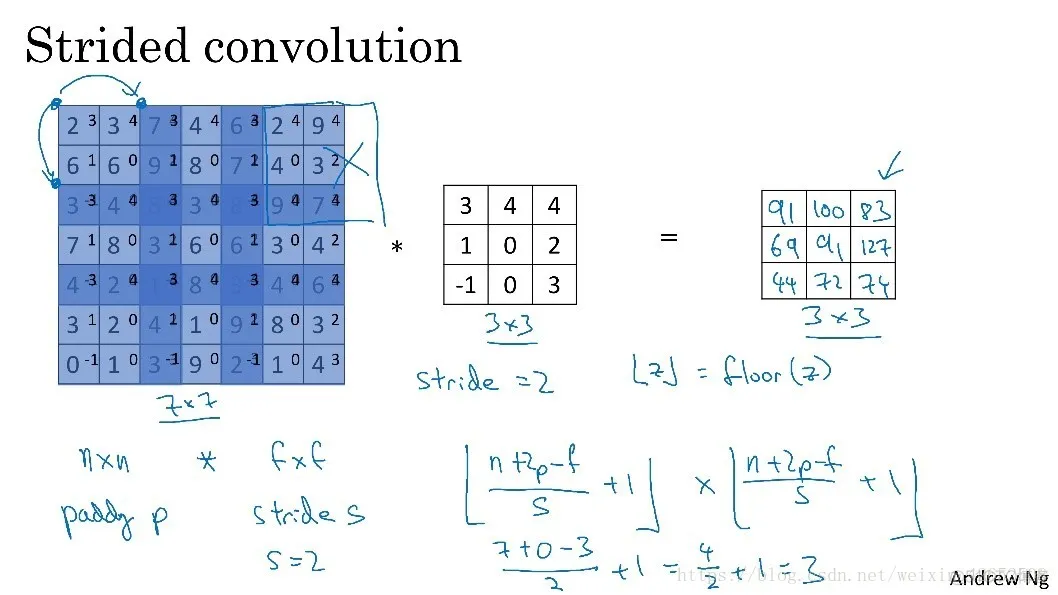
用s表示stride长度,p表示padding长度,如果原始图片尺寸为n x n,filter尺寸为f x f,则卷积后的图片尺寸为:

如果(n+2*p-f)/s的商不是整数,那么向下取整。
在这里输入图片为彩色图片,从红绿蓝三个通道进行对图片的特征提取。如下图所示,红绿蓝分别作为三种不同的通道,可以看成是三个输入矩阵,而对应这三个通道的过滤器也同样保持三维的通道与其保持一致,在卷积进行时过滤器的每一层分别与图像的每一个通道进行卷积,最后得到一个4x4的输出,在下面这张图片中用了两个过滤器,最终经过两个过滤器的卷积得到一个4x4x2的输出。
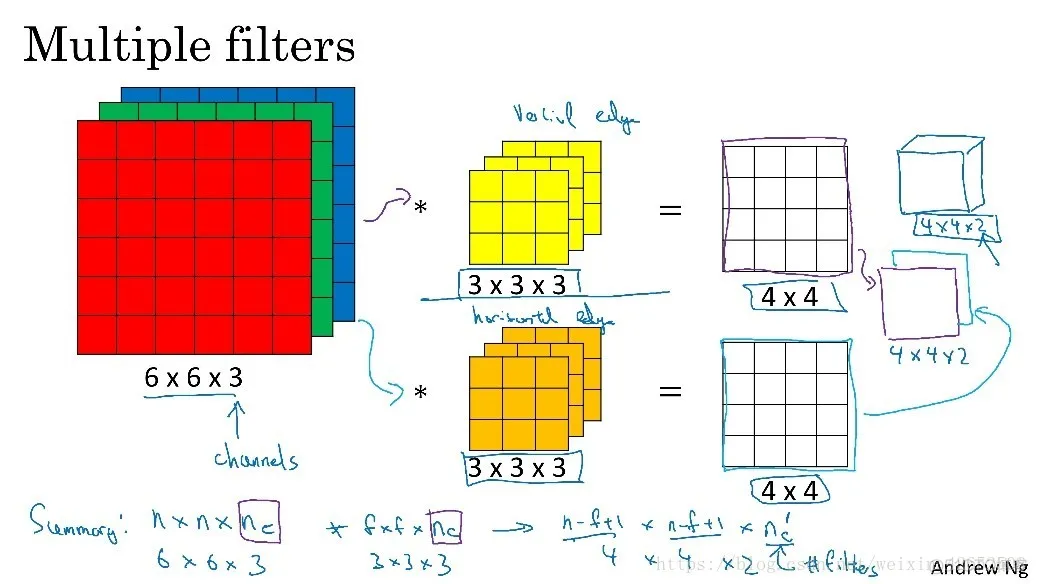
例如输入图片是6x6x3,分别表示图片的高度(height)、宽度(weight)和通道(#channel),过滤器通道也必须为3,可以是3x3x3也可以是5x5x3,即尺寸可以按需定制,而通道必须一致。
为了进行多个卷积运算,实现更多边缘检测,可以增加更多的滤波器组。例如设置第一个过滤器实现垂直边缘检测,第二个过滤器实现水平边缘检测。这样,不同过滤器卷积得到不同的输出,个数由滤波器组决定。
