















































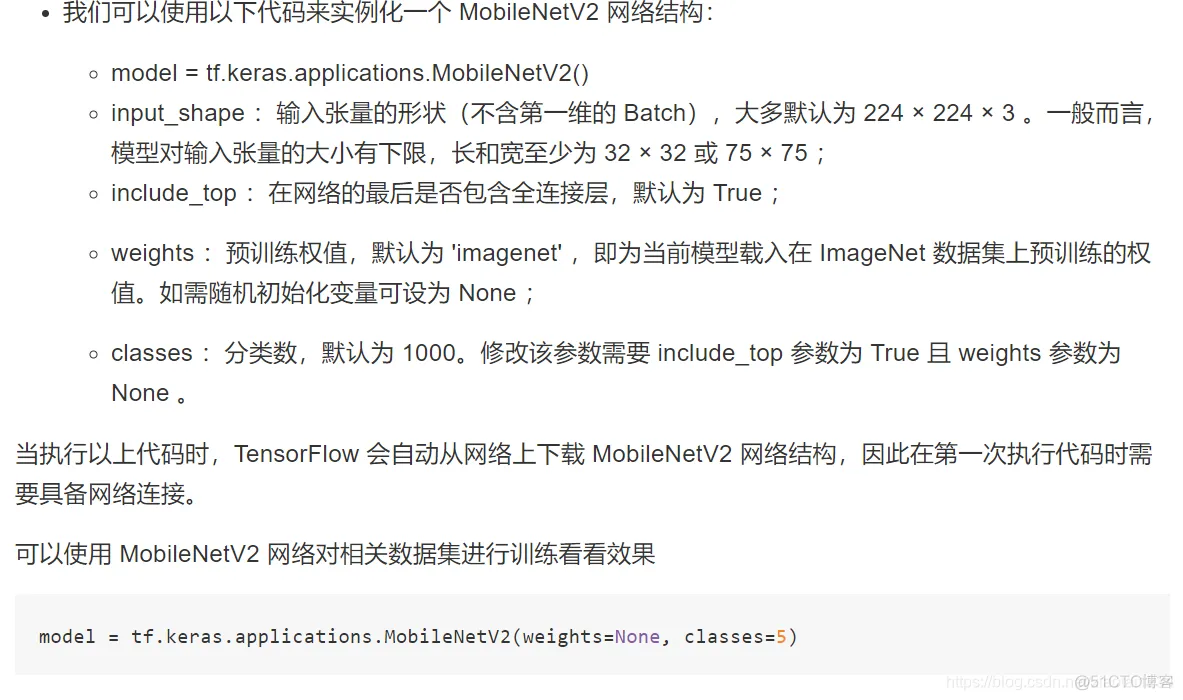
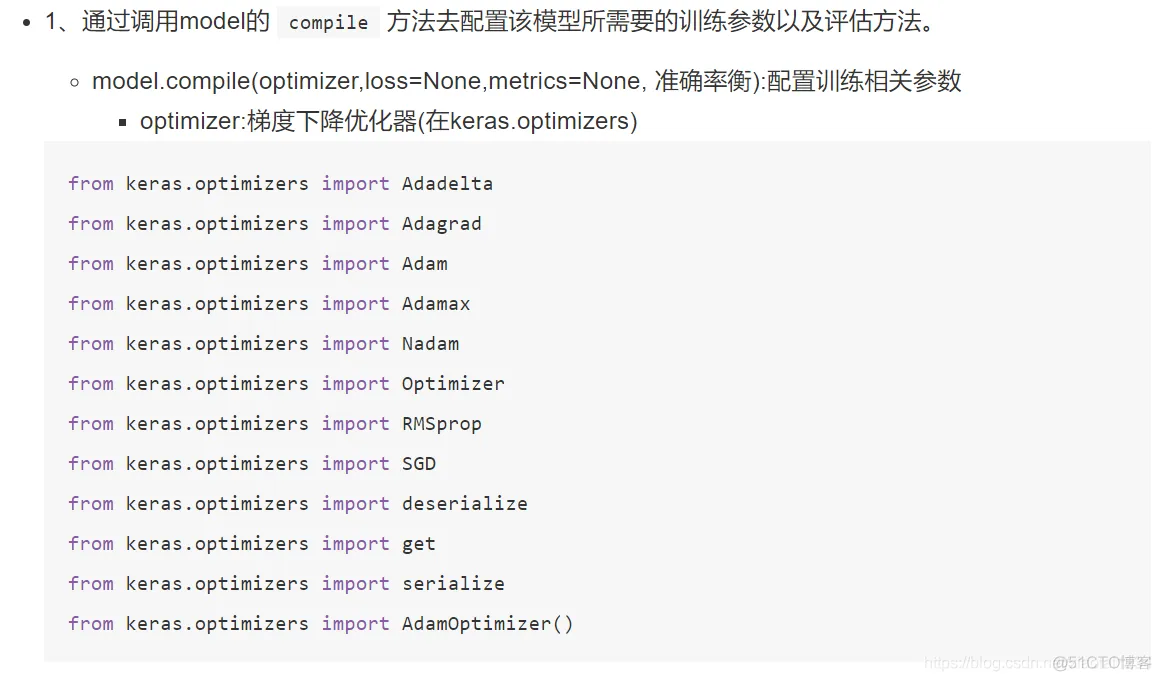
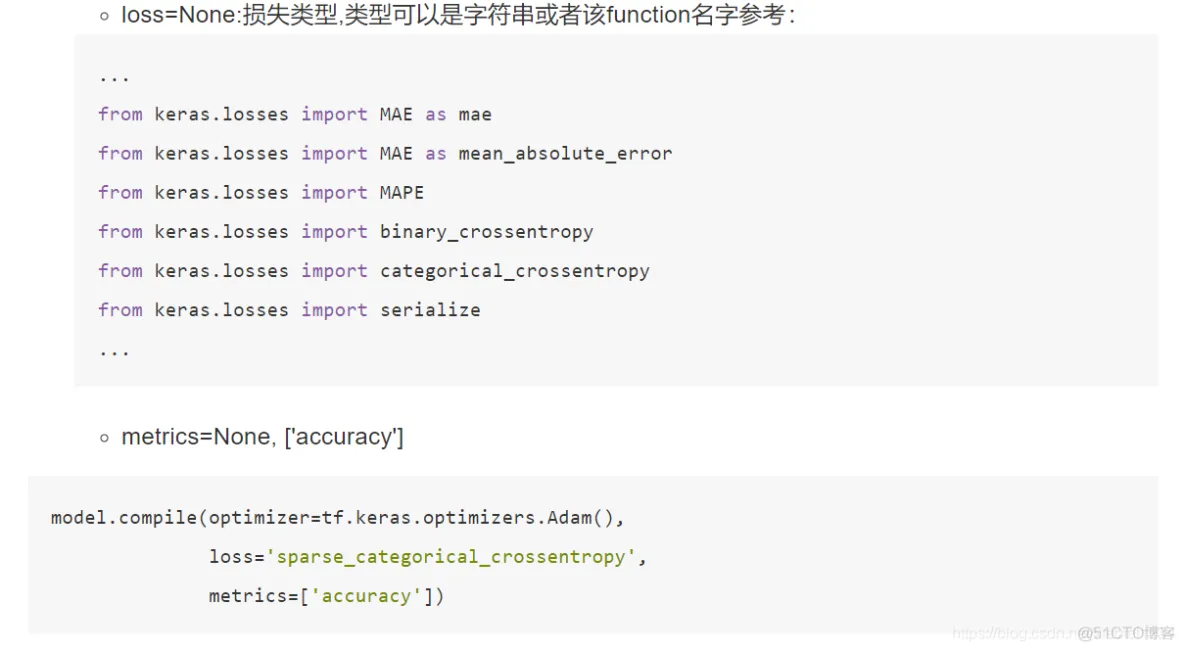
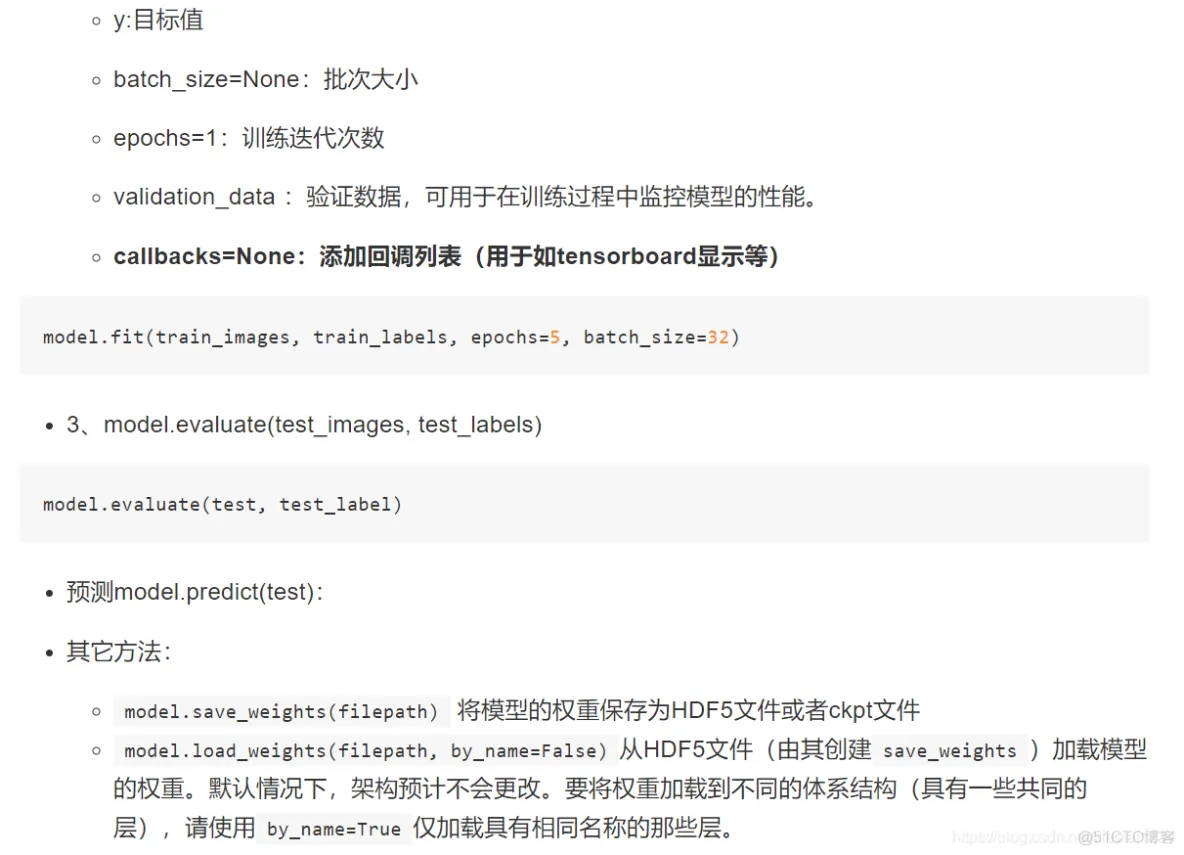
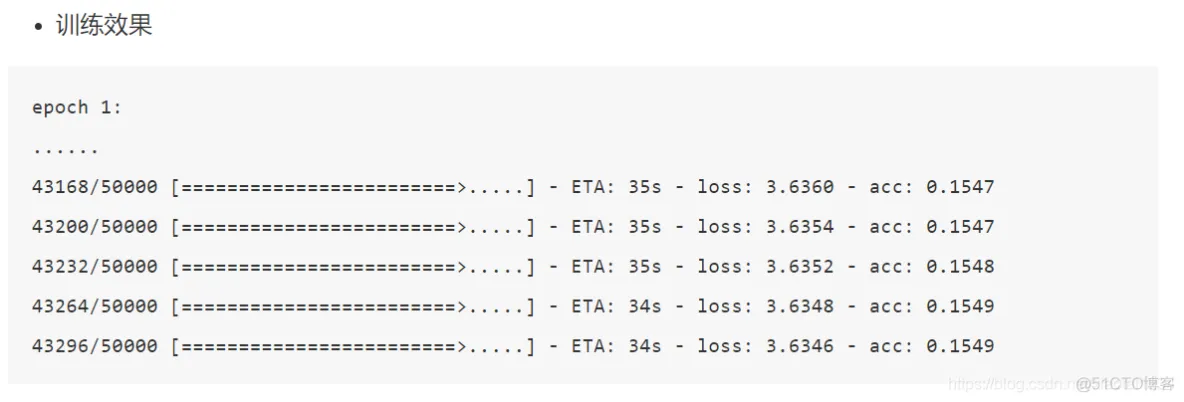
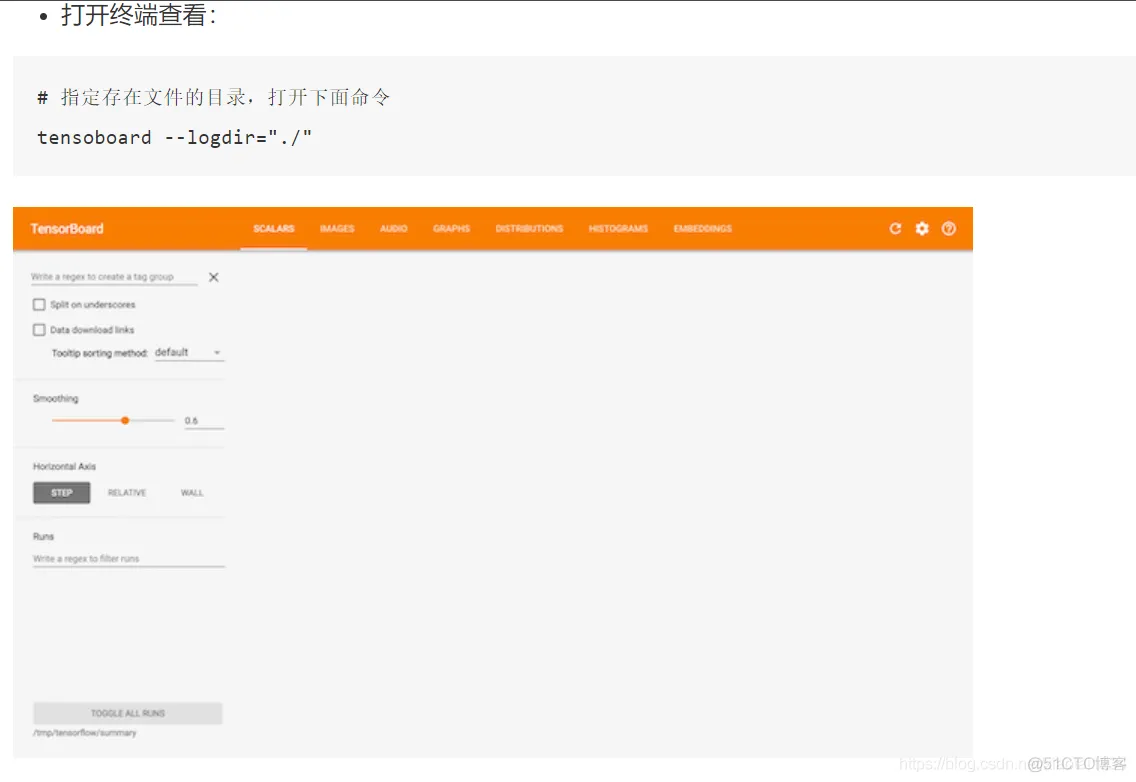
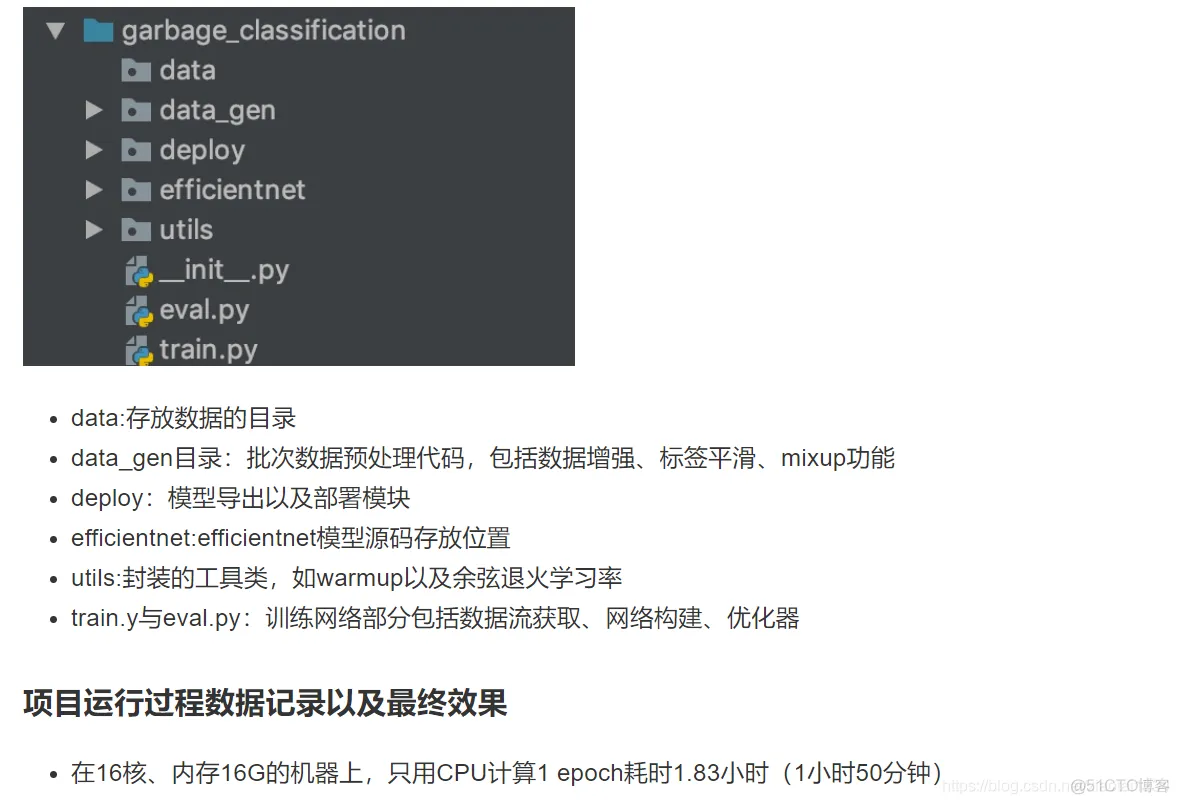
软件

