















































软件

产品


Word2Vec(Word Embeddings)——词向量/词嵌入
是一个可以将语言中字词转化为向量形式表达(Vector Representations)的模型。
主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式,其中CBOW是从原始语句(比如:中国的首都是____)推测目标字词(比如:北京);而Skip-Gram则正好相反,它是从目标字词推出原始语句,其中CBOW对小型数据比较合适,而Skip-Gram则在大型语料中表现的更好。
且使用Word2Vec训练语料会得到一些非常有趣的结果,比如意思相近的词在向量空间中的位置会接近。诸如Beijing,London,New York等城市的名字会在向量空间中聚集。
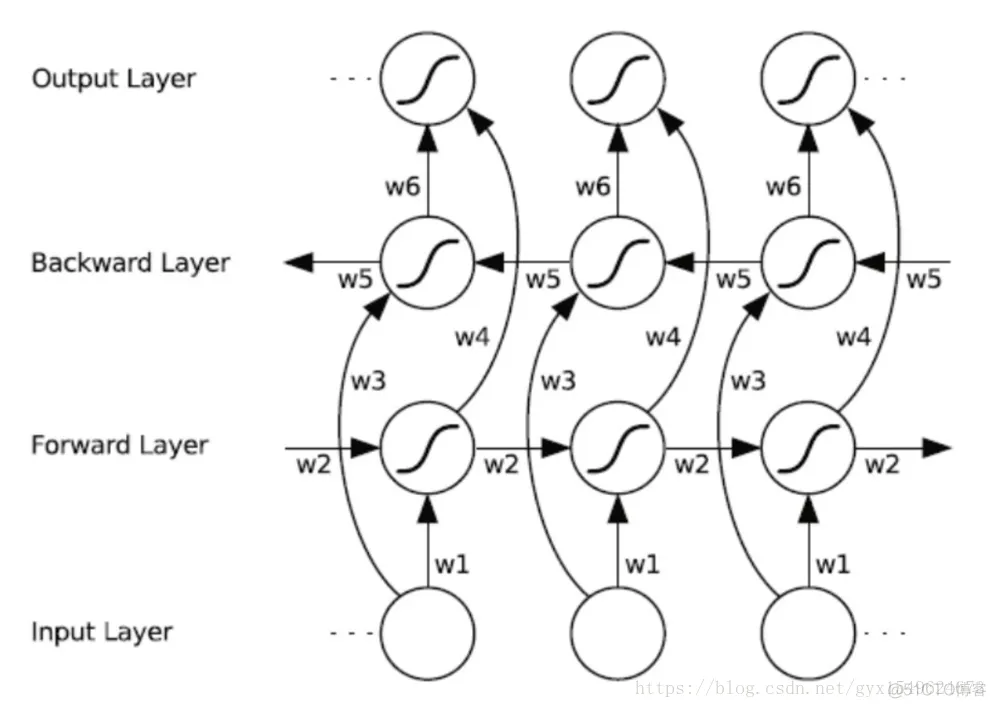
双向循环神经网络(BRNN)的基本思想是提出每一个训练序列向前和向后分别是两个循环神经网络(RNN),而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。下图展示的是一个沿着时间展开的双向循环神经网络。六个独特的权值在每一个时步被重复的利用,六个权值分别对应:输入到向前和向后隐含层(w1, w3),隐含层到隐含层自己(w2, w5),向前和向后隐含层到输出层(w4, w6)。值得注意的是:向前和向后隐含层之间没有信息流,这保证了展开图是非循环的。
