















































软件

产品


我们在利用abaqus进行有限元计算后,经常需要提取加载处的节点集的计算值(荷载值(通过反力值提取)和位移值)来形成荷载位移曲线。现假设提取出来的荷载值的excel表格为hezai.xlsx,位移值的excel表格为weiyi.xlsx,并且这两个表格都存于abaqus的工作目录下的excel文件夹中,即路径分别为D:\Abaqus6.14.1\temp\excel\hezai.xlsx和D:\Abaqus6.14.1\temp\excel\weiyi.xlsx。
使用过abaqus上述过程的同学应该知道,每个提取出来的excel表格都是一列为加载时间的步长(奇数列),一列为计算值(偶数列),时间步长和计算值这两列交叉出现。手工的做法应该是在每个excel表中先选出时间步长列,再对其进行删除,然后对所剩下的计算值列进行每行的求和,最后得到加载处的总的计算值。在量大时,这个过程是较为繁琐的。
下面用Python程序来处理上述过程。
1. 一对荷载excel和位移excel
这一部分一步一步详细讲解怎么处理。代码如下
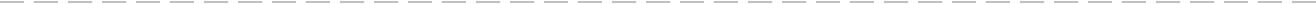
#代码1
#下面这个函数可以通过导入hezai.xlsx或weiyi.xlsx文件来输出只含计算值列的新的excel文件
def func(dir2):
# 形成路径
dir1 = r'D:\Abaqus6.14.1\temp\excel'
import os
dir = os.path.join(dir1, dir2) #路径连接,因为在dir1中字符串前使用了r,所以再将dir2连接到dir1后面不会出现像文章Python-pandas获取excel数据和写入excel数据1第1.1.部分那样的问题,即使此时print(dir)是显示的为(假设dir2='weiyi.xlsx')D:\Abaqus6.14.1\temp\excel\weiyi.xlsx
# 提取计算值的列
import pandas as pd
excel_hq = pd.read_excel(dir) #可以不设置header=None,因为这里我们只需要知道整个excel的列数
excel_lieshu = excel_hq.shape[1] #获取总列数(excel_hq.shape[0]为行数)
import numpy as np
columns = np.arange(1, excel_lieshu + 1, 2) #根据abaqus的excel结果文件可知,计算值的列为偶数列,时间步长为奇数列,所以取偶数列
values = pd.read_excel(dir, usecols=columns, header=None) #需要设置header=None,否则第一行数据会被当做列名而不被读取,Python-pandas获取excel数据和写入excel数据2的第2.2.部分
values.to_excel(os.path.join(dir1, 'jisuanzhi' + dir2), index=None, header=None) #新输出的excel表不包含行名和列名
#注意os.path.join(dir1,'jisuanzhi'+dir2)和os.path.join(dir1,'jisuanzhi',dir2)的区别
#前者会形成D:\Abaqus6.14.1\temp\excel\jisuanzhihezai.xlsx
#后者会形成D:\Abaqus6.14.1\temp\excel\jisuanzhi\hezai.xlsx
##########
func('hezai.xlsx') #输出只包含荷载计算值的列的excel表
