















































软件

产品


01开篇 Introduction
此次省略300字,建议使用云计算平台如Kaggle Kernel/Google Codelab/Google Cloud 等

查看 tensorflow 版本

02导入数据 Input data
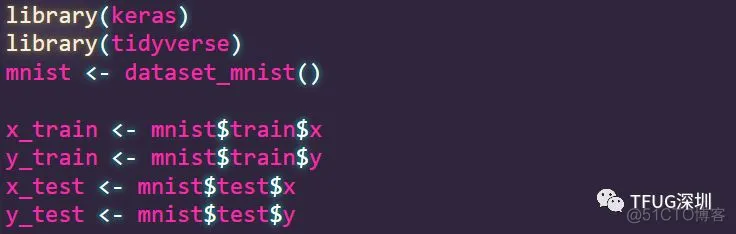
导入4个数据集,分别为:
为什么有4个数据集 ?
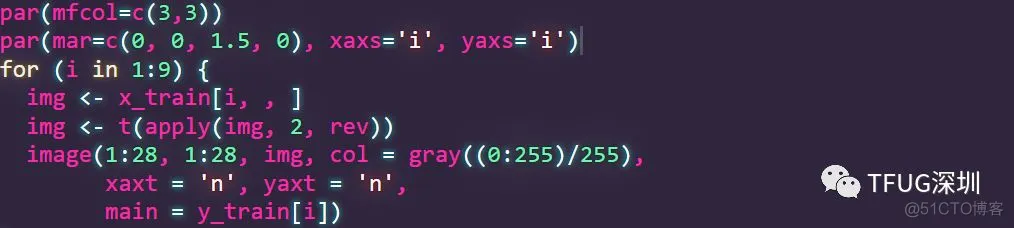
这些图片长这个样

03数据处理 Data cleaning
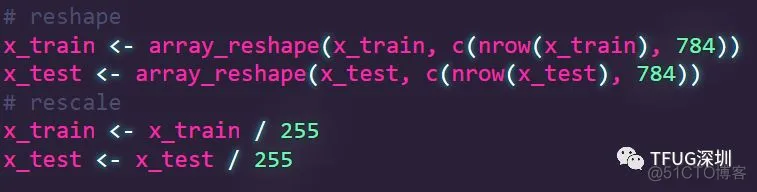
这里对标签作 0,1 embedding 处理。
处理后 y_train 变成了 6万行 ,每行10 个 0或1 的数据。
处理后 y_test 变成了 1万行 ,每行10 个 0或1 的数据

数据处理前
数据处理后
04建立模型 modeling
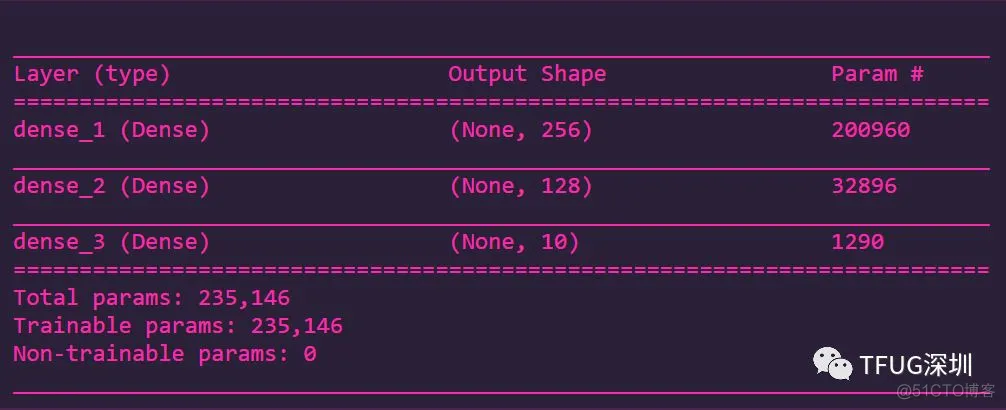
网络结构介绍:
输入层:每个图片的形状为784位数字的输入层
第一层:使用 'relu' 的256个tensor 的隐藏层 (relu 是什么?后续文章再聊)
第二层:使用 'relu' 的128个tensor 的隐藏层
输出层:使用 'softmax' 的 10个 加总为1 的 0到1的概率 的 输出层 (softmax 是什么?后续文章再聊)

