















































软件

产品


1初期预测和介绍
现阶段,人脸识别是人工智能领域最炙手可热的话题之一。Google和Facebook,以及国内一些创业公司都投入重金在该领域进行研发,并且有相当多的商业应用。
随着Deep Learning算法的引入,计算机在人脸识别方面的准确率和鲁棒性得到了一个突破性的提高 [1, 2], 计算机算法犯第二类错误(把假当作真,即把非A识别为A)的概率也下降了很多。
相比于识别失败率,这个参数在工业场景的应用中可能更为重要,因为他会更直接关系到产品的安全性。计算机人脸识别系统在安全方面的应用因此有了更好的接受度。
计算机人脸识别的准确率已经超过人类。目前的算法体现出来一些特征,从人脑的人脸认知和识别角度来看,显得非常的有趣。
计算机人脸识别算法面对自然场景的人脸识别(Face Recognition in the Wild)问题时仍然有一些困难[3],而这些困难又跟人脑在自然场景做人脸识别时面对的困难又有一些相似和不同。
这些问题的根本原因,还是在于计算机与人脑在人脸识别任务上处理的方法,或者说算法原理方面的相似性和不同。
大略来看,在人脸方面我们可以问以下一类问题:
1. 人在做人脸识别时候的注意点 跟 计算机算法(特别地,深度神经网络)的“认知”重点有什么差异
2. 人在做人脸识别的学习过程中,需要的样本数量很多,但是跟深度神经网络训练所需的动则上百万个样本这样一个数量级还是有很大的差距 [4],是什么导致了这个问题
3. 人脑人脸识别任务的一些低识别率场景是怎么导致的;计算机算法也会面对类似的问题,其原因是什么;两种算法(人脑的识别算法/模型 与 计算机的算法)如何相互参考
4. 计算机人脸识别算法最新趋势中跟人脑认知的差异
5. .......
作为研究人脑多年并转入计算机人脸识别领域的研究者,我发现自己处于这样一个独特的位置:我问出的问题跟这两个领域中的人都不同,但又能同时快速的获取和理解这两个方面的研究问题。
因此决定把这个话题写成一个系列,作为我自身工作的总结。这是一个活动的长期系列,其完成没有时间表,所问的问题和所要解决的问题也会不断的扩张。
2静态人脸与动态人脸
在做人脸识别训练方面,人脑认知与计算机算法的第一个不同在于,人类接受的人脸图像训练是多角度的、动态的,而目前计算机算法在训练之中使用的基本上是静态的图片[1]。
现有的图像训练数据库,无论是常用的一类公开数据集LFW, CASIA-WebFace, 还是Google和Facebook使用的闭源数据库,即便对同一个人有很多张不同时间和场景的图片,他们都只是截取了有限的角度。
<Fig. 典型人脸数据集图片>
人类在要认识一个陌生人时,不免需要多观察几眼,特别是对于一个长的美貌/化妆过的人脸,由于更接近平均人脸,外在特征(external features: hair, face, outline)和内在特征(internal features: eyes, nose, mouth) [2] 相对来说不明显,一般需要动态观察更久才能记住。
实验室条件下的受限环境刺激和训练证明,人类识别/记住一个陌生人脸,使用动态图像比使用静态图片更有优势 [3, 4]:
<Fig. 静态人脸v.s动态人脸>
<Fig. 静态人脸v.s动态人脸任务的反应时间,反应时间越短越好>
不难想象的,动态人脸能提供来自更多角度的更多可供识别的信息,即使实验场景下,这些动态人脸提供的信息跟真实场景中的还有一定的差距,但是动态人脸刺激相比于静态人类刺激的优势在实验场景下可观测的。
在计算机算法方面,近年来随着深度学习的引入,主流人脸识别算法对训练图像的数量提出了越来越高的需求,动则达到数百万以上,Google 的FaceNet更是达到令人嗔目结舌的20亿数量级[5, 6],但是不开放。
传统学术界的实验室算法受限于使用公开数据集,为了达到更好的效果不得不另辟蹊径,在有限的图像上获取更多信息,也就是Data Augmentation [7]. 最简单的Face Data Augmentation无疑是变换图像的左右,但是这种做法有可能已经改变了人脸的内在特征。
需要权衡带来的好处(图像数量增加)与缺陷(部分特征可能被抵消)。另一类算法通过模拟人脸在其他视角的图像做Face Data Augmentation. 最初来源于人脸摆正(face frontalization)[8]。
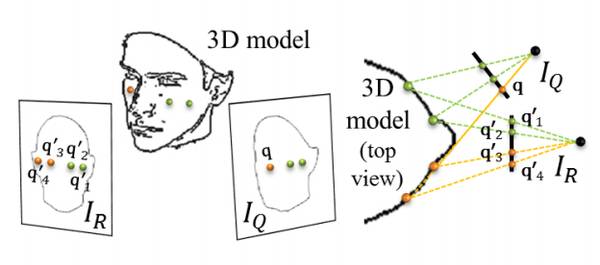
[8] 中算法通过Face Landmark Detector处理目标图像和三维模型图像(二维化之后),得到一组对应的Landmark. 而二维化之后的三维模型上的Landmark({Xi, Yi})在三维模型中具有对应的坐标({Xi, Yi, Zi}).