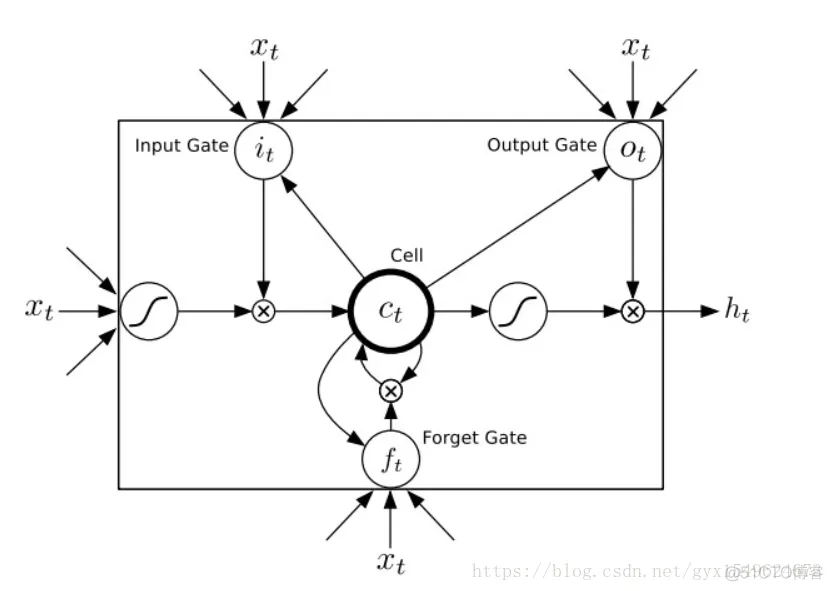
循环神经网路(RNN)在工作时一个重要的优点在于,其能够在输入和输出序列之间的映射过程中利用上下文相关信息。然而不幸的是,标准的循环神经网络(RNN)能够存取的上下文信息范围很有限。这个问题就使得隐含层的输入对于网络输出的影响随着网络环路的不断递归而衰退。因此,为了解决这个问题,长短时记忆(LSTM)结构诞生了。与其说长短时记忆是一种循环神经网络,倒不如说是一个加强版的组件被放在了循环神经网络中。具体地说,就是把循环神经网络中隐含层的小圆圈换成长短时记忆的模块。这个模块的样子如下图所示:
将双向RNN中的圆圈换成长短时记忆模块
一、构造字典
将文本中出现的汉字加入到字典,每一个汉字对应唯一数字值
二、分词向量
对已经分好词的语料打上标签,如下
一字词:
我 s 4
二字词:
中 B 1
国 E 3
三字词:
共 B 1
产 M 2
党 E 3
三、文本向量化
将文本根据标点符号进行切分成多条短文本splitpunc=[‘。’,’?’,’!’,’;’]根据第一步构造的字典将短文本转化为向量,其中长度超过100的将超出部分切除,长度不足100的向量进行补0
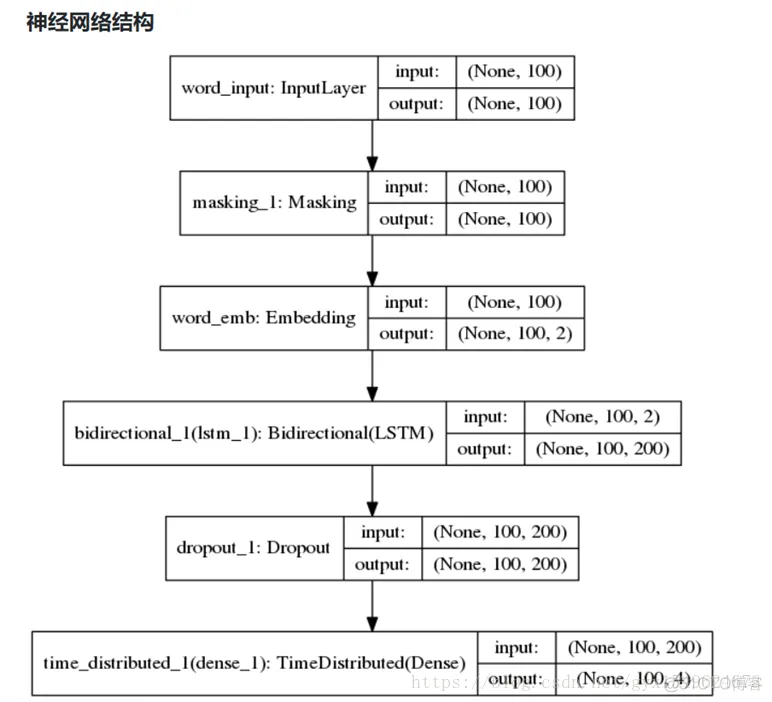
四、进入BiLSTM进行训练
五、测试
结果:

免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