func('weiyi.xlsx') #输出只包含位移计算值的列的excel表
########################################
#下面这部分代码将输出的两个计算值的列的excel表汇总成一个excel表
import pandas as pd
import numpy as np
##########
#将荷载值数据列表先写入
dfhezai = pd.read_excel(r'D:\Abaqus6.14.1\temp\excel\jisuanzhihezai.xlsx',header=None)
dfhezai_li = dfhezai.values.tolist() #.tolist()是将数组类型(dfhezai.values)转化为列表,但是转不转化这里都可以,即写成df_li = df.values也可以。从excel表读来的dfhezai为pandas.core.frame.DataFrame类型
hezairesult = []
for i in dfhezai_li:
hezairesult.append(abs(sum(i))) #总荷载应该取为加载处节点集的荷载之和
df = pd.DataFrame(hezairesult,columns=['hezai'])
##########
#再将位移值数据列表写入
dfweiyi = pd.read_excel(r'D:\Abaqus6.14.1\temp\excel\jisuanzhiweiyi.xlsx',header=None)
dfweiyi_li = dfweiyi.values.tolist() #.tolist()是将数组转化为列表,但是转不转化这里都可以,即写成df_li = df.values也可以
weiyilieshu = dfweiyi.shape[1]
weiyiresult = []
for i in dfweiyi_li:
weiyiresult.append(abs(sum(i)/weiyilieshu)) #因为加载处节点集的位移应该一致,所以这里为求和后再平均
df['weiyi']=weiyiresult
##########
#将荷载位移值数据列表写入excel文件
df.to_excel(r'D:\Abaqus6.14.1\temp\excel\hezai-weiyi.xlsx', index=None)
########################################
#开始画图
import matplotlib.pyplot as plt
plt.plot(weiyiresult,hezairesult,color='black')
plt.title('荷载位移曲线', fontproperties='Simsun')
##########
#同一行中分别显示宋体和新罗马,参见文章Python-matplotlib二维绘图知识点详讲(一个画板一个图)1的1.11的4.2)部分
from matplotlib import rcParams
dictionary = {'font.family':'serif', 'mathtext.fontset':'stix', 'font.serif':'SimSun'}
rcParams.update(dictionary)
plt.rcParams['font.sans-serif']='Simsun'
##########
plt.xlabel(r'位移$\mathrm{/mm}$')
plt.ylabel(r'荷载$\mathrm{/N}$')
plt.xticks(fontproperties='Times New Roman')
plt.yticks(fontproperties='Times New Roman')
##########