产品



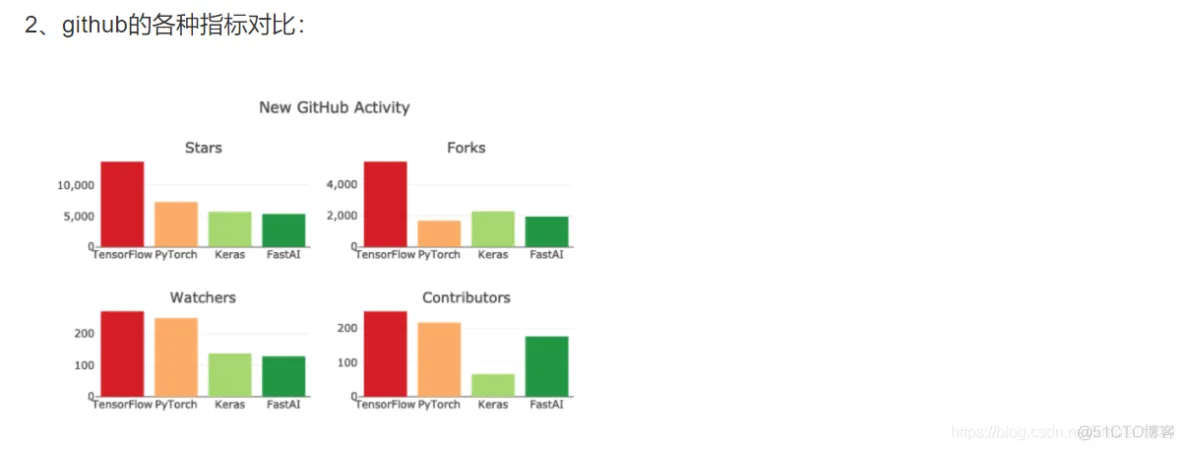
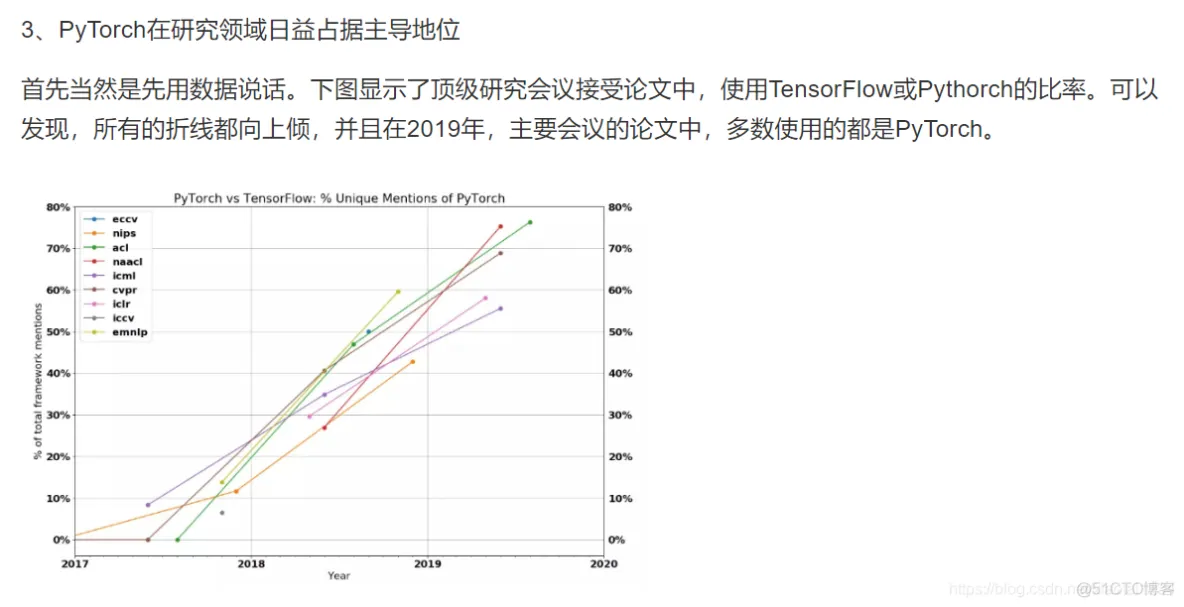
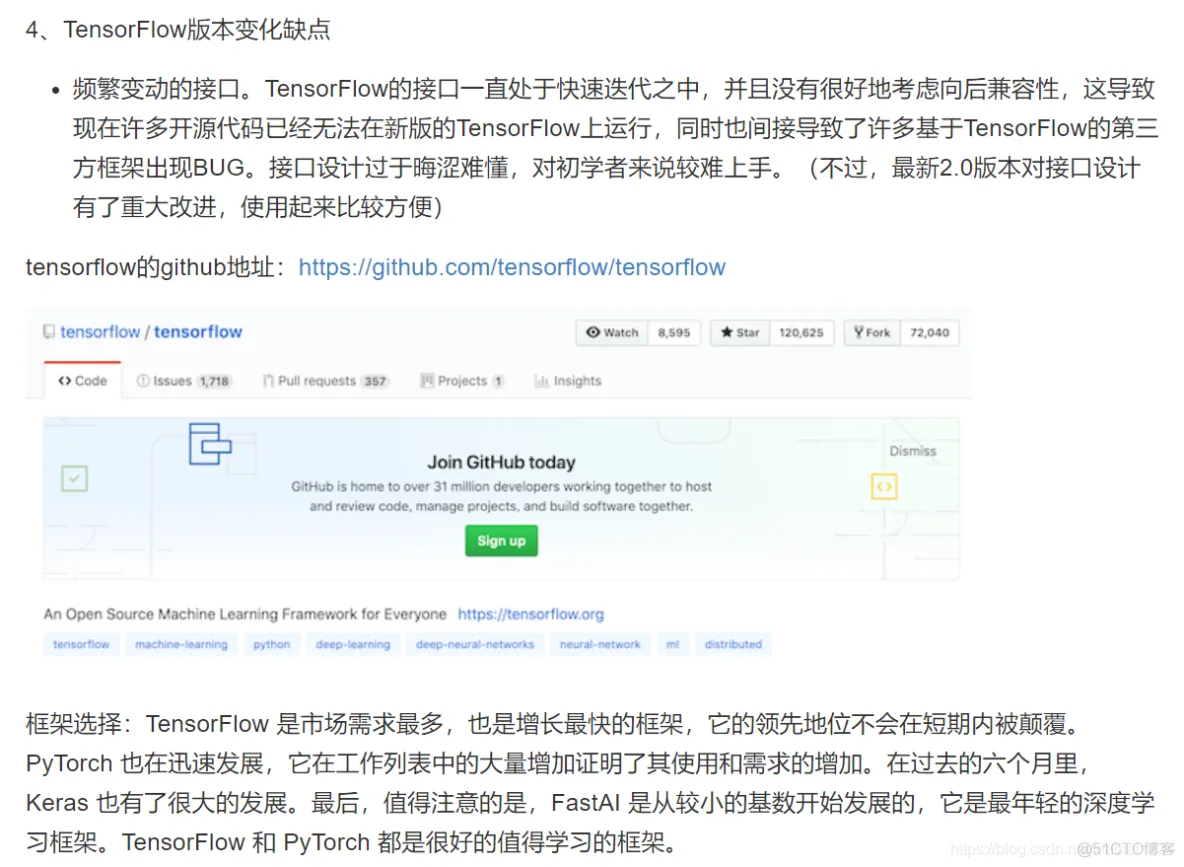






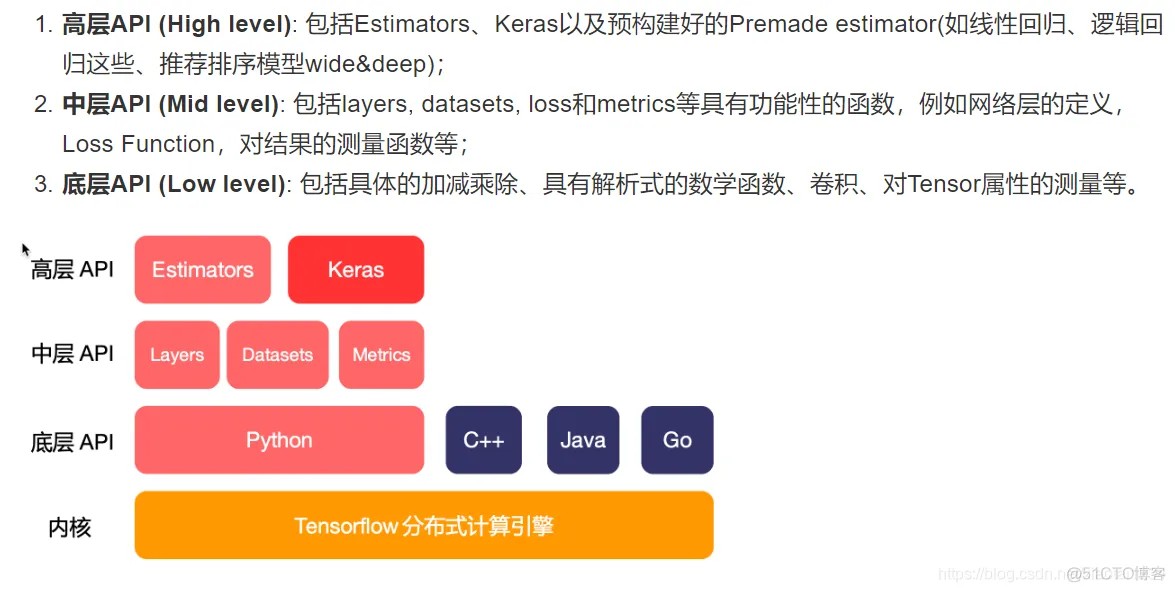



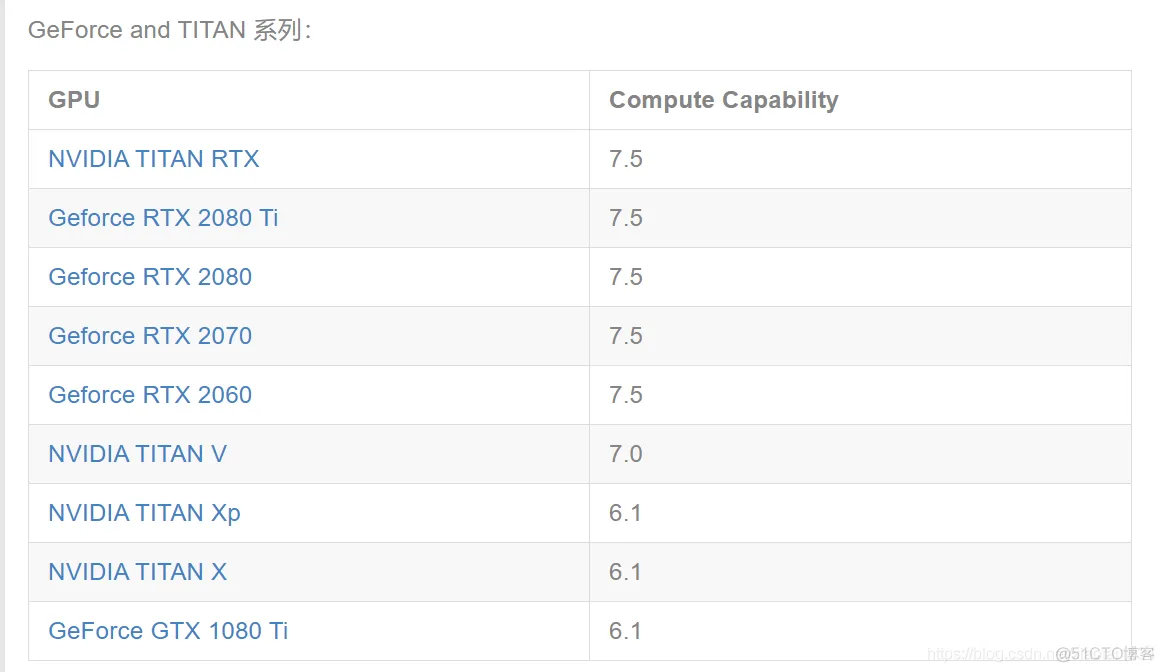
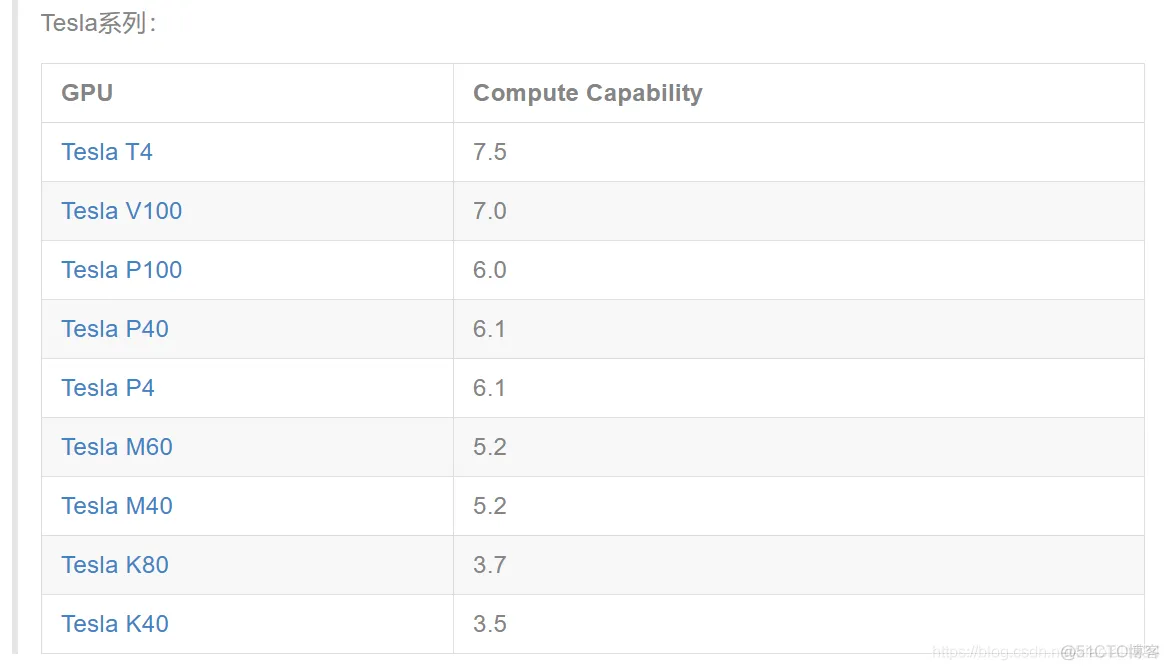




