















































软件

产品


DeepFashion是香港 中文 大学开放的一个large-scale数据集。包含80万张图片,包含不同角度,不同场景,买家秀,买家秀等图片。总共有4个主要任务,分别是服装类别和属性预测、In-Shop和c2s服装检索、关键点和外接矩形框检测。
每张图片也有非常丰富的标注信息,包括类别,属性,Bbox,特征点等信息。部分任务中的数据集需要邮件联系作者获取解压缩密码。
这个任务主要是做服装分类和属性预测的,其中共有50中分类标记,1000中属性标记,包含289,222张图像。每张图像都有1个类别标注,1000个属性标注,Bbox边框,landmarks。更多信息

这个任务的数据集为卖家秀图片集,每个商品id,有多张不同角度的卖家秀,放在同一个 文件夹 内。总共7982件商品,52712张图像,每张图片都有463中属性,Bbox,landmarks,以及店铺描述。更多信息

这个任务的数据集是卖家秀买家秀对应的数据集,每个商品id对应的文件夹中包含一张卖家秀和几张买家秀。总共33881种商品,239557张图片。每张图片都有Bbox,303种属性,以及来源说明(卖家,买家)。更多信息

这个任务的数据集主要是做landmark和Bbox用的,包含123016张图片,每张图片都有landmarks和Bbox的标记,还有类别标注(上衣,下装,全身),以及姿态(正常姿势,大幅度姿势等)信息。。更多信息