#画图中标记曲线最大值点的函数(在已经画好图的基础上使用该函数,更复杂的情况参见文章Python-matplotlib二维绘图知识点详讲(一个画板一个图)2的第2.3.部分)
def funczuizhidian(hengzuobiao, zongzuobiao): #传入的参数为横坐标列表和纵坐标列表
import numpy as np
max_index=np.argmax(zongzuobiao) #返回的是纵坐标列表中的最大值的索引值,如需要最小值,则为np.argmin()函数
plt.plot(hengzuobiao[max_index], zongzuobiao[max_index], color='red', marker='*', markersize='10') #通过plt.plot()函数来画点,参见文章Python-matplotlib二维绘图知识点详讲(一个画板一个图)2的2.1.2部分和文章Python-matplotlib二维绘图知识点详讲(一个画板一个图)1的1.11的2)部分
show_text = [hengzuobiao[max_index], zongzuobiao[max_index]]
plt.annotate(str(show_text), xytext=(hengzuobiao[max_index], zongzuobiao[max_index]),xy=(hengzuobiao[max_index], zongzuobiao[max_index]), fontproperties='Times New Roman')
funczuizhidian(weiyiresult, hezairesult)
##########
plt.show()
2. 批量处理同一文件夹下的成对的荷载excel和位移excel
首先说明以下五点:
1) os.walk()函数

我们举一个简单的例子就能明白,例子如下:
在路径为D:\Abaqus6.14.1\temp\excel的文件夹中,包含了一个名称为ziwenjianjia的子文件夹和三个名称分别为wenjian1.xlsx、wenjian2.xlsx和wenjian3.xlsx的文件;子文件夹中包含了三个名称分别为ziwenjian1.xlsx、ziwenjian2.xlsx和ziwenjian3.xlsx的文件。
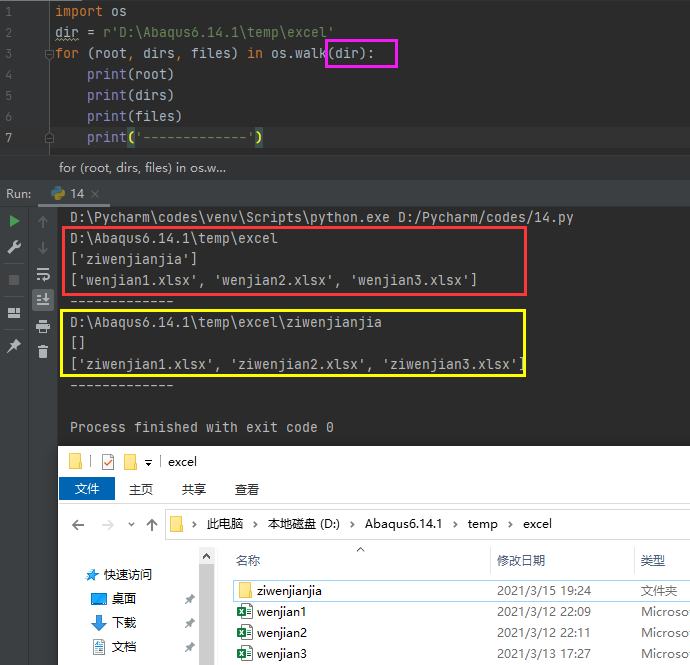
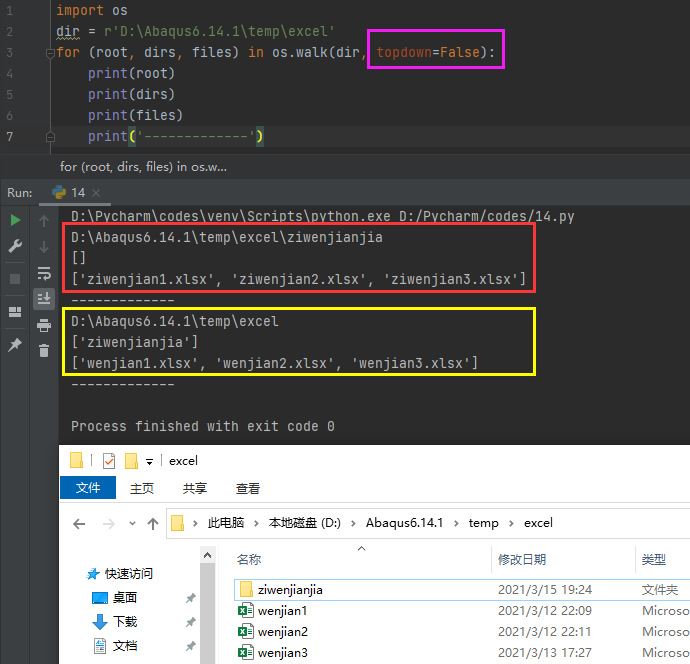
从以上我们不但可以看出三个输出结果的含义,还可以看出topdown=True(默认)和topdown=False的区别:topdown=True时,第一次的for循环是先遍历根目录,然后第二次for循环才是遍历子目录;topdown=False时,第一次的for循环是先遍历子目录,然后第二次for循环才是遍历根目录。
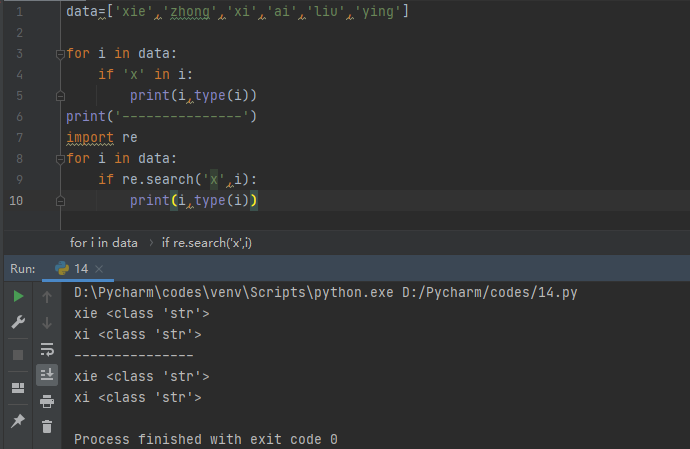
2) 根据某个字符查看列表中的元素
以上展示了两种方法。
特殊地,可以通过endswith()和startswith()来查找列表中以某个字符开头或结尾的元素:
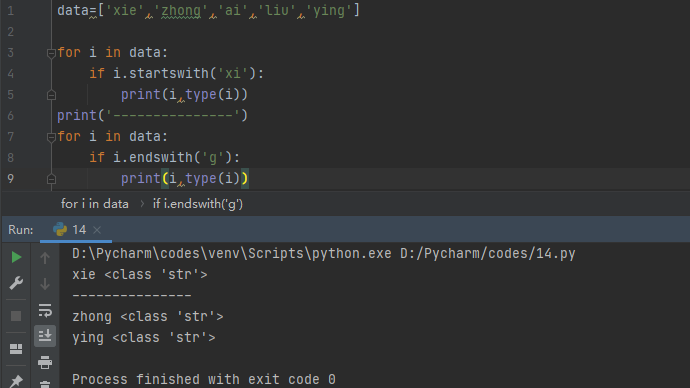
有意思。
3) zip()函数
zip()返回的是一个元素为元组的列表对象,但是如果需要展示列表,还需要list()转换。
#代码
a = ['xie','zhong','xi']
b = ['liu','xiao','ying']
result1 = zip(a,b)
result2 = list(zip(a,b))
print(result1)
#print(result1[0]) #报错:TypeError: 'zip' object is not subscriptable