1、默认下载置于用户目录的 `.keras/dataset` 目录下(Windows 下用户目录为 C:\Users\用户名 ,Linux 下用户目录为 `/home/用户名` )
2、mnist = tf.keras.datasets.mnist将从网络上自动下载 MNIST 数据集并加载。如果运行时出现网络连接错误,可以从 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 或 https://s3.amazonaws.com/img-datasets/mnist.npz 下载 MNIST 数据集 mnist.npz文件















对于上面的 y_pred = w * X + b ,我们可以通过模型类的方式编写如下:
import tensorflow as tf
X = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
y = tf.constant([[10.0], [20.0]])
# 1、构建线性模型
class Linear(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense = tf.keras.layers.Dense(
units=1,
activation=None,
kernel_initializer=tf.zeros_initializer(),
bias_initializer=tf.zeros_initializer()
)
def call(self, input):
output = self.dense(input)
return output
# 以下代码结构与前节类似
model = Linear()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for i in range(100):
with tf.GradientTape() as tape:
y_pred = model(X)
loss = 0.5 * tf.reduce_mean(tf.square(y_pred - y))
# 使用 model.variables 这一属性直接获得模型中的所有变量
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
print(model.variables)


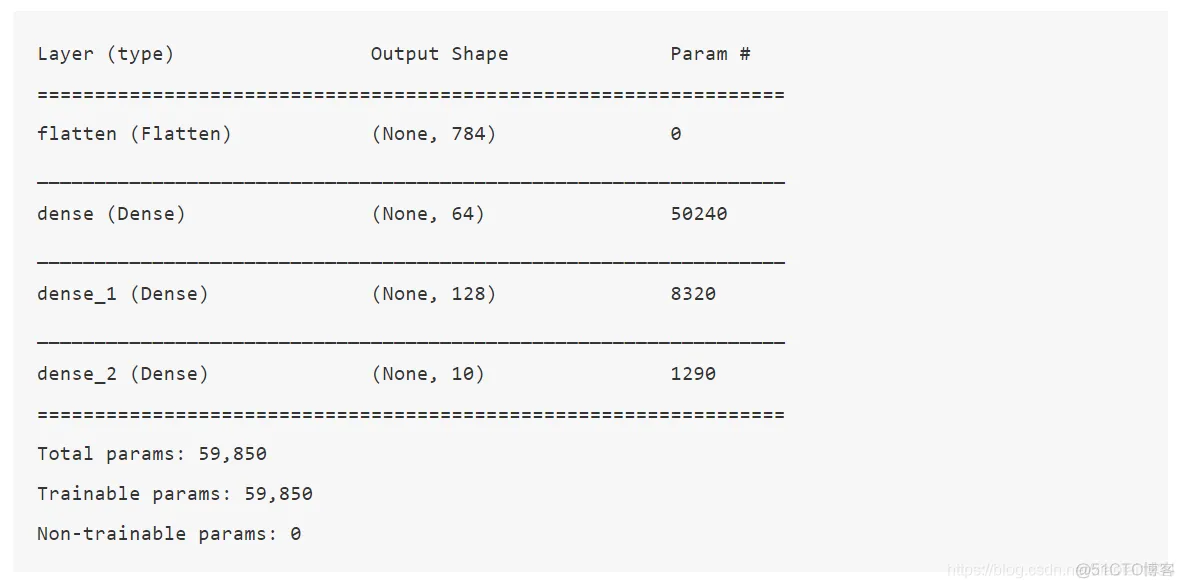
print(model.layers)
[<tensorflow.python.keras.layers.core.Flatten object at 0x10864a780>, <tensorflow.python.keras.layers.core.Dense object at 0x10f95b128>, <tensorflow.python.keras.layers.core.Dense object at 0x125bd6fd0>, <tensorflow.python.keras.layers.core.Dense object at 0x125bf9240>]



import tensorflow as tf
import numpy as np
class MNISTLoader(object):
"""数据加载处理类
"""
def __init__(self):
"""
"""
# 1、获取数据
(self.train_data, self.train_label), (self.test_data, self.test_label) = tf.keras.datasets.mnist.load_data()
# 2、处理数据,归一化,维度以及类型
# MNIST中的图像默认为uint8(0-255的数字)。以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道
# 默认下载是(60000, 28, 28),扩展到四维方便计算理解[60000, 28, 28, 1]
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1)
# [10000, 28, 28, 1]
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1)
self.train_label = self.train_label.astype(np.int32) # [60000]
self.test_label = self.test_label.astype(np.int32) # [10000]
# 获取数据的大小
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
"""
随机获取获取批次数据
:param batch_size: 批次大小
:return:
"""
# 从数据集中随机取出batch_size个元素并返回
index = np.random.randint(0, np.shape(self.train_data)[0], batch_size)
return self.train_data[index, :], self.train_label[index]
if __name__ == '__main__':
mnist = MNISTLoader()
train_data, train_label = mnist.get_batch(50)
print(train_data.shape, train_label)




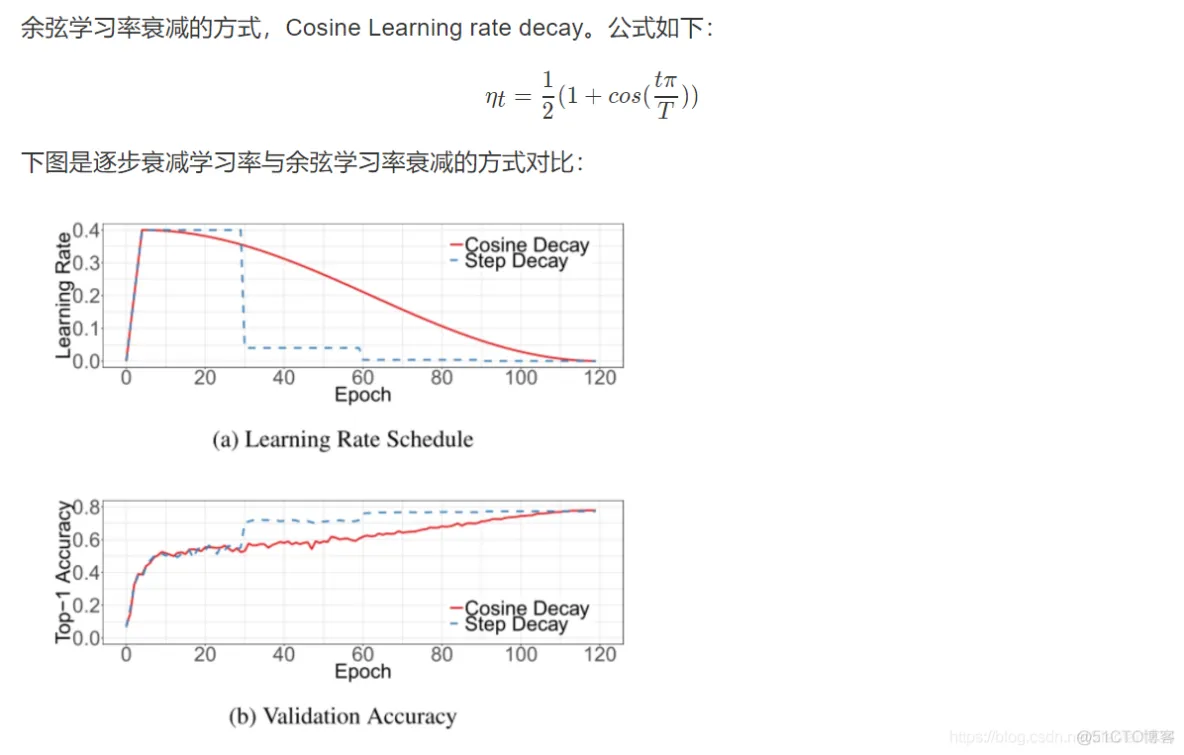
卷积神经网络包含一个或多个卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully-connected Layer)。
卷积神经网络的一个实现现如下所示,新加入了一些卷积层和池化层。当然这个网络可以增加、删除或调整 CNN 的网络结构和参数,以达到更好效果。
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output








1、Numpy array (or array-like), or a list of arrays
2、A TensorFlow tensor, or a list of tensors
3、`tf.data` dataset or a dataset iterator. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`.
4、A generator or `keras.utils.Sequence` returning `(inputs, targets)` or `(inputs, targets, sample weights)`.







def compile(self):
CNNMnist.model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
return None
def fit(self):
CNNMnist.model.fit(self.train, self.train_label, epochs=1, batch_size=32)
return None
def evaluate(self):
test_loss, test_acc = CNNMnist.model.evaluate(self.test, self.test_label)
print(test_loss, test_acc)
return None
if __name__ == '__main__':
cnn = CNNMnist()
cnn.compile()
cnn.fit()
cnn.predict()
print(CNNMnist.model.summary())








class SparseCategoricalAccuracy(tf.keras.metrics.Metric):
def __init__(self):
super().__init__()
self.total = self.add_weight(name='total', dtype=tf.int32, initializer=tf.zeros_initializer())
self.count = self.add_weight(name='count', dtype=tf.int32, initializer=tf.zeros_initializer())
def update_state(self, y_true, y_pred, sample_weight=None):
values = tf.cast(tf.equal(y_true, tf.argmax(y_pred, axis=-1, output_type=tf.int32)), tf.int32)
self.total.assign_add(tf.shape(y_true)[0])
self.count.assign_add(tf.reduce_sum(values))
def result(self):
return self.count / self.total


check = ModelCheckpoint('./ckpt/singlenn_{epoch:02d}-{val_acc:.2f}.h5',
monitor='val_acc',
save_best_only=True,
save_weights_only=True,
mode='auto',
period=1)
SingleNN.model.fit(self.train, self.train_label, epochs=5, callbacks=[check], validation_data=(x, y))
注意:使用ModelCheckpoint一定要在fit当中指定验证集才能使用,否则报错误。