在这一部分中,输入为n x n x nc 过滤器为 f x f x nc
最终得到输出图片大小为n – f + 1 x n – f + 1 x n_c
其中n为输入矩阵大小。 nc 为输入维数,f为过滤器大小,n_c为过滤器个数。
在上一部分中图像通过两个过滤器得到了两个4x4的矩阵,在两个矩阵上分别加入偏差b1和b2,然后对加入偏差的矩阵做非线性的Relu变换,得到一个新的4*4矩阵,这就是单层卷积网络的完整计算过程。用公式表示:
z[1]=w[1]a[0]+b[1]z[1]=w[1]a[0]+b[1]
a[1]=g(z[1])a[1]=g(z[1])
其中输入图像为a[0],过滤器用w[1]表示,对图像进行线性变化并加入偏差得到矩阵z[1],a[1]是应用Relu激活后的结果。如下图所示。

在这一层中主要的作用是处理卷积之后生成的图片,减小模型大小,提高计算速度,并提高提取特征的鲁棒性。所以在pooling中一般不用padding填充。
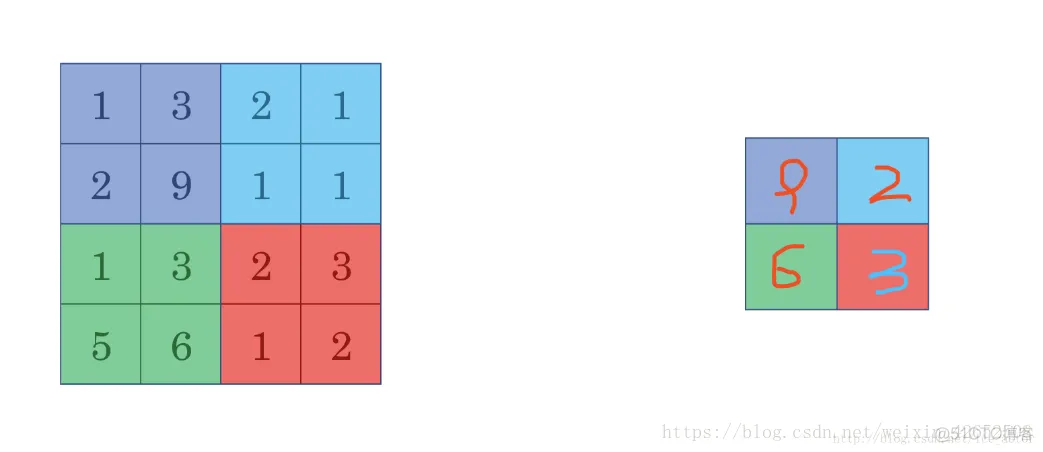
池化分为最大池化和平均池化。最大池化思想很简单,以下图为例,把4x4的图像分割成4个不同的区域,然后输出每个区域的最大值,这就是最大池化所做的事情。其实这里我们选择了2x2的过滤器,步长为2。在一幅真正的图像中提取最大值可能意味着提取了某些特定特征,比如垂直边缘、一只眼睛等等。平均池化就是在输出中取的是每一个区域的平均值,最大池化使用比较多。