print(result2)
print(result2[0],type(result2[0])) #输出('xie', 'liu') <class 'tuple'>
print(result2[0][0],type(result2[0][0])) #输出xie <class 'str'>
4) ''.replace()函数
这是字符串的函数,用来替换字符串中的部分内容,如下。
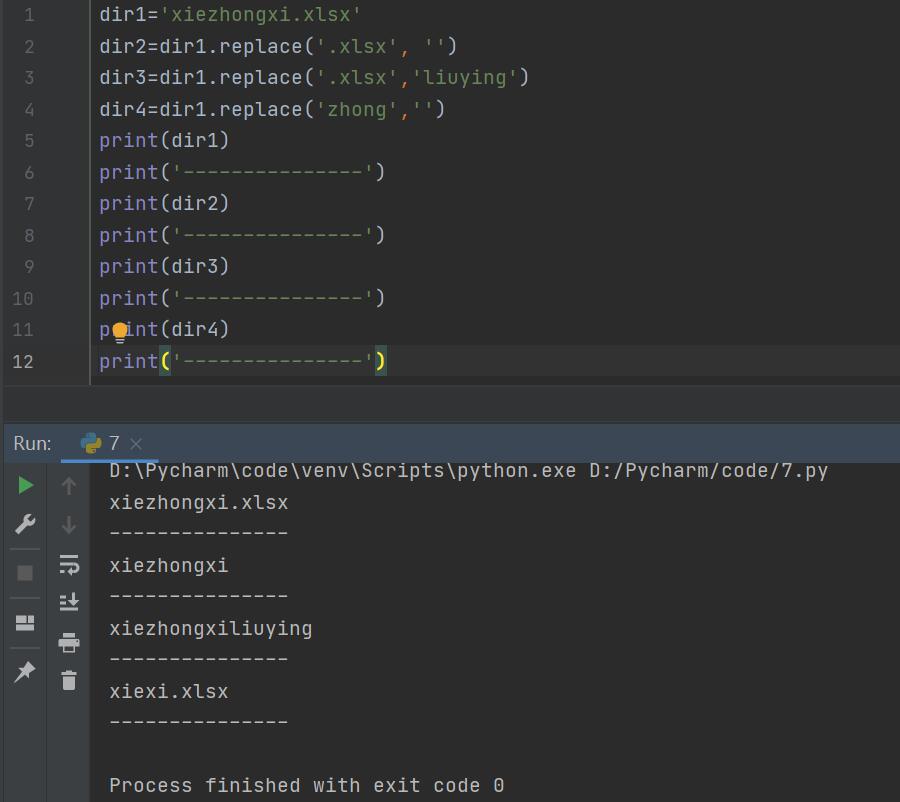
可知:.replace('A', 'B')是将字符串中的内容A替换成B;如果设置为.replace('A', '')则相当于是把字符串中的内容A删去。
5) 假设
为了使用下面这段代码来批量处理abaqus的输出excel表,我们先对excel表格作出以下处理:所有的abaqus输出的excel结果都位于路径D:\Abaqus6.14.1\temp\excel下,并且这个文件夹在以下程序运行前只有这些abaqus输出的结果文件;同一对的荷载和位移excel表格用文件名的最开始的一个数字来统一(如1hezai.xlsx和1weiyi.xlsx表示一对);所有abaqus输出荷载excel文件以hezai来作为命名的结尾,所有abaqus输出位移excel文件以weiyi来作为命名的结尾(如1-10mm-hezai.xlsx和1-10mm-weiyi.xlsx),最开始的数字和最后的hezai或weiyi之间的命名随便取。
在利用第1.部分的代码的基础上,批量处理的代码如下。
#代码2
#下面这个函数用来输出只含计算值列的新的excel文件
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
dir1 = r'D:\Abaqus6.14.1\temp\excel'
def func1(dir2):
# 形成路径
dir = os.path.join(dir1, dir2) #路径连接,因为在dir1中字符串前使用了r,所以再将dir2连接到dir1后面不会出现像文章Python-pandas获取excel数据和写入excel数据1第1.1.部分那样的问题,即使此时print(dir)是显示的为(假设dir2='weiyi.xlsx')D:\Abaqus6.14.1\temp\excel\weiyi.xlsx
# 提取计算值的列
excel_hq = pd.read_excel(dir) #可以不设置header=None,因为这里我们只需要知道整个excel的列数
excel_lieshu = excel_hq.shape[1] #获取总列数(excel_hq.shape[0]为行数)
columns = np.arange(1, excel_lieshu + 1, 2) #根据abaqus的excel结果文件可知,计算值的列为偶数列,时间步长为奇数列,所以取偶数列
values = pd.read_excel(dir, usecols=columns, header=None) #需要设置header=None,否则第一行数据会被当做列名而不被读取,Python-pandas获取excel数据和写入excel数据2的第2.2.部分
values.to_excel(os.path.join(dir1, 'jisuanzhi' + dir2), index=None, header=None) #新输出的excel表不包含行名和列名(注意这里的命名和后面相关,不要轻易改动)
#注意os.path.join(dir1,'jisuanzhi'+dir2)和os.path.join(dir1,'jisuanzhi',dir2)的区别
#前者会形成D:\Abaqus6.14.1\temp\excel\jisuanzhi1hezai.xlsx(如dir2=1hezai.xlsx)