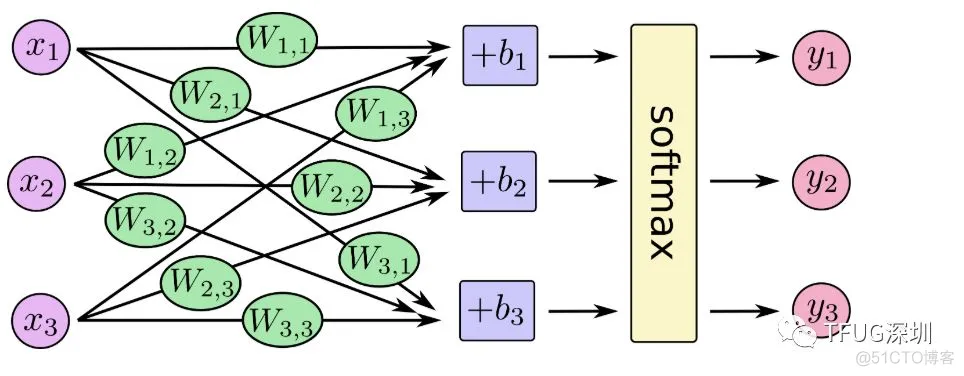
公式是我们设计模型的时候定义的。比如图中的模型。W11-W33 9个weight 和 b1-b3 3个bias 经过训练得出。所以模型训练的Learnable Parameters=9+3=12
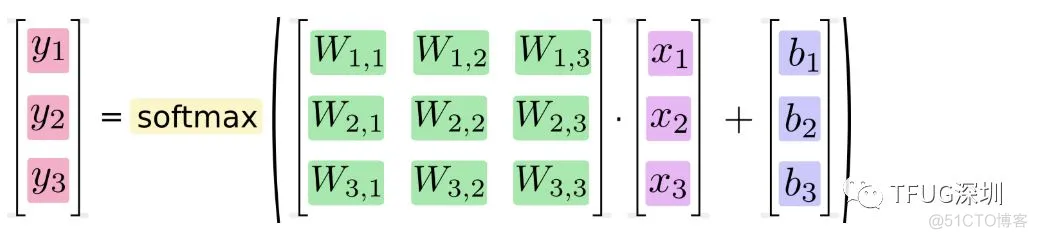
Learnable_Parameters=input*output+bias
第一层:使用'relu' 的256个tensor 的隐藏层:
Learnable_Parameters:200960=784*256 + 256
第二层:使用'relu'的128个tensor 的隐藏层:
Learnable_Parameters:32896=256*128+128
输出层:使用 'softmax' 的 10个 0到1的概率 的 输出层:
Learnable_Parameters :1290=128*10+10
总Learnable_Parameters :
235146=200960+32896+129

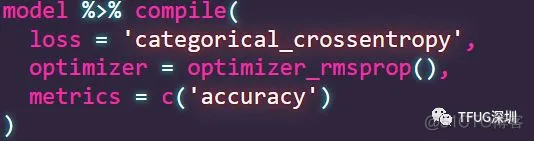
05Complie模型
loss function是categorial_crossentropy
(loss function 是什么?后续文章再聊)
optimizer是optimize_rmsprop
(optimizer 是什么?后续文章再聊)
metrics 为 accuracy,metrics是评估模型的指标。大多数情况都选accuracy。accuracy=正确预测的个数/总预测个数
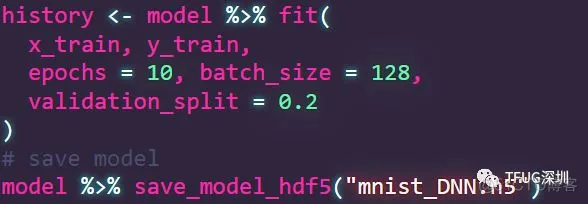
06训练模型 trainning
一堆数据处理转换。模型设计后 。终于可以开始训练模型了。
x_train为训练数据集特征
(6万张照片)
y_train 为训练数据集标签
(6万个数字)
每次读入128张图片。训练10次。
6万张照片80%用来训练。20%用来验证。
训练时间大概为5分钟。
07模型效果 performance
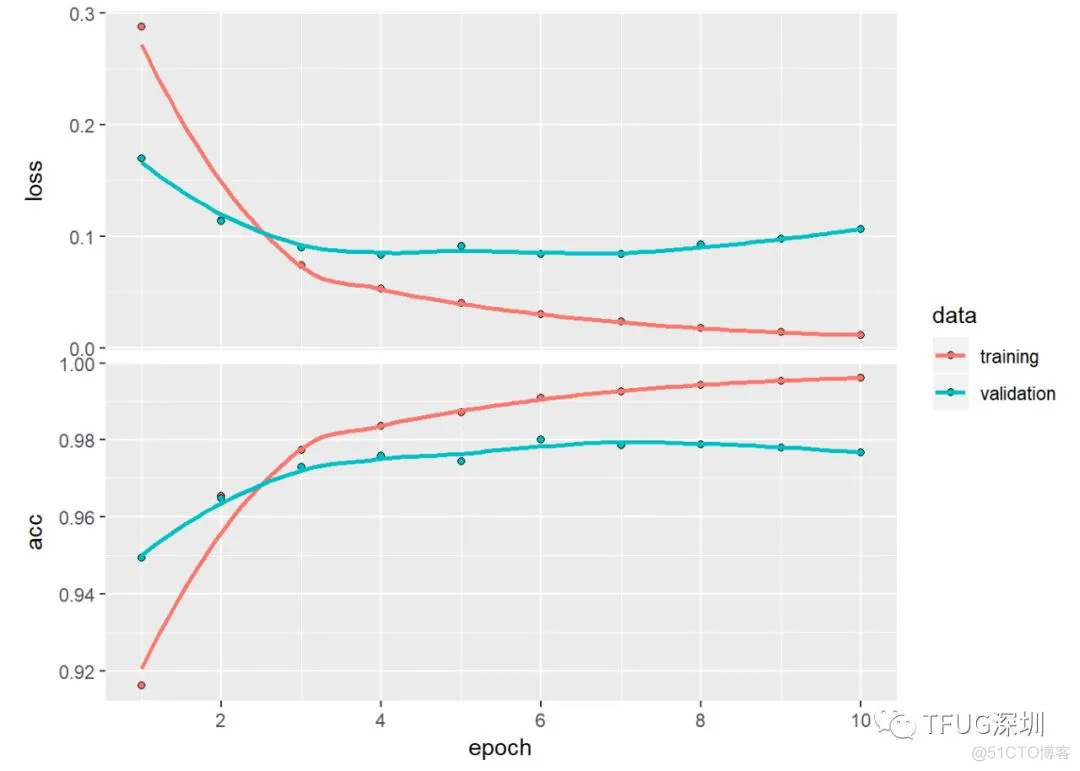
可见 经过 10次训练后。最终在验证集的accuracy表现为97%。从图中可见其实经过6次的训练。在验证集的表现以达到97%