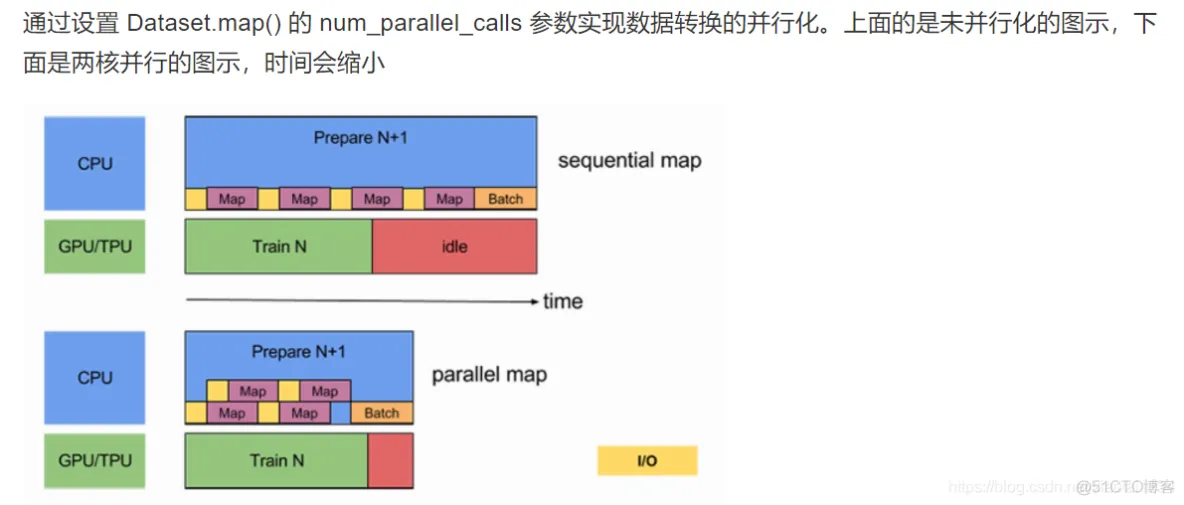
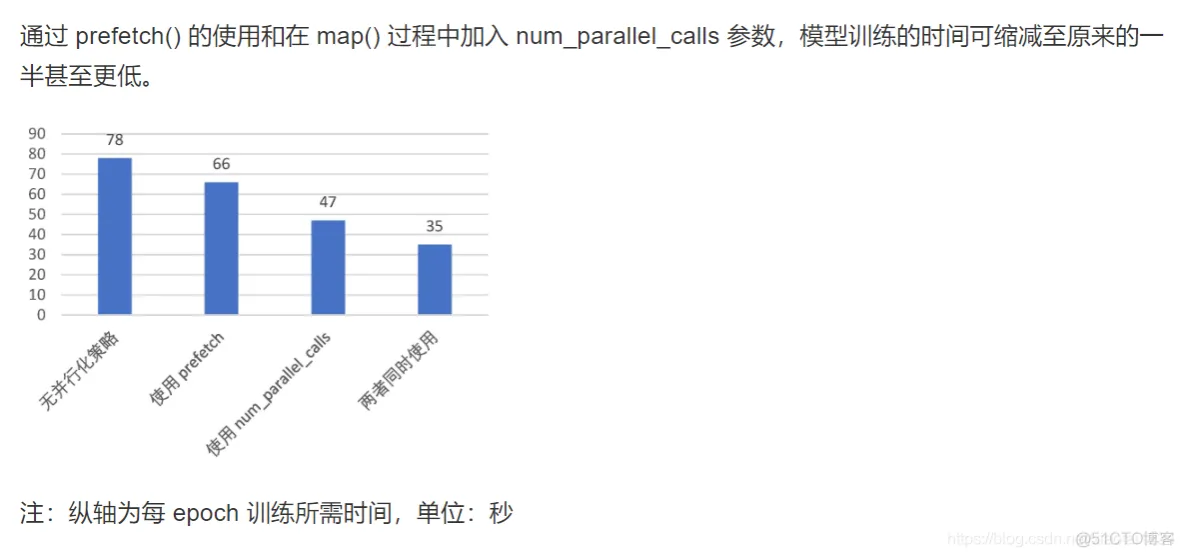
# 添加参数使用,num_parallel_calls 设置为 tf.data.experimental.AUTOTUNE 以让 TensorFlow 自动选择合适的数值
train_dataset = train_dataset.map(
map_func=_decode_and_resize,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
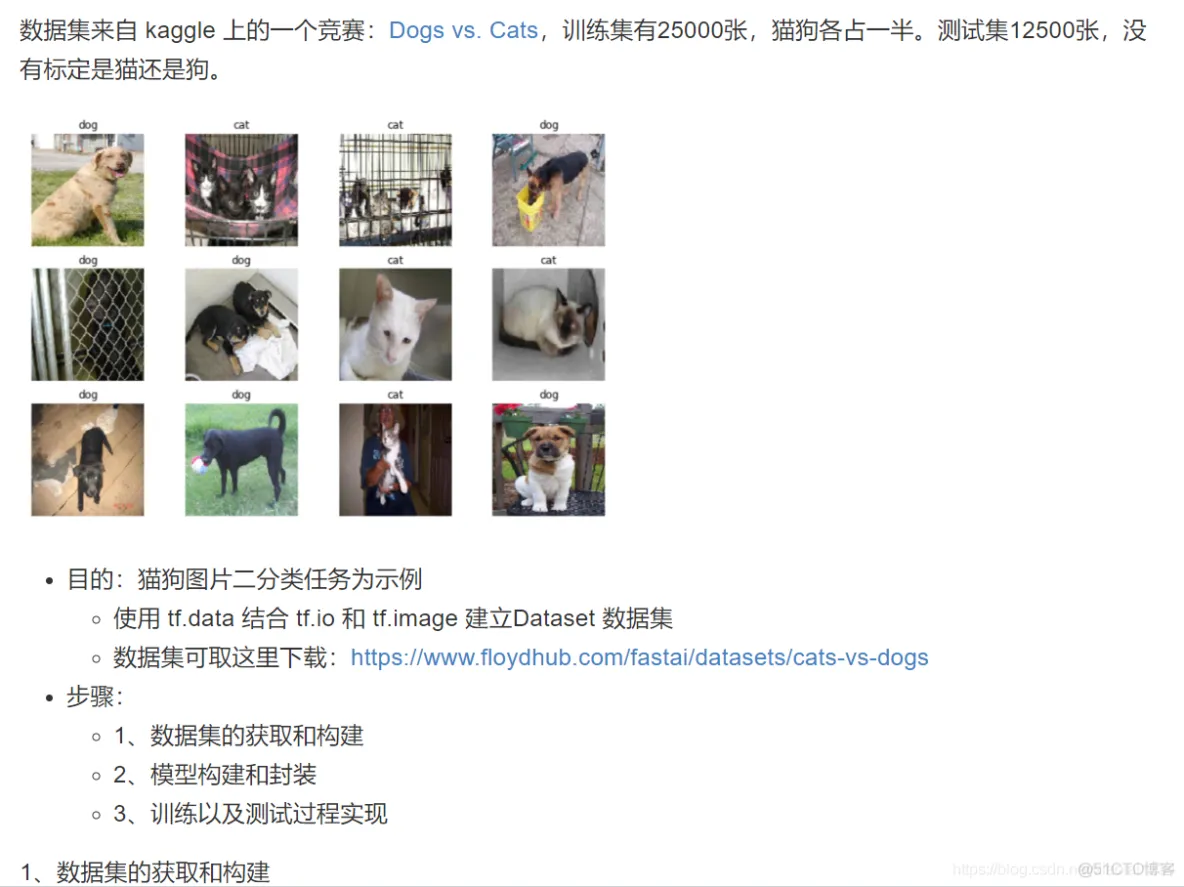
class CatOrDog(object):
"""猫狗分类
"""
num_epochs = 1
batch_size = 32
learning_rate = 0.001
# 训练目录
train_cats_dir = '/root/cv_project/tf_example/cats_vs_dogs/train/cats/'
train_dogs_dir = '/root/cv_project/tf_example/cats_vs_dogs/train/dogs/'
# 验证目录
test_cats_dir = '/root/cv_project/tf_example/cats_vs_dogs/valid/cats/'
test_dogs_dir = '/root/cv_project/tf_example/cats_vs_dogs/valid/dogs/'
def __init__(self):
# 1、读取训练集的猫狗文件
self.train_cat_filenames = tf.constant([CatOrDog.train_cats_dir + filename
for filename in os.listdir(CatOrDog.train_cats_dir)])
self.train_dog_filenames = tf.constant([CatOrDog.train_dogs_dir + filename
for filename in os.listdir(CatOrDog.train_dogs_dir)])
# 2、猫狗文件列表合并,并且初始化猫狗的目标值,0为猫,1为狗
self.train_filenames = tf.concat([self.train_cat_filenames, self.train_dog_filenames], axis=-1)
self.train_labels = tf.concat([
tf.zeros(self.train_cat_filenames.shape, dtype=tf.int32),
tf.ones(self.train_dog_filenames.shape, dtype=tf.int32)],
axis=-1)
定义数据的获取方法,通过tf.data指定
def get_batch(self):
"""获取dataset批次数据
:return:
"""
train_dataset = tf.data.Dataset.from_tensor_slices((self.train_filenames, self.train_labels))
# 进行数据的map, 随机,批次和预存储
train_dataset = train_dataset.map(
map_func=_decode_and_resize,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_dataset = train_dataset.shuffle(buffer_size=20000)
train_dataset = train_dataset.batch(CatOrDog.batch_size)
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
return train_dataset
# 图片处理函数,读取,解码并且进行输入形状修改
def _decode_and_resize(filename, label):
image_string = tf.io.read_file(filename)
image_decoded = tf.image.decode_jpeg(image_string)
image_resized = tf.image.resize(image_decoded, [256, 256]) / 255.0
return image_resized, label

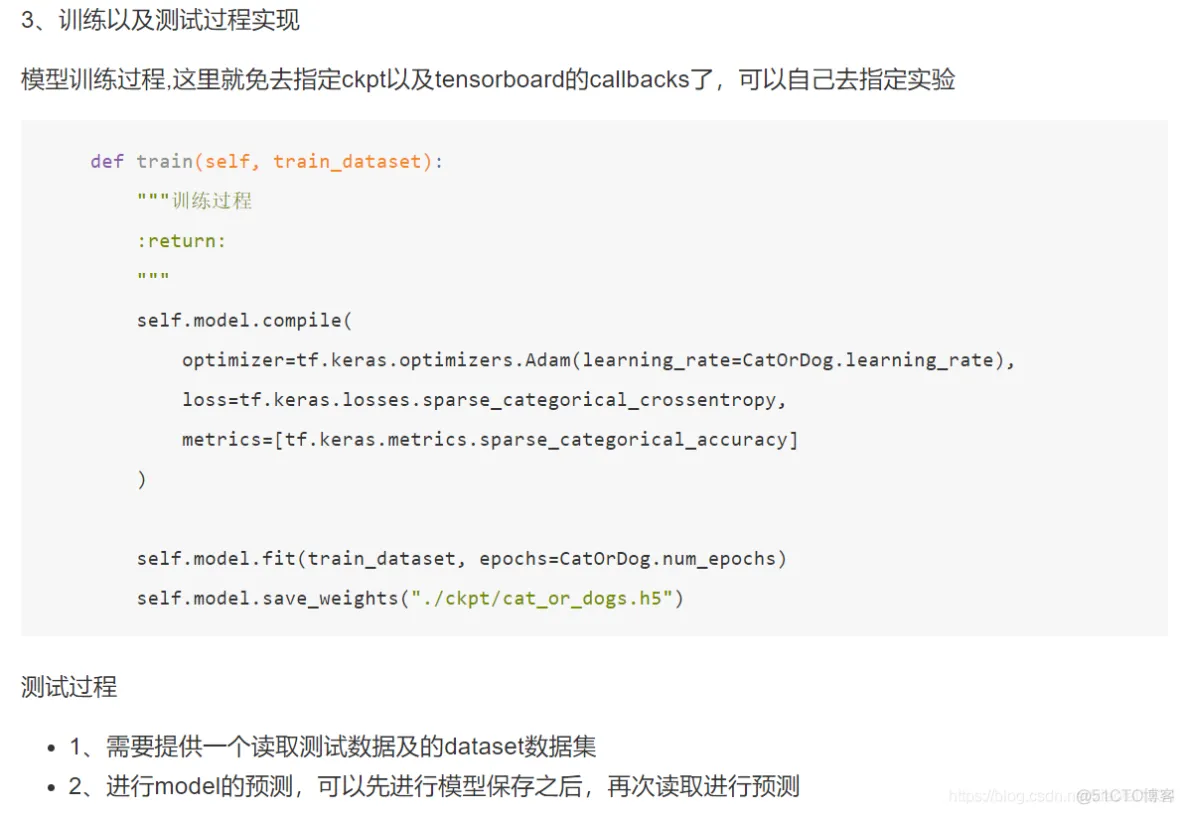
def test(self):
# 1、构建测试数据集
test_cat_filenames = tf.constant([CatOrDog.test_cats_dir + filename
for filename in os.listdir(CatOrDog.test_cats_dir)])
test_dog_filenames = tf.constant([CatOrDog.test_dogs_dir + filename
for filename in os.listdir(CatOrDog.test_dogs_dir)])
test_filenames = tf.concat([test_cat_filenames, test_dog_filenames], axis=-1)
test_labels = tf.concat([
tf.zeros(test_cat_filenames.shape, dtype=tf.int32),
tf.ones(test_dog_filenames.shape, dtype=tf.int32)],
axis=-1)
# 2、构建dataset
test_dataset = tf.data.Dataset.from_tensor_slices((test_filenames, test_labels))
test_dataset = test_dataset.map(_decode_and_resize)
test_dataset = test_dataset.batch(batch_size)
# 3、加载模型进行评估
if os.path.exists("./ckpt/cat_or_dogs.h5"):
self.model.load_weights("./ckpt/cat_or_dogs.h5")
print(self.model.metrics_names)
print(self.model.evaluate(test_dataset))

tf.keras.preprocessing.image.ImageDataGenerator(featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
zca_epsilon=1e-06,
rotation_range=0,
width_shift_range=0.0,
height_shift_range=0.0,
brightness_range=None,
shear_range=0.0,
zoom_range=0.0,
channel_shift_range=0.0,
fill_mode='nearest',
cval=0.0,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=None,
validation_split=0.0,
dtype=None)

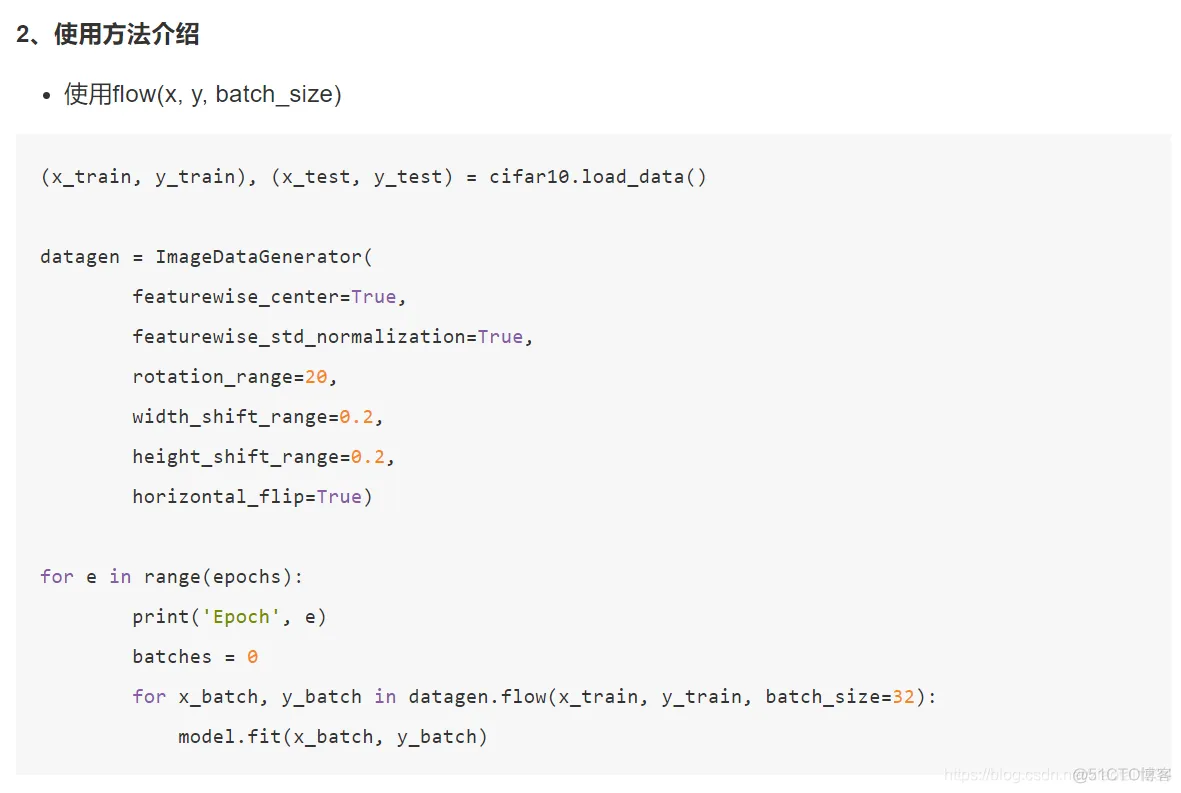



Epoch 1/2
1/13 [=>............................] - ETA: 3:20 - loss: 1.6811 - acc: 0.1562
2/13 [===>..........................] - ETA: 3:01 - loss: 1.5769 - acc: 0.2500
3/13 [=====>........................] - ETA: 2:44 - loss: 1.4728 - acc: 0.3958
4/13 [========>.....................] - ETA: 2:27 - loss: 1.3843 - acc: 0.4531
5/13 [==========>...................] - ETA: 2:14 - loss: 1.3045 - acc: 0.4938
6/13 [============>.................] - ETA: 1:58 - loss: 1.2557 - acc: 0.5156
7/13 [===============>..............] - ETA: 1:33 - loss: 1.1790 - acc: 0.5759
8/13 [=================>............] - ETA: 1:18 - loss: 1.1153 - acc: 0.6211
9/13 [===================>..........] - ETA: 1:02 - loss: 1.0567 - acc: 0.6562
10/13 [======================>.......] - ETA: 46s - loss: 1.0043 - acc: 0.6875
11/13 [========================>.....] - ETA: 31s - loss: 0.9580 - acc: 0.7159
12/13 [==========================>...] - ETA: 15s - loss: 0.9146 - acc: 0.7344
13/13 [==============================] - 249s 19s/step - loss: 0.8743 - acc: 0.7519 - val_loss: 0.3906 - val_acc: 0.9000
Epoch 2/2
1/13 [=>............................] - ETA: 2:56 - loss: 0.3862 - acc: 1.0000
2/13 [===>..........................] - ETA: 2:44 - loss: 0.3019 - acc: 1.0000
3/13 [=====>........................] - ETA: 2:35 - loss: 0.2613 - acc: 1.0000
4/13 [========>.....................] - ETA: 2:01 - loss: 0.2419 - acc: 0.9844
5/13 [==========>...................] - ETA: 1:49 - loss: 0.2644 - acc: 0.9688
6/13 [============>.................] - ETA: 1:36 - loss: 0.2494 - acc: 0.9688
7/13 [===============>..............] - ETA: 1:24 - loss: 0.2362 - acc: 0.9732
8/13 [=================>............] - ETA: 1:10 - loss: 0.2234 - acc: 0.9766
9/13 [===================>..........] - ETA: 58s - loss: 0.2154 - acc: 0.9757
10/13 [======================>.......] - ETA: 44s - loss: 0.2062 - acc: 0.9781
11/13 [========================>.....] - ETA: 29s - loss: 0.2007 - acc: 0.9801
12/13 [==========================>...] - ETA: 14s - loss: 0.1990 - acc: 0.9792
13/13 [==============================] - 243s 19s/step - loss: 0.1923 - acc: 0.9809 - val_loss: 0.1929 - val_acc: 0.9300