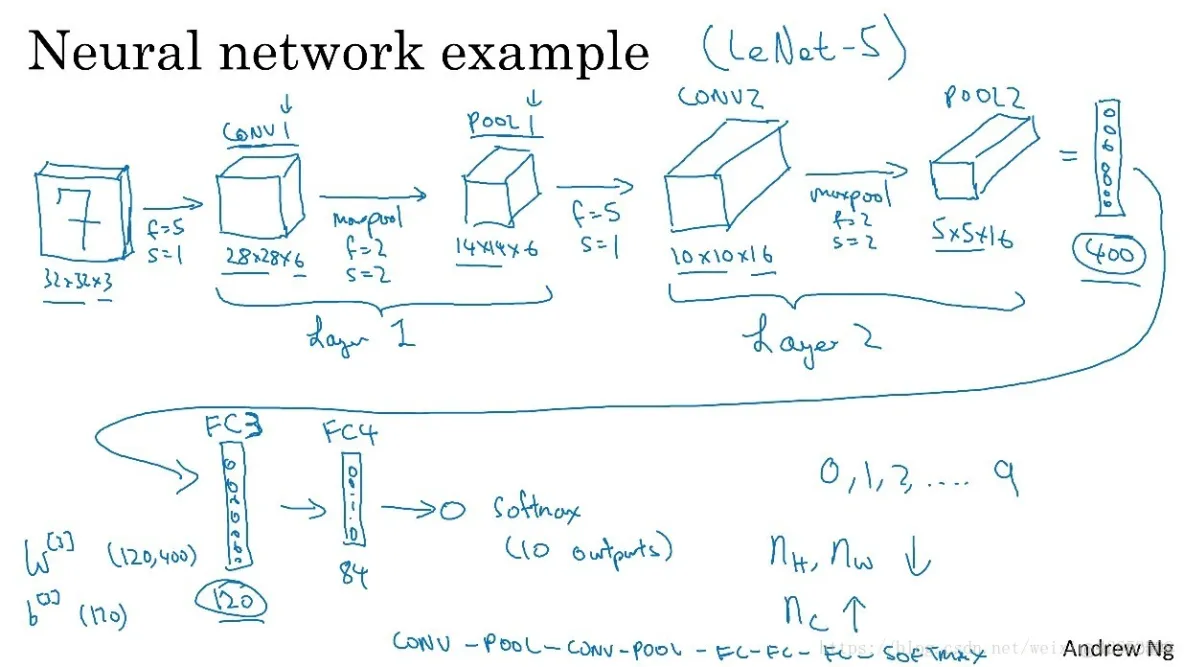
如下图所示,这部分通过一个例子介绍简单卷积神经网络的整体实现流程。在这个Demo中我们假定输入为一个39x39x3的图片,在第一层CONV1中定义10个过滤器,每个过滤器中f=3,s=1,p=0,经过卷积之后得到一个28x28x6的输出,之后对CONV1输出的结果进行最大池化处理,这里的池化参数为f=2,s=2,经过池化处理后得到14x14x6的输出,这时候将输出送入到第二个卷积层进行卷积,定义CONV2中的过滤器参数f=5,s=1,经过CONV2得到一个10x10x16的输出,再对这时的输出进行最大池化处理,定义Pooling2的参数为f=2,s=2,得到5x5x16的输出,这时将Pooling2之后得到的输出送入全连接层。此时就可以把Pooling2的输出看成是普通全连接神经网络的第一层的出入。再进过全连接层中各节点之间的映射和相互激活最后产生输出值。这就是CNN的整个工作过程。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