08 模型对比 benchmark
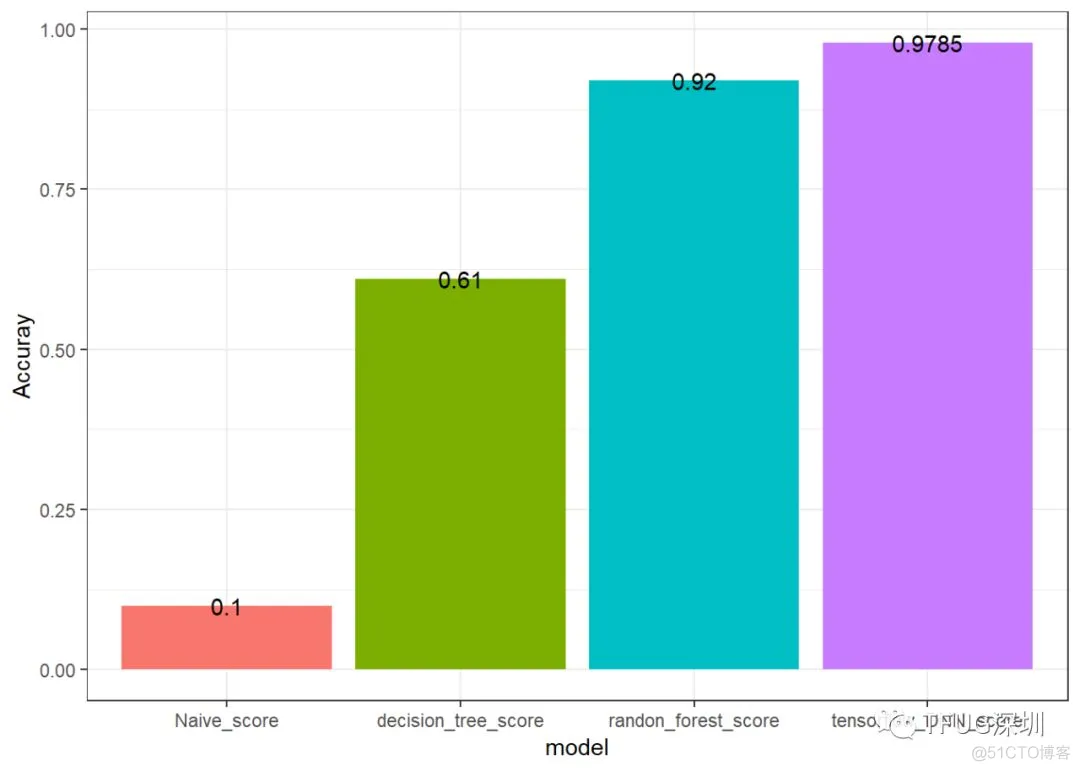
使用决策树模型。准确度是61%。训练时间大概为10分钟。
使用随机森林模型。准确度是92%。训练时间大概为15分钟
tensorflow神经网络模型的准确度是97%

09 总结 summary
使用tensorflow 神经网络模型将准确率提高到97%。可以得到如此高的准确率,主要是图片比较简单。只有0-9的标准数字。对于更加困难的问题。比如在自动驾驶中需要精准的物体识别等问题。将需要更加复杂的神经网络模型。
代码:https://tduan.netlify.com/post/tensorflow-in-r-1-mnist-image-classification/
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