据此可以估测相机参数,进行相机标定 [9]。从而可以模拟模型与目标图像一样的角度,反过来得出目标图像中像素在摆正之后的位置。
不难理解的,该套算法稍加变化,就可以使用一张人脸图片得出多个角度的人脸图片,即既可以用来做人脸摆正,也可以生成侧脸图像 [10, 11]:
<Fig. 通过相机标定和3D模型模拟,生成其他视角的人脸图像>
这种做法虽然没有增加投入到训练算法中的信息,但大大增加了算法的识别率并降低了误识率(FAR, False Acceptance Rate):
<Fig. 仅仅是通过现有图片生成多个角度(pose)的图片,然后投入训练算法,就能大大增加性能>
当然,生成不同角度的图像更原本就有同一个场景的连续变化视角的图像(视频)对人脸识别来说还是有一些不同的。更为接近自然场景中人脑的人脸识别任务的,是视频中人脸图像的识别。
但是目前由于受限于人脸视频的稀缺性(搜集一个人脸的视频比搜集其图片要繁琐的多,同时视频中的特征标定也是一个严重的问题),深度学习/深度神经网络在视频人脸图像的研究还却如。
目前在这个领域使用的一般是基于模型的传统算法[12-14]。视频中人脸的分辨率跟目前人脸图像数据及中的分辨率还有一定差距,同时视频图像的噪声更大,场景的复杂度好更高。
因此视频中人脸识别跟静态图像中人类识别几乎是用的是完全不同的方法。在结合这两者,应用大量视频图像做人脸识别算法训练之前还得解决以上一系列的技术问题。
3外在特征与内在特征
在上文中我们提到了外在特征与内在特征的概念,简单的说,外在特征(external features)指的是头发(颜色、发型)、脸部轮廓、脸颊等,内在特征(internal features)指的是眼睛、鼻子和嘴巴以及它们之间的内在关系 [1]。
<Fig. 全脸(中)、外在特征(左下)与内在特征(右下),源于[1]>
人类视野的分辨率从视野中央往外侧快速下降,因此需要不断的调整注视方向来获取高精度图像,也就是注意力点的变化。同时,人眼运动控制的相当部分是直接由脑干区域的神经核团支配的,也就是说,不受大脑皮层的控制,因此眼动在大部分情况下不进入意识层面,其运动控制表现出对注意力控制的被支配性。
通过观测注视(眼动)的变化,可以获知人的注意力的重点 [2],也就是信息获取的关键,眼动因此成为了人类意识的一个易于观测的外显参数 [3]。在我们人类发育的早期,观察人脸首先是注意外在特征多,然后逐步发展的更注意内在特征[4]。
当然,这也可能与一岁以下的婴儿的视觉感知情况与更年长者有别有关,两个月以下的婴儿,他/她们的视觉处在一个快速发展的时期——由不清晰到清晰,同时色彩的感知也发生快速的变化[5-7]。
在成人的人脸识别过程总,内在特征与外在特征所扮演的角色各不相同,一般地,我们认为在识别陌生人脸的过程中,外部特征占有比较重要的作用(或者同等重要),当人脸变得熟悉时,外部特征在人脸识别中的重要性逐渐下降,而内部特种的重要性逐渐升高的主导地位 [8]。通过一些量化参数,我们可以大致的描述内在特征和外在特总在人脑的人脸识别任务中的地位[9, 10]:
<Fig. 人脑人脸识别任务中内部特征与外部特征各自的重要性>
当然地,一般认为,人脑人脸识别中,内在特征和外在特征是作为一个整体在大脑皮层的相关区域 (Fusiform Face Area, FFA; Occipital Face Area, OFA; Superior Temporal Sulcus, STS)处理,而不是分开的 [11]。
在计算机人脸识别领域,特别是在深度学习出现以前的使用模型的时代,算法研究一直将重心放在内在特征上 [12],这跟计算机人脸识别的应用场景,以及投入到训练算法中的图像训练集有一定的关系。
训练集里的同一个人经常有不同时期不同发型、妆容的图像,易于理解的,算法关注外在特征会降低算法的识别率并增加误识率,这对算法的性能是不利的 [13]。
<Fig. Active appearance model, AAM>
当然,也有一些人在外在特征方面做过一些尝试,[14] 中算法先使用训练集训练,得到外在特征块的集合Building Block Set,再使用特征块去匹配测试人脸图像,匹配度最高的Building Block提供了测试人脸特征,从而可以用来进行分类。
<Fig.使用外在特征进行人脸识别的样例>
该算法在当时能做到其他模型接近的精度,证明了外在特征进行人脸识别的可行性。但是如上文所说过的,外在特征天然的不稳定性,并不是做人脸识别的最优信息来源。