关于服装检索,这篇文章作者在In-Shop和C2S两个子任务上做了BaseLine的工作,并将其命名为FashionNet,除了利用到了服装的属性、类别信息之外,作者新颖的提出了使用landmarks辅助提取特征的方法。个人认为这种方法有一些 attention 的意思在里面,通过landmarks detection子网络得到服装特征点以后,对特征点附近进行局部特征编码,最终将其应用在服装检索任务中。
论文提到的FashionNet方法采用的网络backbone为VGG16,实际上经过笔者的复现,使用更新、表征能力更强的网络作为backbone时检索精度还会得到提升;在VGG16网络中,stage4之前的网络结构权值都是共享的,在这一基础上发展了三个网络分支,如下图所示:
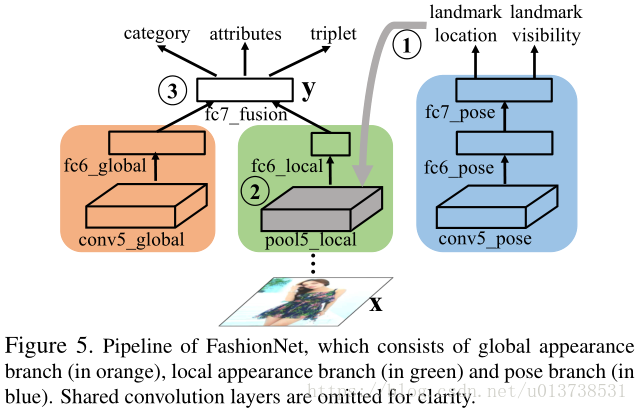
上图的橙色部分、绿色部分和蓝色部分分别代表了全局 特征提取 网络、局部特征提取网络和特征点回归网络。
landmark pooling layer是作者在本文的一个创新点,在图像检索中,landmark所代表的其实是一个局部的,细粒度的特征,通过将这部分特征与全局特征组合能较好的对图像内容进行表征,基于这一点,作者设计了一个关键点回归子网络,基本部分与主网络共享权值。输出的关键点位置信息作为输入被绿色部分网络所接收。绿色部分的网络将关键点位置映射到VGG16 stage4 conv层的输出特征图上,对其附近的特征做统一size的Crop提取,称之为局部特征图。然后对于每一个局部特征图,首先使用max-pooling层操作之后将所有的局部特征图按通道组合在一起,后面使用一个全连接层对其进行编码输出,得到固定维度的局部特征。landmark pooling layer的图示操作如下所示:
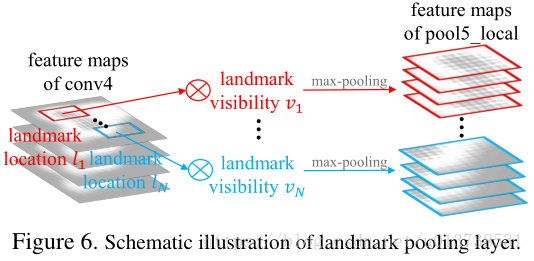
需要注意的是,蓝色部分的关键点回归网络其实除了输出特征点的位置信息之外,还输出了关键点是否可见的标签,在landmark pooling layer操作中,标签为可见的关键点可以用作局部特征提取的输入,但是对于不可见的关键点,论文并没有给出详细的操作指示,笔者将其固定取图像左上角的一块特征区域,最终依然能复现出论文结果。
作者在论文中对FashionNet使用了multi-stage的训练方式:
这样做的理论依据在于,网络的表征能力受到了关键点回归准确程度的影响,在第一个训练阶段中,增加关键点回归子网络的loss比重,可以使得网络在优化训练过程中朝着关键点回归任务偏移,但属性、类别分类器的存在,也使得网络在迭代过程中同时兼顾了服装类别的区分。通过一段时间的第一阶段训练之后,将训练策略调整为所有loss的权重平等,对于一开始就使用平等权重的loss进行训练,能更好的达到局部特征辅助全局特征进行分类的效果。
FashionNet网络在训练过程中总共使用了4种loss结构
关键点回归使用了L2 regression loss,公式如下:
L l a n d m a r k s = ∑ j = 1 ∣ N ∣ ∣ ∣ v j ∗ ( l j ′ − l j ∣ ∣ 2 2 L_{landmarks}=\sum_{j=1}^{|N|}||v_{j}*(l_{j}^{'} - l_{j}||_{2}^{2} Llandmarks=∑j=1∣N∣∣∣vj∗(lj′−lj∣∣22
这两点使用了多标签分类任务,Softmax分类器及其loss函数被用于训练这部分内容,loss分别为 L v i s i b i l i t y L_{visibility} Lvisibility和 L c a t e g o r y L_{category} Lcategory。
属性预测为带权重的cross-entropy loss,其实就是Softmax loss在二分类上的体现,这里需要注意的是对于不同的属性,由于正负比例不均所以使用了不同的权重去定义该部分的loss,公式如下所示:
L a t t r i b u t e s = ∑ j = 1 ∣ D ∣ ( w p o s ∗ a j log p ( a j ∣ x j ) ) + w n e g ∗ ( 1 − a j ) log ( 1 − p ( a j ∣ x j ) ) L_{attributes} = \sum_{j=1}^{|D|}(w_{pos} * a_{j}\log p (a_{j} | x_{j})) + w_{neg} * (1 - a_{j}) \log (1 - p (a_{j} | x_{j})) Lattributes=∑j=1∣D∣(wpos∗ajlogp(aj∣xj))+wneg∗(1−aj)log(1−p(aj∣xj))
其中:
度量学习triplet loss同样也被用于在组合特征中对不同的服装类别进行区分度学习,其使用欧氏距离作为距离判定标准,约束条件为:
L t r i p l e t = ∑ j = 1 ∣ D ∣ max { 0 , m + d ( x j , x j + ) − d ( x j , x j − ) } L_{triplet} = \sum_{j=1}^{|D|} \max \{0, m + d (x_{j}, x_{j}^{+}) - d (x_{j}, x_{j}^{-})\} Ltriplet=∑j=1∣D∣max{0,m+d(xj,xj+)−d(xj,xj−)}
对于三元组损失的详细内容不再解释,有需要请点击triplet loss
官方主页 - Large-scale Fashion (DeepFashion) Database
代码实现 - 谷歌云盘,代码未整理
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