基于上面工具的读取代码
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
'data/train',
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
'data/validation',
target_size=(150, 150),
batch_size=32,
class_mode='binary')
# 使用fit_generator
model.fit_generator(
train_generator,
steps_per_epoch=2000,
epochs=50,
validation_data=validation_generator,
validation_steps=800)
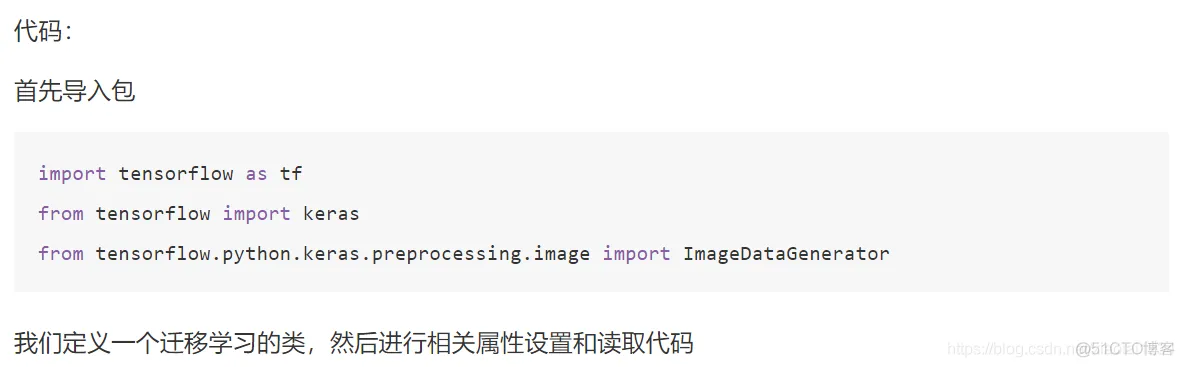
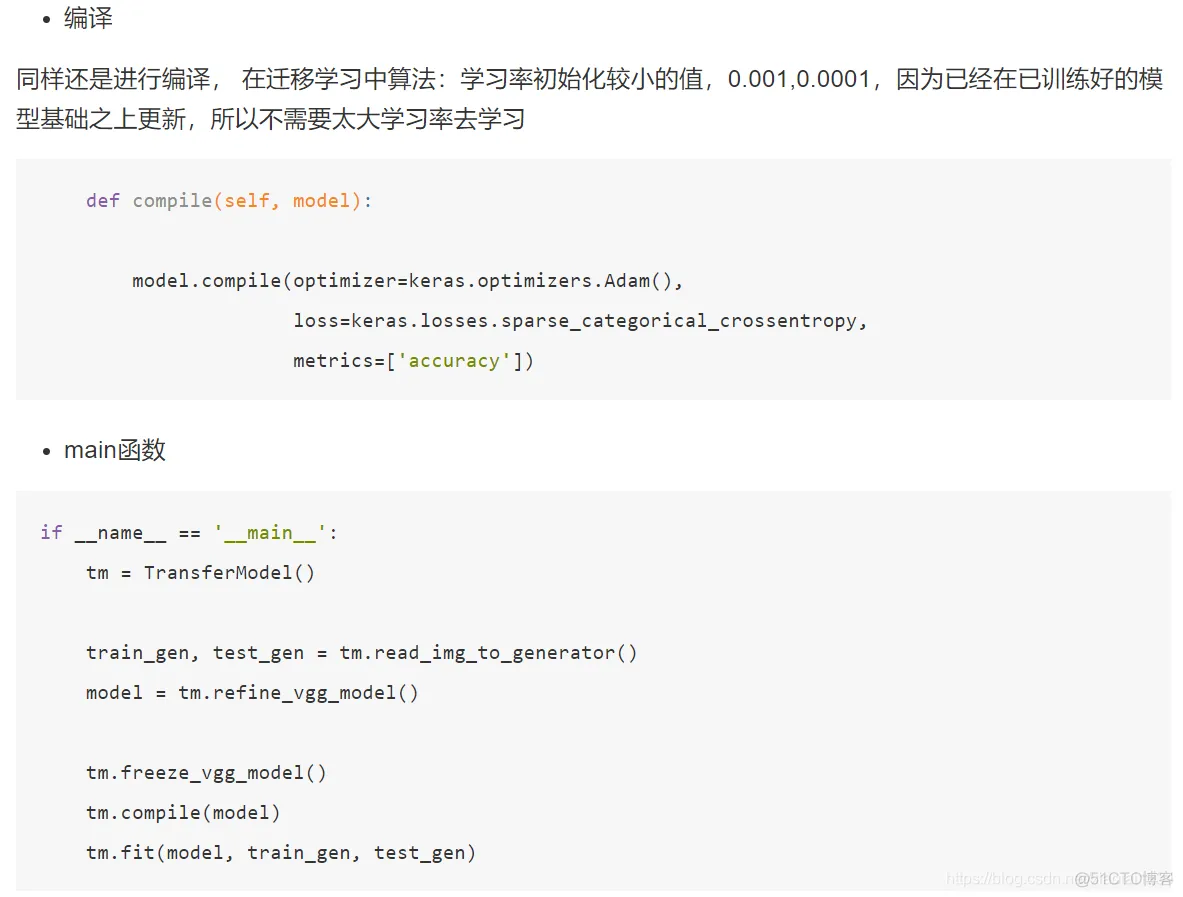
class TransferModel(object):
def __init__(self):
self.model_size = (224, 224)
self.train_dir = "./data/train/"
self.test_dir = "./data/test/"
self.batch_size = 32
self.train_generator = ImageDataGenerator(rescale=1.0 / 255)
self.test_generator = ImageDataGenerator(rescale=1.0 / 255)
def read_img_to_generator(self):
"""
读取本地固定格式数据
:return:
"""
train_gen = self.train_generator.flow_from_directory(directory=self.train_dir,
target_size=self.model_size,
batch_size=self.batch_size,
class_mode='binary',
shuffle=True)
test_gen = self.test_generator.flow_from_directory(directory=self.test_dir,
target_size=self.model_size,
batch_size=self.batch_size,
class_mode='binary',
shuffle=True)
return train_gen, test_gen



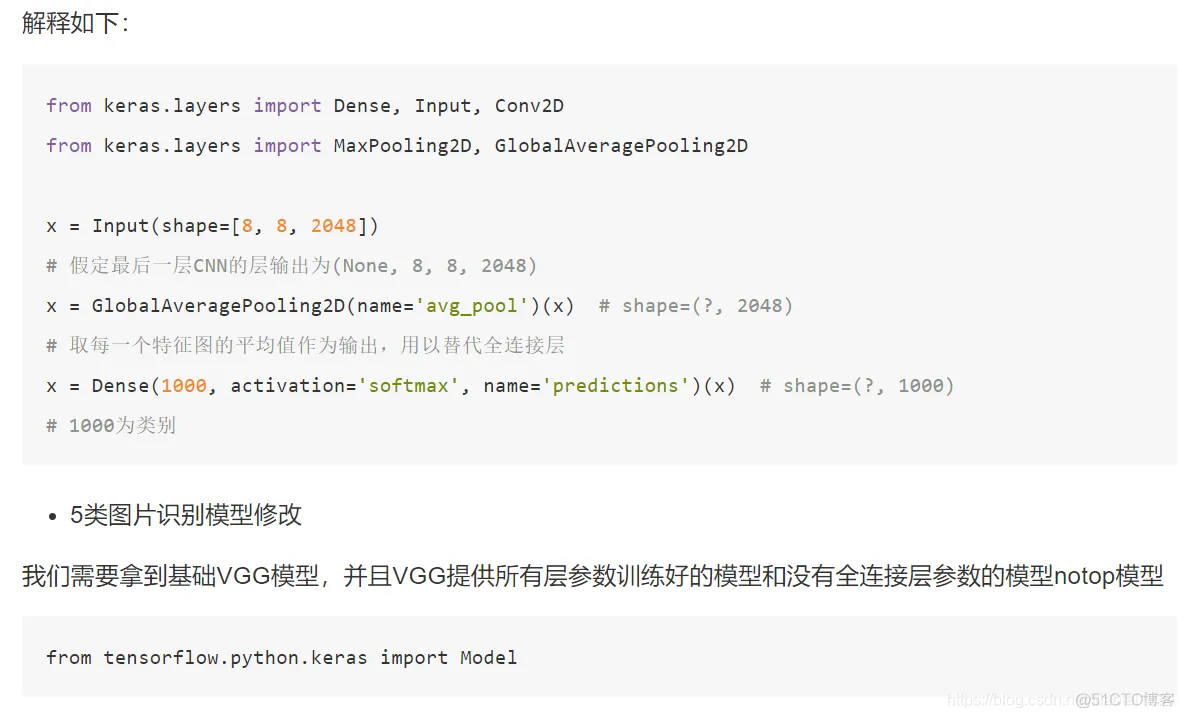


预测的步骤就是读取图片以及处理到模型中预测,加载我们训练的模型
def predict(self, model):
model.load_weights("./Transfer.h5")
# 2、对图片进行加载和类型修改
image = load_img("./data/test/dinosaurs/402.jpg", target_size=(224, 224))
print(image)
# 转换成numpy array数组
image = img_to_array(image)
print("图片的形状:", image.shape)
# 形状从3维度修改成4维
img = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
print("改变形状结果:", img.shape)
# 3、处理图像内容,归一化处理等,进行预测
img = preprocess_input(img)
print(img.shape)
y_predict = model.predict(img)
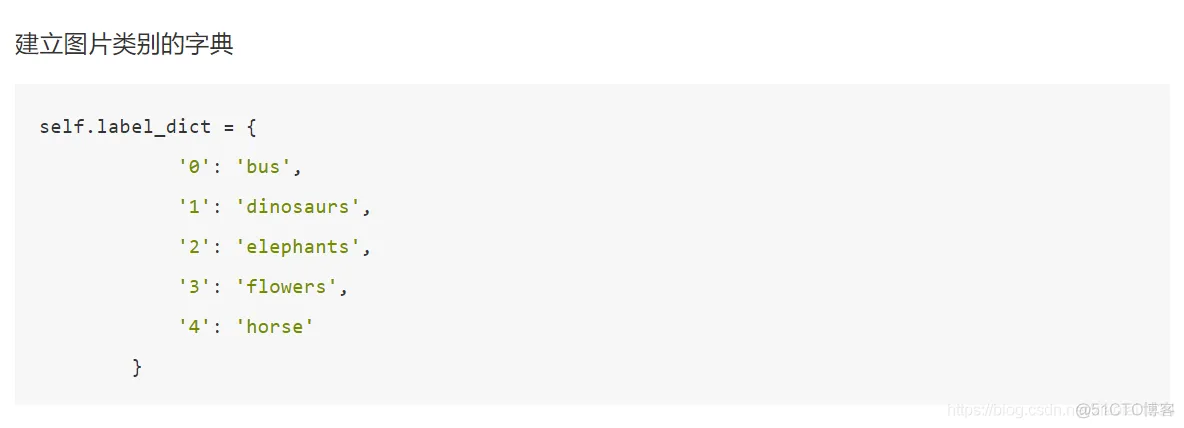
index = np.argmax(y_predict, axis=1)
print(self.label_dict[str(index[0])])



注:实际上,Eager Execution 在 1.x 的后期版本中也存在,但需要单独执行 tf.enable_eager_execution() 进行手动启用。


import tensorflow as tf
@tf.function
def train_one_step(X, y):
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
# 注意这里使用了TensorFlow内置的tf.print()
# @tf.function不支持Python内置的print方法去当做计算节点
tf.print("loss", loss)
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
if __name__ == '__main__':
model = CNN()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
start_time = time.time()
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
train_one_step(X, y)
end_time = time.time()
print(end_time - start_time)

import tensorflow as tf
import numpy as np
@tf.function
def f(x):
# 注意这里是print,不是tf.print
print("The function is running in Python")
tf.print(x)
# 运行过程
a = tf.constant(1, dtype=tf.int32)
f(a)
b = tf.constant(2, dtype=tf.int32)
f(b)
b_array = np.array(2, dtype=np.int32)
f(b_array)
c = tf.constant(0.1, dtype=tf.float32)
f(c)
d = tf.constant(0.2, dtype=tf.float32)
f(d)
# 对于Python的类型
f(1)
f(2)
f(1)
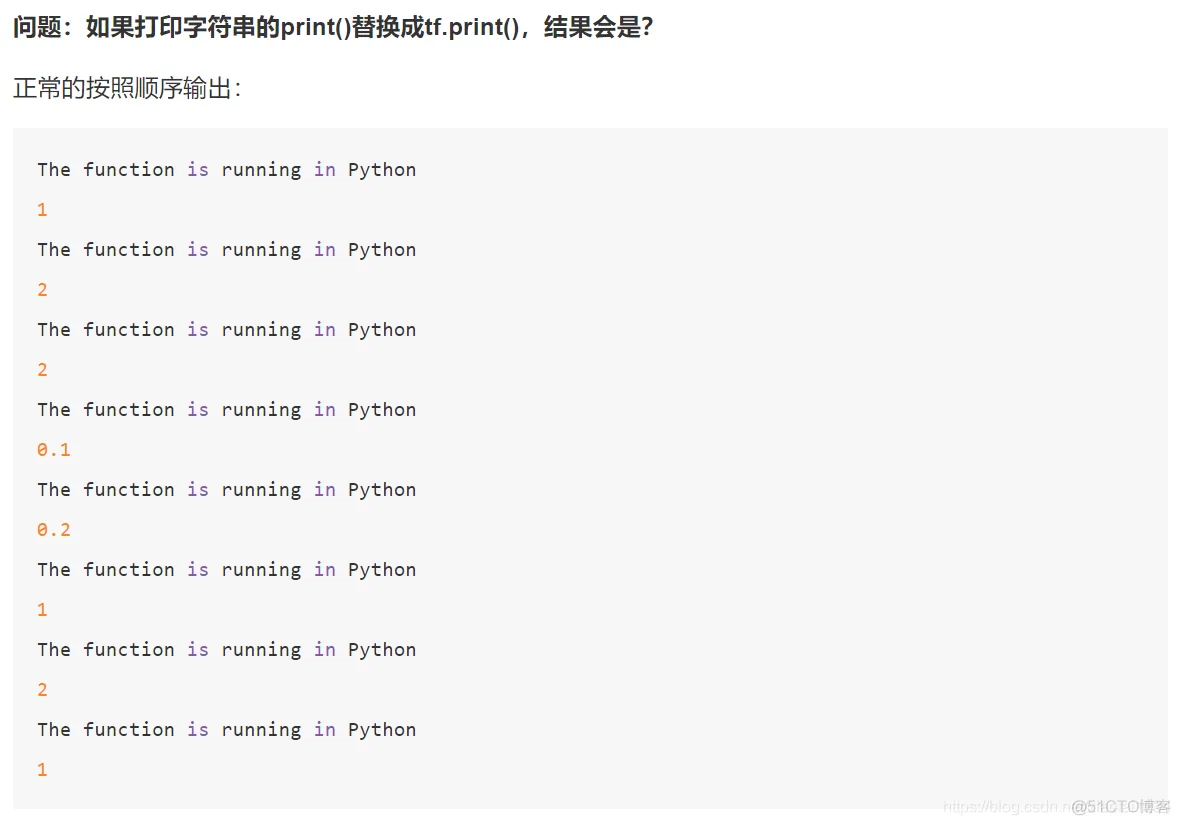
上述程序的计算结果是?答案是: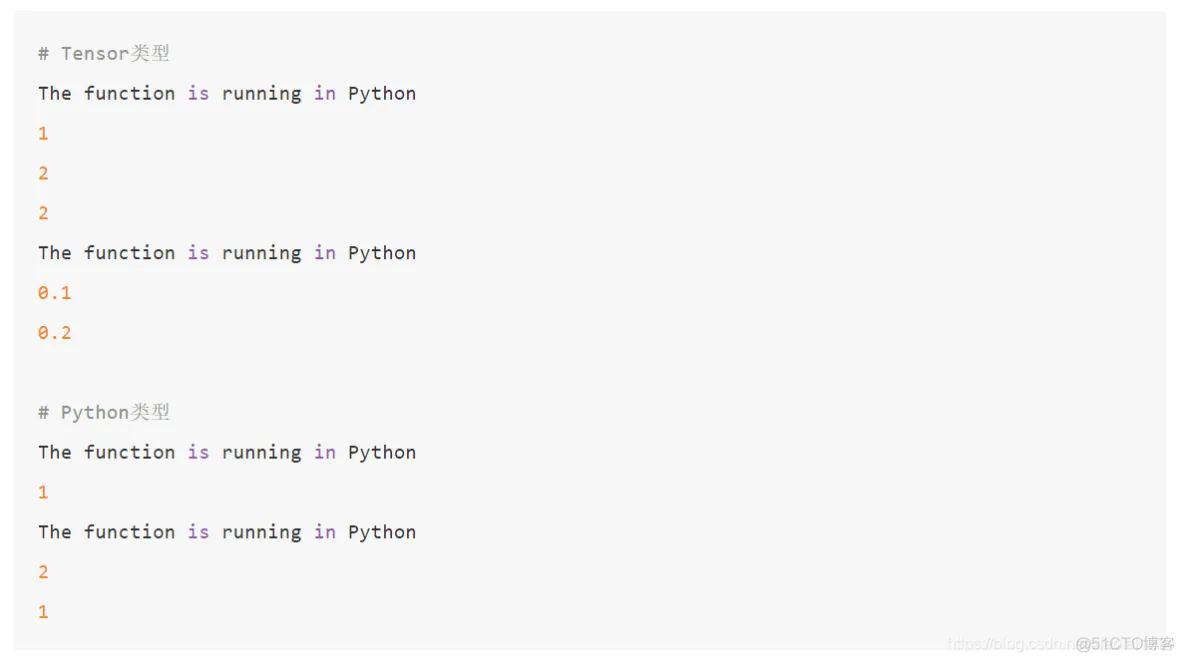



optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
# 1、建立计算图
X_placeholder = tf.compat.v1.placeholder(name='X', shape=[None, 28, 28, 1], dtype=tf.float32)
y_placeholder = tf.compat.v1.placeholder(name='y', shape=[None], dtype=tf.int32)
y_pred = model(X_placeholder)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y_placeholder, y_pred=y_pred)
loss = tf.reduce_mean(loss)
train_op = optimizer.minimize(loss)
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# 2、建立Session,并运行图计算
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
# 使用Session.run()将数据送入计算图节点,进行训练以及计算损失函数
_, loss_value = sess.run([train_op, loss], feed_dict={X_placeholder: X, y_placeholder: y})
print("batch %d: loss %f" % (batch_index, loss_value))
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict(data_loader.test_data[start_index: end_index])
# 运行预测结果
sess.run(sparse_categorical_accuracy.update(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred))
print("test accuracy: %f" % sess.run(sparse_categorical_accuracy.result()))


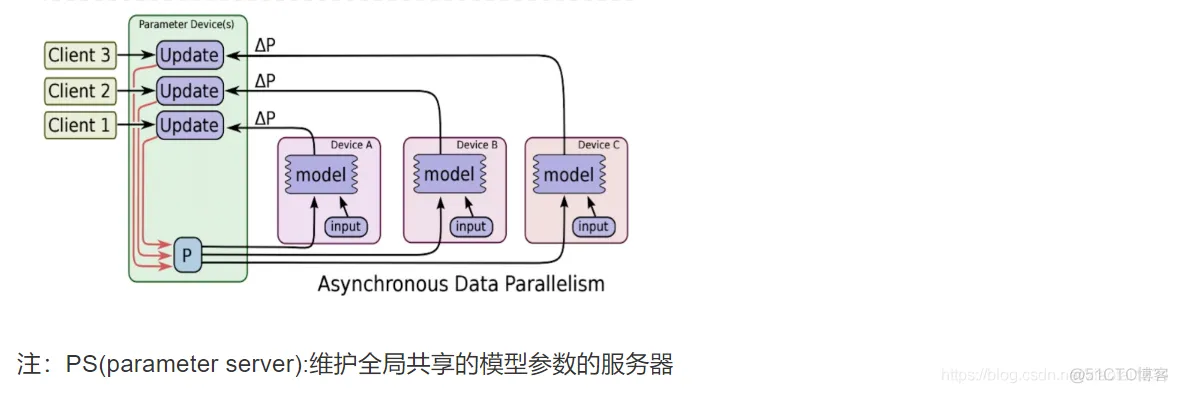

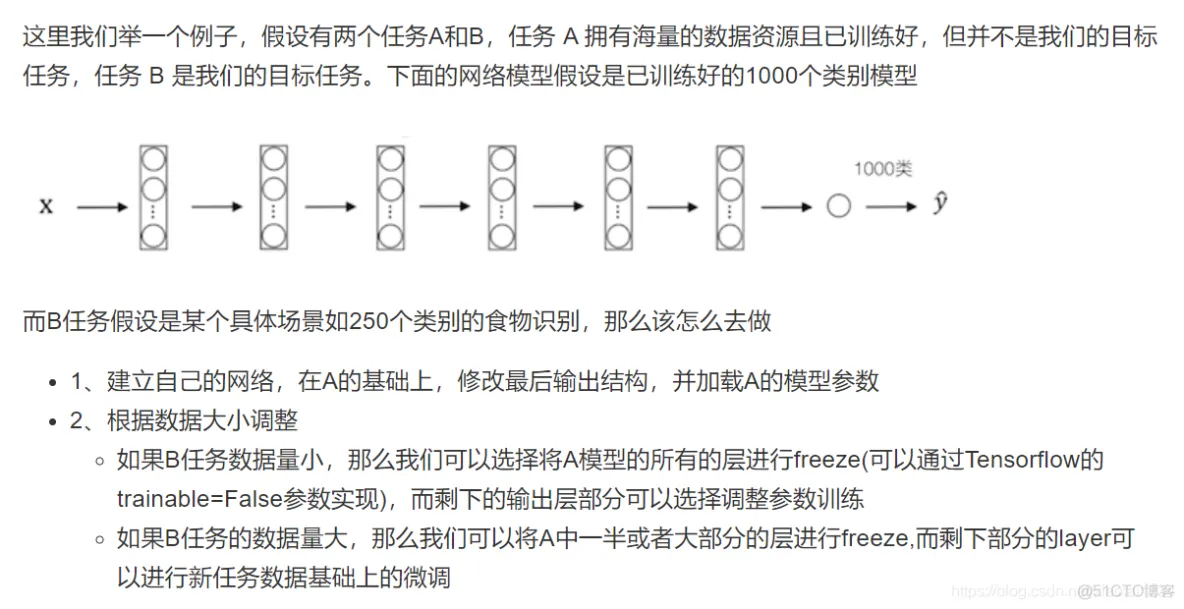
TensorFlow多机多卡实现思路。多级多卡的分布式有很多实现方式,比如:
1. 将每个GPU当做一个worker
2. 同一个机器的各个GPU进行图内并行
3. 同一个机器的各个GPU进行图间并行
比如说第三种:模型实现封装成函数、将数据分成GPU数量的份数、在每个GPU下,进行一次模型forward计算,并使用优化器算出梯度、reduce每个GPU下的梯度,并将梯度传入到分布式中的优化器中

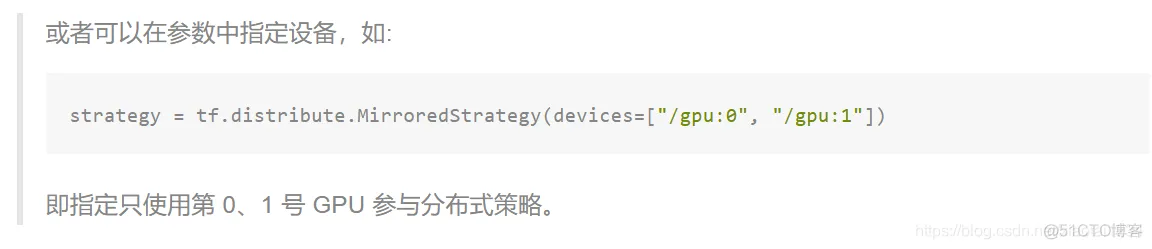
以下代码展示了使用 MirroredStrategy 策略,在 TensorFlow Datasets 中的部分图像数据集上使用 Keras 训练 MobileNetV2 的过程:
import tensorflow as tf
import tensorflow_datasets as tfds
num_epochs = 5
batch_size_per_replica = 64
learning_rate = 0.001
strategy = tf.distribute.MirroredStrategy()
print('Number of devices: %d' % strategy.num_replicas_in_sync) # 输出设备数量
batch_size = batch_size_per_replica * strategy.num_replicas_in_sync
# 载入数据集并预处理
def resize(image, label):
image = tf.image.resize(image, [224, 224]) / 255.0
return image, label
# 当as_supervised为True时,返回image和label两个键值
dataset = tfds.load("cats_vs_dogs", split=tfds.Split.TRAIN, as_supervised=True)
dataset = dataset.map(resize).shuffle(1024).batch(batch_size)
with strategy.scope():
model = tf.keras.applications.MobileNetV2()
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit(dataset, epochs=num_epochs)

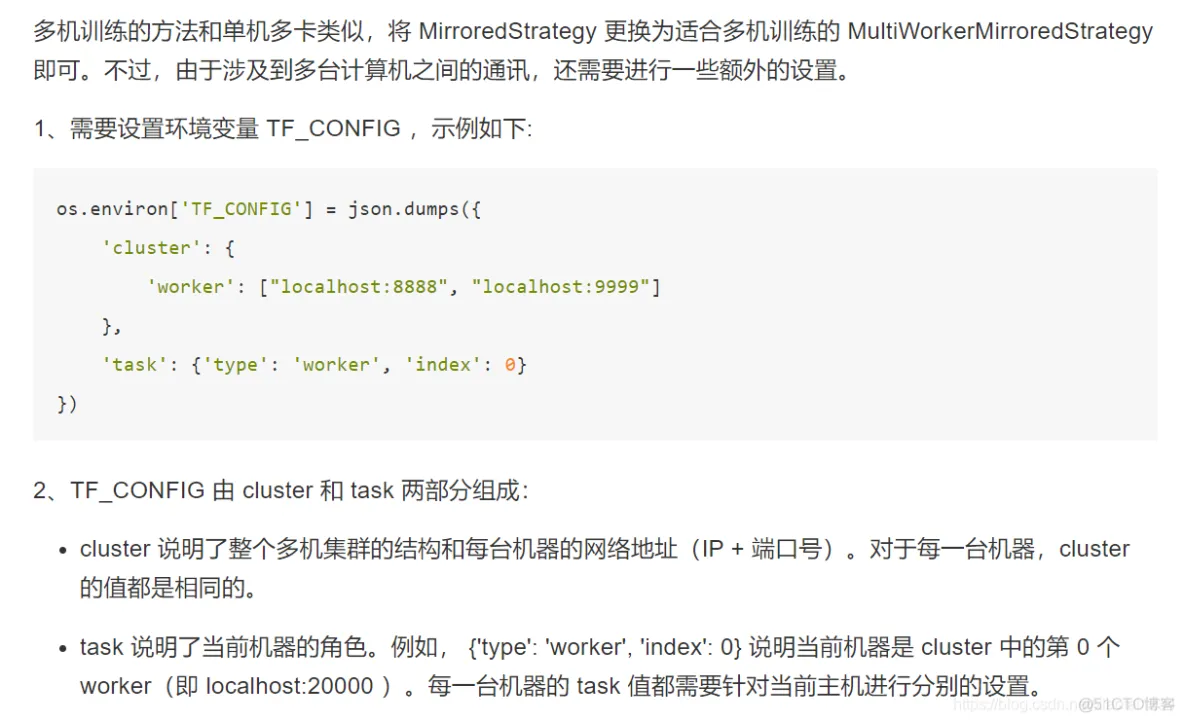

import tensorflow_datasets as tfds
import os
import json
num_epochs = 5
batch_size_per_replica = 64
learning_rate = 0.001
num_workers = 2
# 1、指定集群环境
os.environ['TF_CONFIG'] = json.dumps({
'cluster': {
'worker': ["localhost:20000", "localhost:20001"]
},
'task': {'type': 'worker', 'index': 0}
})
batch_size = batch_size_per_replica * num_workers
def resize(image, label):
image = tf.image.resize(image, [224, 224]) / 255.0
return image, label
dataset = tfds.load("cats_vs_dogs", split=tfds.Split.TRAIN, as_supervised=True)
dataset = dataset.map(resize).shuffle(1024).batch(batch_size)
# 2、初始化集群
strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
# 3、上下文环境定义模型
with strategy.scope():
model = tf.keras.applications.MobileNetV2()
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit(dataset, epochs=num_epochs)
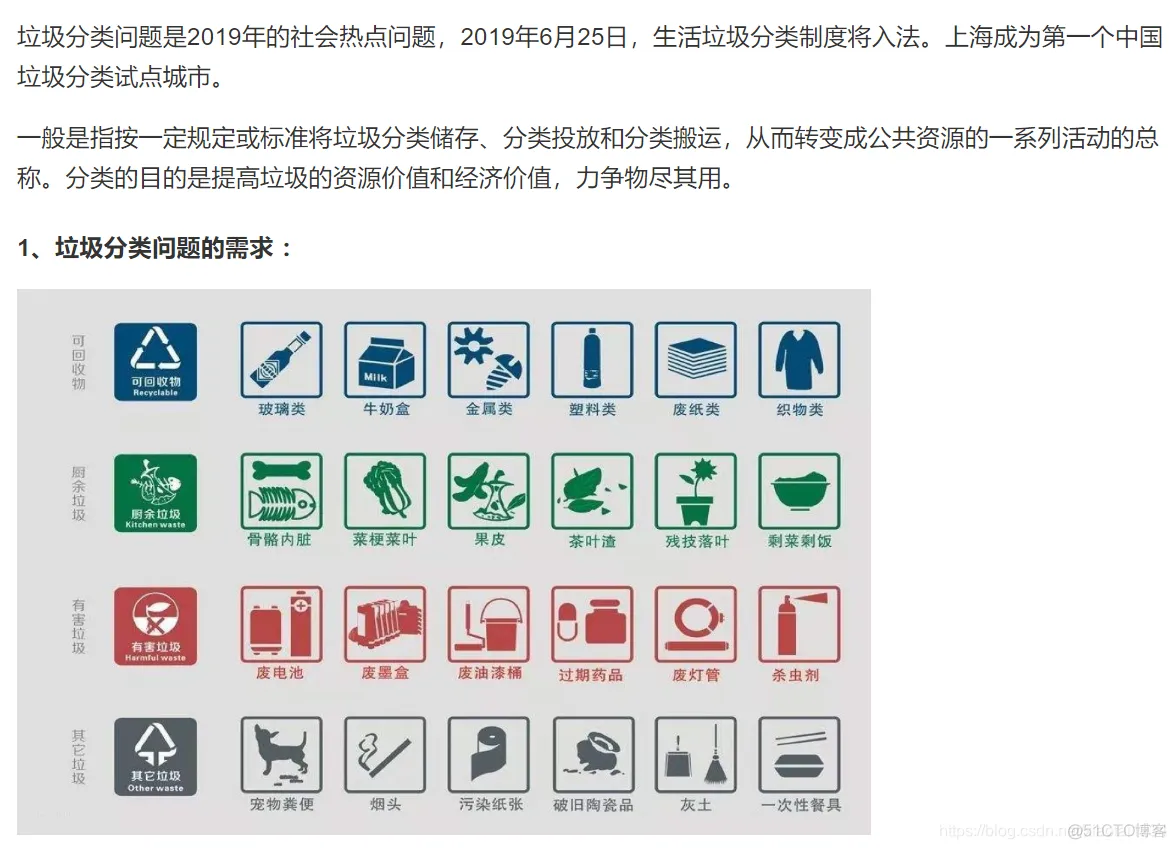