#后者会形成D:\Abaqus6.14.1\temp\excel\jisuanzhi\1hezai.xlsx(如dir2=1hezai.xlsx)
########################################
for lujing, ziwenjianjiaming, files in os.walk(dir1):
for file in files:
func1(file)
########################################
#下面这部分代码将输出的两个计算值的列的excel表汇总成一个excel表
def func2(dir3,dir4):
dir5=os.path.join(dir1, dir3) #荷载excel表
dfhezai = pd.read_excel(dir5,header=None)
dfhezai_li = dfhezai.values.tolist() #.tolist()是将数组类型(dfhezai.values)转化为列表,但是转不转化这里都可以,即写成df_li = df.values也可以。从excel表读来的dfhezai为pandas.core.frame.DataFrame类型
hezairesult = []
for i in dfhezai_li:
hezairesult.append(abs(sum(i))) #总荷载应该取为加载处节点集的荷载之和
df = pd.DataFrame(hezairesult,columns=['hezai'])
dir6=os.path.join(dir1, dir4) #位移excel表
dfweiyi = pd.read_excel(dir6,header=None)
dfweiyi_li = dfweiyi.values.tolist() #.tolist()是将数组转化为列表,但是转不转化这里都可以,即写成df_li = df.values也可以
weiyilieshu = dfweiyi.shape[1]
weiyiresult = []
for i in dfweiyi_li:
weiyiresult.append(abs(sum(i)/weiyilieshu)) #因为加载处节点集的位移应该一致,所以这里为求和后再平均
df['weiyi']=weiyiresult
##########
#将荷载位移值数据列表写入excel文件
dir3=dir3.replace('.xlsx', '') #.replace('.xlsx', '')将文件名的.xlsx去掉
dir3=dir3.replace('jisuanzhi', '')
dir4 = dir4.replace('jisuanzhi', '')
df.to_excel(os.path.join(dir1, dir3+dir4), index=None)
########################################
#画图
plt.plot(weiyiresult,hezairesult,color='black')
plt.title('荷载位移曲线', fontproperties='Simsun')
##########
#同一行中分别显示宋体和新罗马,参见文章Python-matplotlib二维绘图知识点详讲(一个画板一个图)1的1.11的4.2)部分
from matplotlib import rcParams
dictionary = {'font.family':'serif', 'mathtext.fontset':'stix', 'font.serif':'SimSun'}
rcParams.update(dictionary)
plt.rcParams['font.sans-serif']='Simsun'