由于大数据集和深度学习的普遍使用 [15],外在特征在人脸识别算法中被研究人员不自觉的抛弃。新的人脸识别算法对遮挡、发型、妆容、光照这些外在影响的鲁棒性得到了很大的提高,人们对外在特征的关注似乎就到此为止了。
4层次模型 (Hierarchical Model)
视觉皮层是第一个被现代神经解剖学就定义的功能皮层区域,其解剖特征和功能特征都是高度的结构化的。同时,视觉皮层占有的皮层表面积/体积又很大,这客观上方便了视觉皮层的解剖结构和认知功能的研究。
因此,不难理解地,视觉皮层和视觉功能是我们在神经科学方面研究最为深入、理解最为透彻的。
人脑的视觉信号传导通路,在进入大脑皮层之前是高度的结构化的、分工明确的。而且一般认为,视觉信息在进入大脑皮层前,人脑几乎被把它做任何实质意义上的处理,也不从中提取有用的信息 [1]。
<Fig. 视觉通路,视觉信息进入大脑皮层(Primary Visual Cortex) 前的情况>
视觉信息一旦进入大脑皮层(从Primary Visual Cortex初级视觉皮层进入),就体现出其结构化的特征。视觉信息的空间位置跟初级视觉皮层的位置对应起来,总体上表现为空间相邻的位置对应的初级视觉皮层位置也相邻,这种拓扑结构的对应被称为视网膜拓扑映射(Retinotopy)[2].
信息经由初级视觉皮层处理之后,其发出方向就变得复杂起来,总体上分出两个主要的层次结构流:腹侧通路(Ventral Pathway)和背侧通路(Dorsal Pathway),前者的损伤导致人的物体识别功能受损,因此被也被称为"What"通路,后者的损失导致人的空间判别和视觉注意能力受损,因此也被称为"Where"通路 [3]。
<Fig. What通路和Where通路>
特别地,根据猕猴(Macaque Monkey)视皮层的解剖结果,人们重建了其各个视皮层之间的分级结构[4]:
<Fig. 猕猴视觉皮层分级结构图>
在比较低级的视觉皮层区域,还发现其中的神经元对特定的模式刺激放电频率增加,这种模式可能是物体的视角 [5],也可能是熟悉物体的形状 [6]。这些发现为理解大脑物体识别的层次模式提供了越来越全面的信息,从而,我们逐渐理解了人脑物体识别的分级结构模型:
<fig. 人脑物体识别的分层模型>
从初级到更高级的视觉皮层,视觉信息逐级传递。人脑理解的内容越来越复杂化、抽象化,由“模式”变成具体的"物",再到物的特性和物与物之间的关系。
进入到初级视觉皮层的信号是非常的繁杂和全面的,显然地,人脑并不需要所有的这些信号,而是只需要提取其中的有用信号就可以了,否则会给大脑的视觉理解带来太大的压力,基于层次结构特征,人脑发展出了视觉编码压缩方式,把通过视觉通路传递过来的信号,跟自己的经验比对,比照经验中的常见图像模式,经过比对之后,找到最为匹配的模式(线、角、圆……;斑马线,转角……),并以该模式取代实际的事物。
这就好比给视觉信号做了一次编码,以人脑的内禀信号取代实际信号对视觉图像做了极大的压缩,并为后续的快速处理做好了基础。另外,在整个层次模型的处理过程中,信息流在层级间几乎完全表现为“前馈”式 [7]。这为计算机模拟方法的可行性和快速性提供了基础。
上面提到的无疑是人脑的通用物体识别架构,基于这些知识设计了模拟大脑皮层结构的层次物体识别模型 ( Hierarchical Models of Object Recognition in/and Cortex, HMAX)[8]:
<Fig, HMAX Model>
可见这实际上是一种早期形式的深度神经网络,它的每一层也是需要根据具体的任务情况进行训练。
在人脸识别任务中,由于结构较浅,而底层的模型又过于简单[9](网络设计为从简特征到复杂特征),这使得模型在较高层中识别的feature仍然是接近于“线”、“角”这样的易于描述的基础性特征 [10, 11]:
<Fig. 底层网络特征>
<Fig. 高层网络特征>
可见这种网络在设计上就过于限制,深度不如当今的深度神经网络,网络的灵活性上要欠缺更多,在当时,还要限于训练集的数据量和该模型的简单性,其结果几乎不可能超越当今的深度神经经网络。
5生成、反馈与判别
人类学习的过程中伴随着 模仿(生成)、评估(判别或反馈)以及改进,反馈和评估来地越准确越高效,学习的效率也会越高[1]。没有任何形式的反馈,我们不能习得任何能力,而是闭门造车、不断的重复同样的错误,如悲剧性的西西弗斯一般[2]。
在强化学习(Reinforcement Learning)中, Agent的学习需要不断的与环境交换信息,从自己的行动产生的结果(评估和反馈)和新的探索选项(Trial and Error)中得到下一步的行走策略。