分类知识小拓展:可回收物指适宜回收和资源利用的废弃物,包括废弃的玻璃、金属、塑料、纸类、织物、家具、电器电子产品和年花年桔等。厨余垃圾指家庭、个人产生的易腐性垃圾,包括剩菜、剩饭、菜叶、果皮、蛋壳、茶渣、汤渣、骨头、废弃食物以及厨房下脚料等。有害垃圾指对人体健康或者自然环境造成直接或者潜在危害且应当专门处理的废弃物,包括废电池、废荧光灯管等。其他垃圾指除以上三类垃圾之外的其他生活垃圾,比如纸尿裤、尘土、烟头、一次性快餐盒、破损花盆及碗碟、墙纸等。


{
"0": "其他垃圾/一次性快餐盒",
"1": "其他垃圾/污损塑料",
"2": "其他垃圾/烟蒂",
"3": "其他垃圾/牙签",
"4": "其他垃圾/破碎花盆及碟碗",
"5": "其他垃圾/竹筷",
"6": "厨余垃圾/剩饭剩菜",
"7": "厨余垃圾/大骨头",
"8": "厨余垃圾/水果果皮",
"9": "厨余垃圾/水果果肉",
"10": "厨余垃圾/茶叶渣",
"11": "厨余垃圾/菜叶菜根",
"12": "厨余垃圾/蛋壳",
"13": "厨余垃圾/鱼骨",
"14": "可回收物/充电宝",
"15": "可回收物/包",
"16": "可回收物/化妆品瓶",
"17": "可回收物/塑料玩具",
"18": "可回收物/塑料碗盆",
"19": "可回收物/塑料衣架",
"20": "可回收物/快递纸袋",
"21": "可回收物/插头电线",
"22": "可回收物/旧衣服",
"23": "可回收物/易拉罐",
"24": "可回收物/枕头",
"25": "可回收物/毛绒玩具",
"26": "可回收物/洗发水瓶",
"27": "可回收物/玻璃杯",
"28": "可回收物/皮鞋",
"29": "可回收物/砧板",
"30": "可回收物/纸板箱",
"31": "可回收物/调料瓶",
"32": "可回收物/酒瓶",
"33": "可回收物/金属食品罐",
"34": "可回收物/锅",
"35": "可回收物/食用油桶",
"36": "可回收物/饮料瓶",
"37": "有害垃圾/干电池",
"38": "有害垃圾/软膏",
"39": "有害垃圾/过期药物"
}



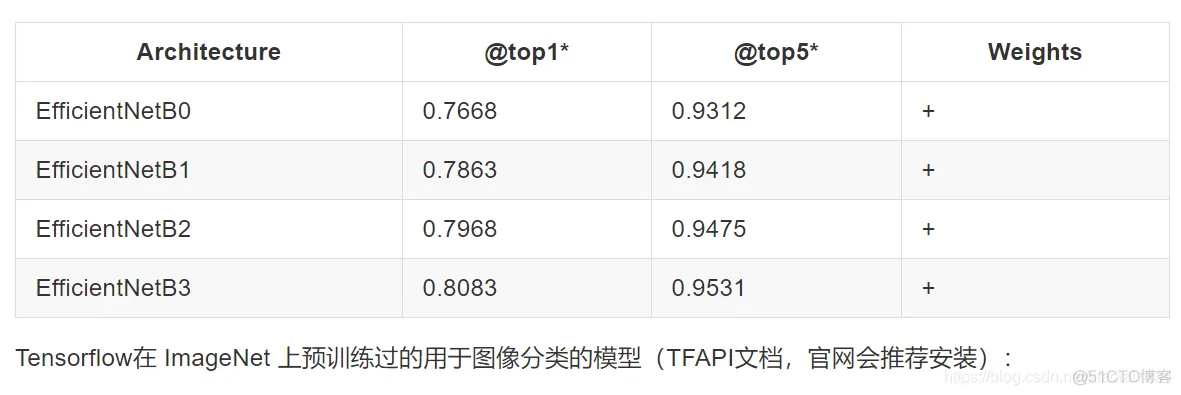
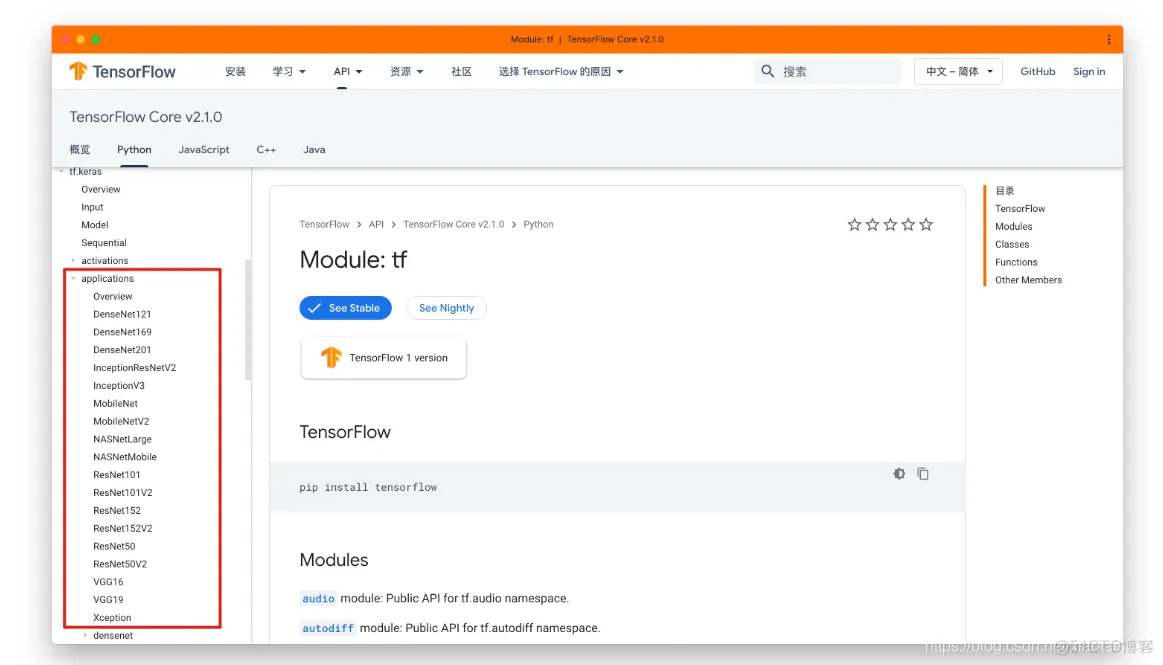
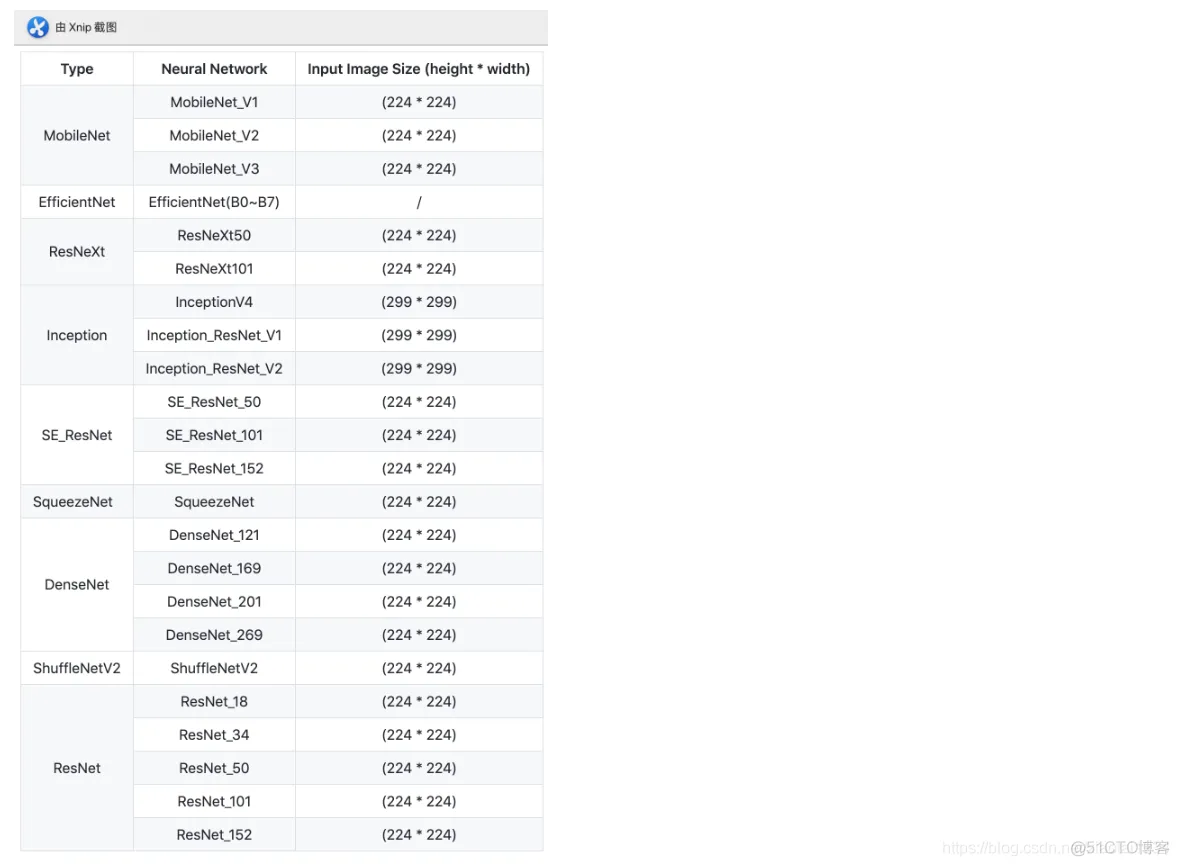