##########
plt.xlabel(r'位移$\mathrm{/mm}$')
plt.ylabel(r'荷载$\mathrm{/N}$')
plt.xticks(fontproperties='Times New Roman')
plt.yticks(fontproperties='Times New Roman')
##########
#画图中标记曲线最大值点的函数(在已经画好图的基础上使用该函数,更复杂的情况参见文章Python-matplotlib二维绘图知识点详讲(一个画板一个图)2的第2.3.部分)
max_index=np.argmax(hezairesult) #返回的是纵坐标列表中的最大值的索引值,如需要最小值,则为np.argmin()函数
plt.plot(weiyiresult[max_index], hezairesult[max_index], color='red', marker='*', markersize='10') #通过plt.plot()函数来画点,参见文章Python-matplotlib二维绘图知识点详讲(一个画板一个图)2的2.1.2部分和文章Python-matplotlib二维绘图知识点详讲(一个画板一个图)1的1.11的2)部分
show_text = [weiyiresult[max_index], hezairesult[max_index]]
plt.annotate(str(show_text), xytext=(weiyiresult[max_index], hezairesult[max_index]),xy=(weiyiresult[max_index], hezairesult[max_index]), fontproperties='Times New Roman')
##########
plt.savefig(os.path.join(dir1, dir3.replace('.xlsx', '')+dir4.replace('.xlsx', '')+'.png'), format='png', dpi=500) #保存为png格式的图片仅仅是为了快速查看图片效果而已,缺点是有时可能会图片显示不完全。最好我们是保存为svg图片格式,不会存在图片显示不完全的问题(但是svg图片要用Visio来打开),参见Python-matplotlib二维绘图知识点详讲(一个画板一个图)1的第1.12.部分
plt.close() #最好加上这一行,如果没有这行代码,在循环利用函数func2的时候会循环画图,可能图片之间会出现交叉的问题
########################################
hezai_list=[]
weiyi_list=[]
for lujing, ziwenjianjiaming, files in os.walk(dir1):
for file in files:
if file.startswith('jisuanzhi') and file.endswith('hezai.xlsx'):
hezai_list.append(file)
elif file.startswith('jisuanzhi') and file.endswith('weiyi.xlsx'):
weiyi_list.append(file)
hezaiweiyi=list(zip(hezai_list, weiyi_list)) #参见第2.部分的说明3)
########################################
for i in hezaiweiyi:
func2(i[0],i[1])
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