行动产生的结果由回报函数产生,训练的目的和过程在于使汇报函数最大,而不在乎每步训练的精确步骤和策略[3]。人工智能领域的强化学习算法是通过模拟人类学习过程的特征得来的[4]。
在人工智能领域,按照功能可以划分出两类主要的模型:生成模型(Generative Model)和判别模型(Discriminative Model). 生成模型根据训练集的分布产生新的数据,新产生的数据要符合训练及的分布特征,比如高斯混合模型(Gaussian Mixture Model, GMM) [5] 在经过多轮训练之后就能用来产生跟训练样本类似的数据。
而判别模型对于大部分人来说要熟悉的多了,判别模型的目的在于给出数据在多类中属于哪一个,容易理解地,所有的分类算法都可以划归为判别模型。比如人脸识别算法就是一类较为复杂的判别模型,它需要对新来的数据在极多个类中作出判别。
按照上面的定义,生成模型需要生成样本X' ~D‘,使得D’尽量接近于训练样本X的分布D. 而判别模型如果应用在生成样本X'和训练样本X上,任务则是判别样本到底属于生成样本和训练样本的哪一类。
对于已知数学定义的生成模型,生成模拟样本数据的过程无疑是可以精确描述的,方法上也相对容易,但在深度神经网络中,因为模型参数的缺失,这个问题就变得复杂的多了。
为此设计了对抗网络(Generative Adversarial Networks, GAN),它也包括两个模型:生成模型G(Z)和判别模型D(X)。如果认为X是真实样本数据(测试数据),那么D(X)=1, 反之如果认为X是生成模型产生的样本数据,那么D(X)=0. 两个模型在训练过程中进行对抗,生成模型根据训练样本生成数据,判别模型作出分类,最终让V(G,D)取得最小最大值[6]:
翻译成容易理解的语言就是:判别模型认为样本X属于测试样本和生成样本Z的概率是随机的,也就是说,判别模型完全无法区分出这两者之间的差异:
<Fig. 训练过程;蓝色虚线:判别分布;黑色点线:训练样本分布;绿色实线:生成样本分布>
但是最初的GAN训练并不稳定,经常产生毫无意义的输出。为了避免这些问题,进行了如下关键改进[7]:
最终得到如下网络结构(根据具体训练任务有所变化):
我使用MNIST手写数字数据集[10]进行测试结果如下:
<Fig. MNIST测试结果:上图,第一个训练epoch的生成Sample; 中图,第200个训练epoch的生成Sample; 下图,真实数据Sample>
比较上图中间的训练结果和下面的真实数据可以发现,对抗网络产生的数据几乎跟真实数据没有人眼可辨的差异。MNIST的数据特征毕竟比较简单,而且人眼对手写数字的变形敏感性比较差,因此还不足以说明问题。
相对应的,人脸数据特征复杂,而且人类的大脑对人脸信息敏感度很高(有专门的人脸识别脑区),对其中的“非人”特性很容易识别,那么对抗网络对人类数据的实用性如何呢,我们从自动化所的WebFace数据集中提取了36万个人脸[11]进行了测试:
<Fig. CASIA-WebFace测试结果:前十二行中每三行一个epoch.最后三行为第20个epoch的结果>
可以看到网络在前几个训练epoch中的产生数据的效果进步很快,但是经过多次训练之后,生成sample表现出特征的趋同化。另外,无论经过多少个epoch的训练,都会产生一些明显不能被人认定为人脸的奇怪数据。
显然地,生成模型在训练过程中坍缩了,生成模型与判别模型在对抗中达成了纳什均衡点[12],但这个均衡点不是系统的唯一均衡点。为了使生成模型避与坍缩,必须在训练过程中告诉它生成数据之间的相似性。
一个显然的策略在于,对判别模型,我们不让他判别各个生成sample与测试sample特征的相似性,而是判别一批生成sample与测试sample的相似性,这样,如果生成sample趋同,那自然与测试sample不相似了,这被称为Minibatch Discrimination [13]:
当然,使用这种策略虽然能够解决生成模型坍缩问题,但是产生诡异数据的问题仍然无法避免,算法表现为把图像特征进行重新整合,这种整合可能是符合真实人脸的,也可能不符合,存在一定的随机性。另外,一些个人性细节丢失的问题也无法避免,因为这些特异性的特征在神经网络训练中被湮没了。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