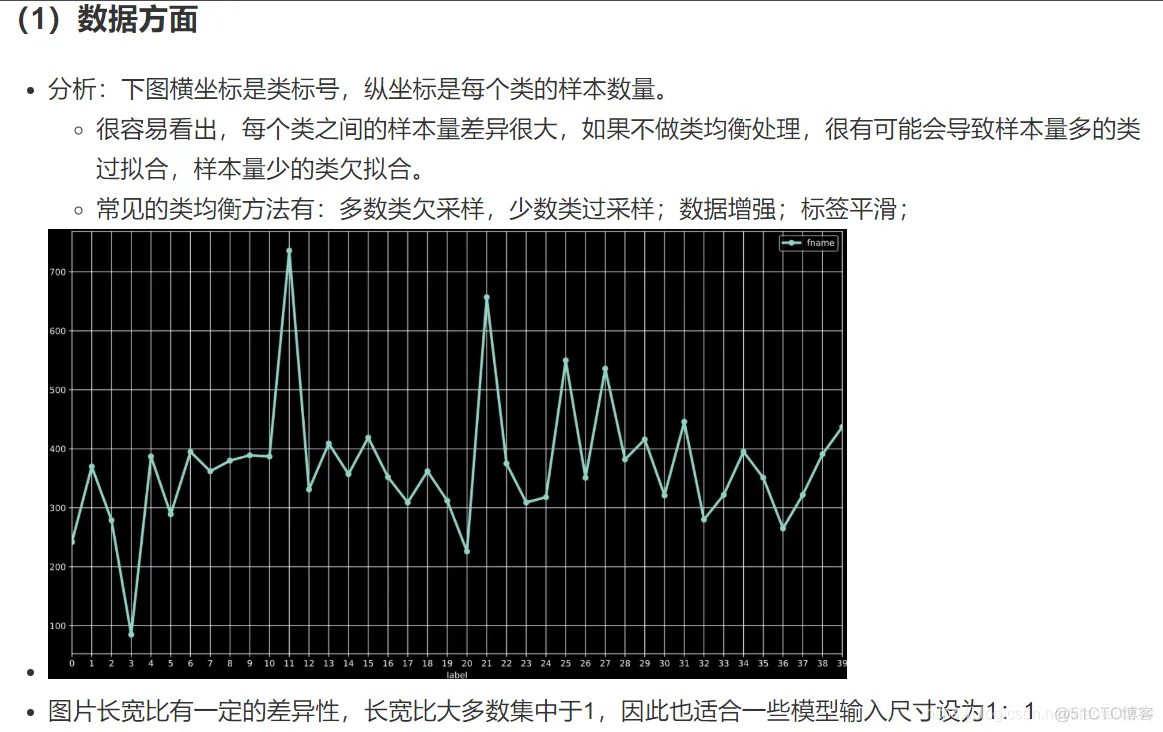


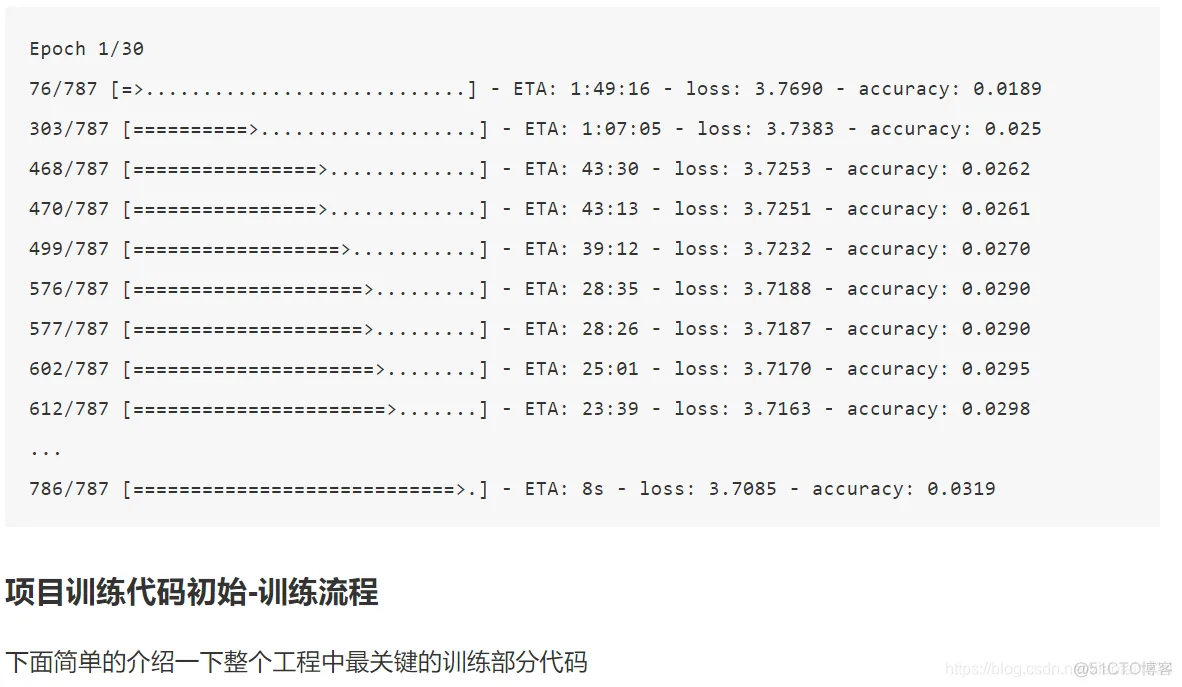
import multiprocessing
import numpy as np
import argparse
import tensorflow as tf
from tensorflow.keras.callbacks import ReduceLROnPlateau
from tensorflow.keras.callbacks import TensorBoard, Callback
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, RMSprop
from efficientnet import model as EfficientNet
from efficientnet import preprocess_input
from data_gen import data_flow
from utils.warmup_cosine_decay_scheduler import WarmUpCosineDecayScheduler
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
# efficientnet源码实现用TF1.X版本,所以要关闭默认的eager模式
tf.compat.v1.disable_eager_execution()
parser = argparse.ArgumentParser()
parser.add_argument("data_url", type=str, default='./data/garbage_classify/train_data', help="data dir", nargs='?')
parser.add_argument("train_url", type=str, default='./garbage_ckpt/', help="save model dir", nargs='?')
parser.add_argument("num_classes", type=int, default=40, help="num_classes", nargs='?')
parser.add_argument("input_size", type=int, default=300, help="input_size", nargs='?')
parser.add_argument("batch_size", type=int, default=16, help="batch_size", nargs='?')
parser.add_argument("learning_rate", type=float, default=0.0001, help="learning_rate", nargs='?')
parser.add_argument("max_epochs", type=int, default=30, help="max_epochs", nargs='?')
parser.add_argument("deploy_script_path", type=str, default='', help="deploy_script_path", nargs='?')
parser.add_argument("test_data_url", type=str, default='', help="test_data_url", nargs='?')
def model_fn(param):
"""迁移学习修改模型函数
:param param:
:return:
"""
base_model = EfficientNet.EfficientNetB3(include_top=False, input_shape=(param.input_size, param.input_size, 3),
classes=param.num_classes)
x = base_model.output
x = GlobalAveragePooling2D(name='avg_pool')(x)
predictions = Dense(param.num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
return model
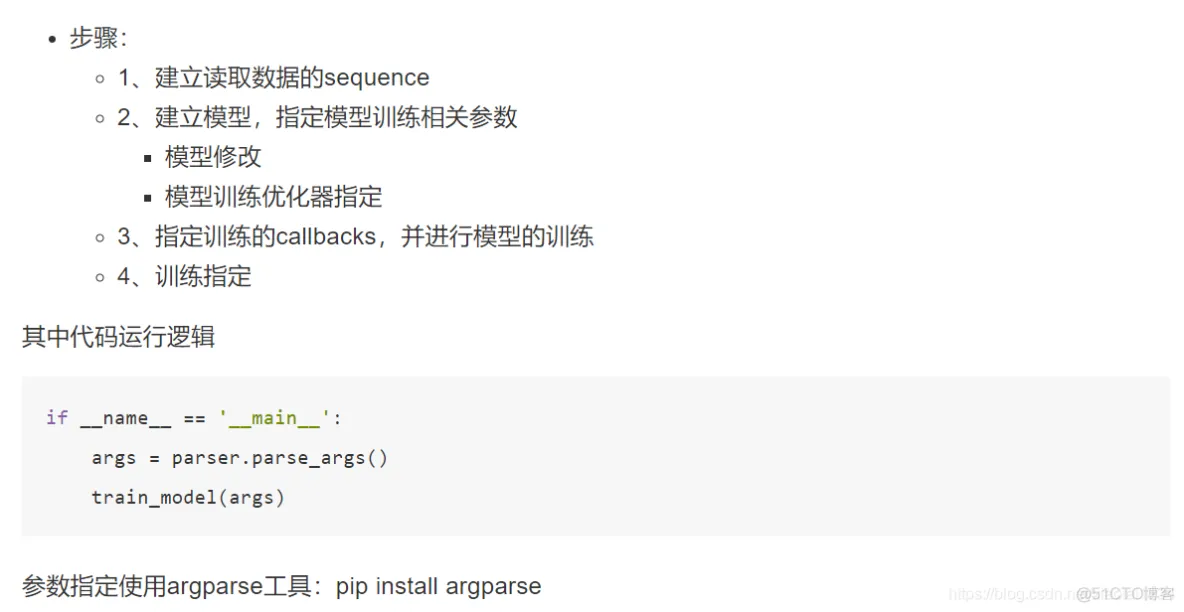
def train_model(param):
"""训练模型
:param param: 传入的命令参数
:return:
"""
# 1、建立读取数据的sequence
train_sequence, validation_sequence = data_flow(param.data_url, param.batch_size,
param.num_classes, param.input_size, preprocess_input)
# 2、建立模型,指定模型训练相关参数
model = model_fn(param)
optimizer = Adam(lr=param.learning_rate)
objective = 'categorical_crossentropy'
metrics = ['accuracy']
# 模型修改
# 模型训练优化器指定
model.compile(loss=objective, optimizer=optimizer, metrics=metrics)
model.summary()
# 判断模型是否加载历史模型
if os.path.exists(param.train_url):
filenames = os.listdir(param.train_url)
model.load_weights(filenames[-1])
print("加载完成!!!")
# 3、指定训练的callbacks,并进行模型的训练
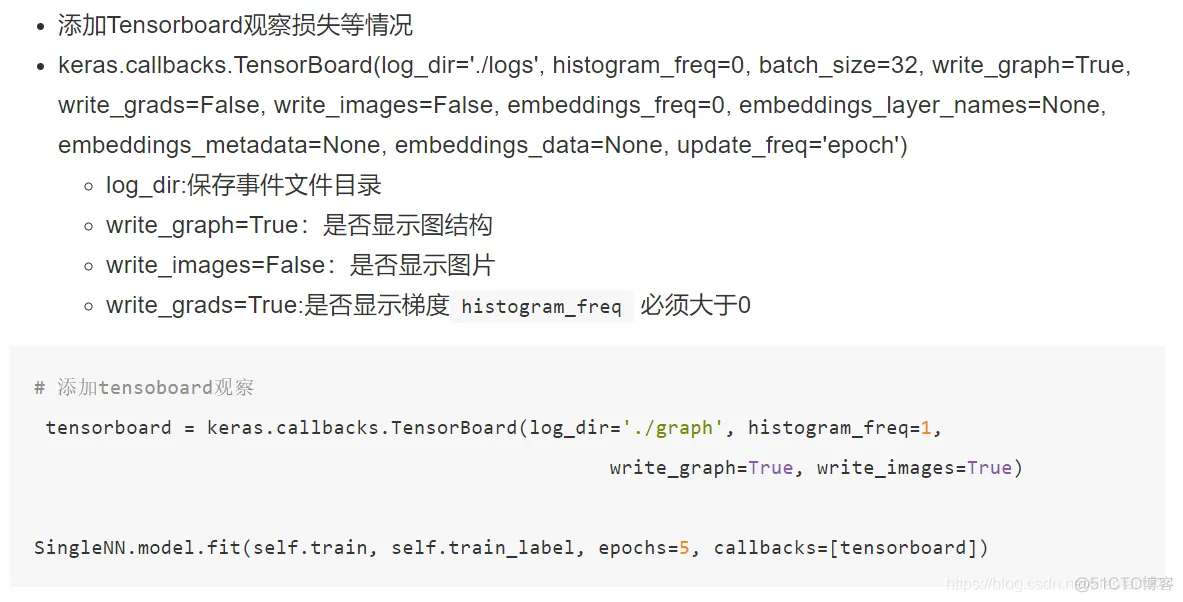
# (1)Tensorboard
tensorboard = tf.keras.callbacks.TensorBoard(log_dir='./graph', histogram_freq=1,
write_graph=True, write_images=True)
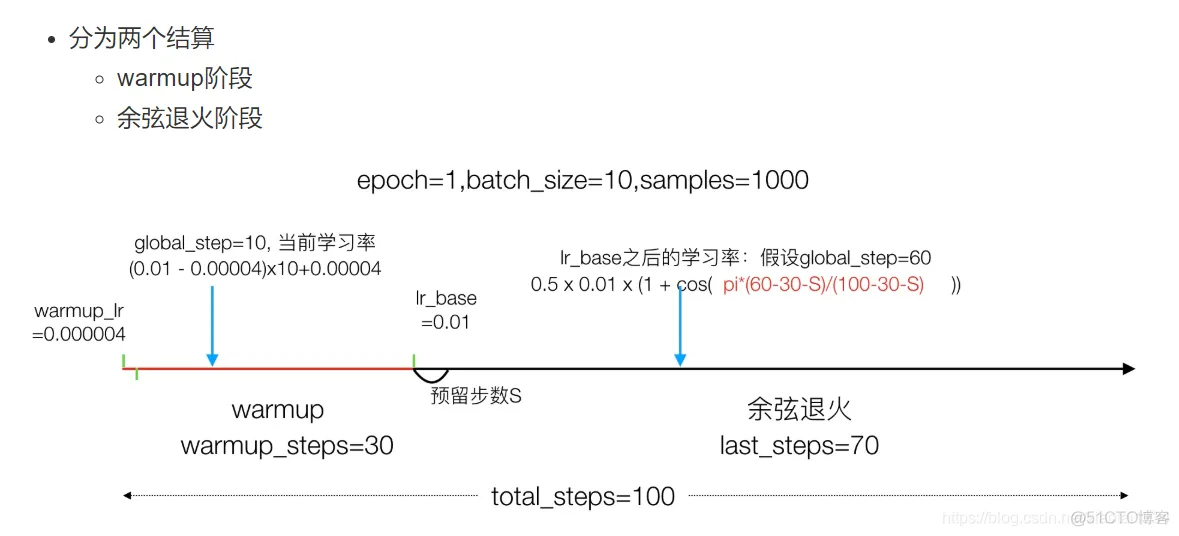
# (2)自定义warm up和余弦学习率衰减
sample_count = len(train_sequence) * param.batch_size
epochs = param.max_epochs
warmup_epoch = 5
batch_size = param.batch_size
learning_rate_base = param.learning_rate
total_steps = int(epochs * sample_count / batch_size)
warmup_steps = int(warmup_epoch * sample_count / batch_size)
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=0,
warmup_steps=warmup_steps,
hold_base_rate_steps=0,
)
#(3)模型保存相关参数
check = tf.keras.callbacks.ModelCheckpoint(param.train_url+'weights_{epoch:02d}-{val_acc:.2f}.h5',
monitor='val_acc',
save_best_only=True,
save_weights_only=False,
mode='auto',
period=1)
# (4)训练
model.fit_generator(
train_sequence,
steps_per_epoch=len(train_sequence),
epochs=param.max_epochs,
verbose=1,
callbacks=[check, tensorboard, warm_up_lr],
validation_data=validation_sequence,
max_queue_size=10,
workers=int(multiprocessing.cpu_count() * 0.7),
use_multiprocessing=True,
shuffle=True
)
print('模型训练结束!')

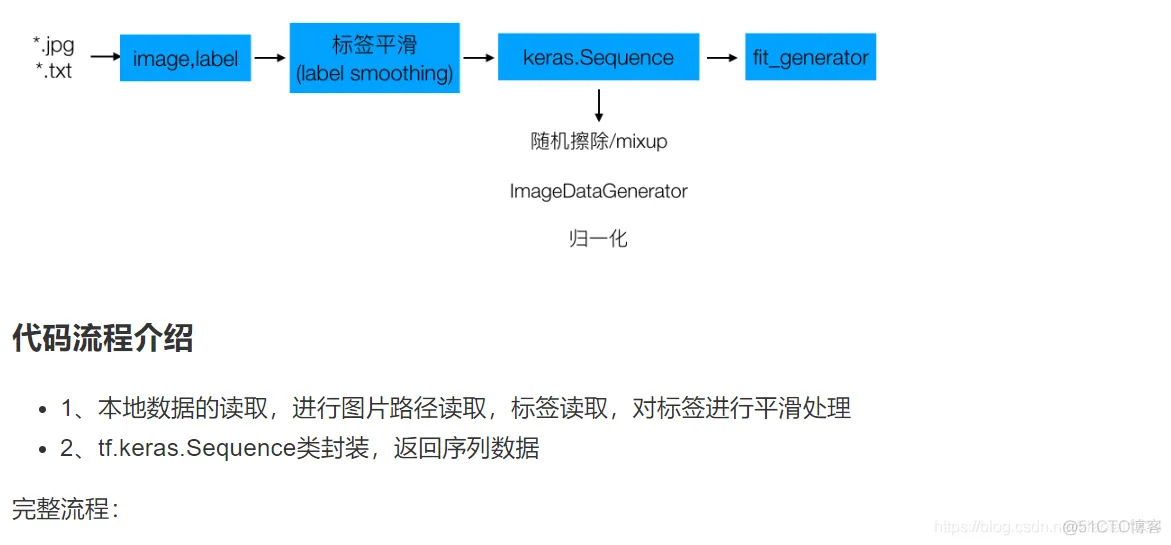
def data_from_sequence(train_data_dir, batch_size, num_classes, input_size):
"""读取本地图片和标签数据,处理成sequence数据类型
:param train_data_dir: 训练数据目录
:param batch_size: 批次大小
:param num_classes: 垃圾分类总类别数
:param input_size: 输入模型的图片大小(300, 300)
:return:
"""
# 1、获取txt文件,打乱一次文件
label_files = [os.path.join(train_data_dir, filename) for filename in os.listdir(train_data_dir) if filename.endswith('.txt')]
print(label_files)
random.shuffle(label_files)
# 2、读取txt文件,解析出
img_paths = []
labels = []
for index, file_path in enumerate(label_files):
with open(file_path, 'r') as f:
line = f.readline()
line_split = line.strip().split(', ')
if len(line_split) != 2:
print('%s 文件中格式错误' % (file_path))
continue
# 获取图片名称和标签,转换格式
img_name = line_split[0]
label = int(line_split[1])
# 图片完整路径拼接,并获取到图片和标签列表中(顺序一一对应)
img_paths.append(os.path.join(train_data_dir, img_name))
labels.append(label)
# 3、进行标签类别处理,以及标签平滑
labels = to_categorical(labels, num_classes)
labels = smooth_labels(labels)
# 4、进行所有数据的分割,训练集和验证集
train_img_paths, validation_img_paths, train_labels, validation_labels = \
train_test_split(img_paths, labels, test_size=0.15, random_state=0)
print('总共样本数: %d, 训练样本数: %d, 验证样本数据: %d' % (
len(img_paths), len(train_img_paths), len(validation_img_paths)))
# 5、sequence序列数据制作
train_sequence = GarbageDataSequence(train_img_paths, train_labels, batch_size,
[input_size, input_size], use_aug=True)
validation_sequence = GarbageDataSequence(validation_img_paths, validation_labels, batch_size,
[input_size, input_size], use_aug=False)
return train_sequence, validation_sequence

import math
import os
import random
import numpy as np
from PIL import Image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import to_categorical, Sequence
from sklearn.model_selection import train_test_split
from data_gen.random_eraser import get_random_eraser
def data_from_sequence(train_data_dir, batch_size, num_classes, input_size):
"""读取本地图片和标签数据,处理成sequence数据类型
:param train_data_dir: 训练数据目录
:param batch_size: 批次大小
:param num_classes: 垃圾分类总类别数
:param input_size: 输入模型的图片大小(300, 300)
:return:
"""
# 1、获取txt文件,打乱一次文件
label_files = [os.path.join(train_data_dir, filename) for filename in os.listdir(train_data_dir) if filename.endswith('.txt')]
print(label_files)
random.shuffle(label_files)
# 2、读取txt文件,解析出
img_paths = []
labels = []
for index, file_path in enumerate(label_files):
with open(file_path, 'r') as f:
line = f.readline()
line_split = line.strip().split(', ')
if len(line_split) != 2:
print('%s 文件中格式错误' % (file_path))
continue
# 获取图片名称和标签,转换格式
img_name = line_split[0]
label = int(line_split[1])
# 图片完整路径拼接,并获取到图片和标签列表中(顺序一一对应)
img_paths.append(os.path.join(train_data_dir, img_name))
labels.append(label)
# 3、进行标签类别处理,以及标签平滑
labels = to_categorical(labels, num_classes)
labels = smooth_labels(labels)
return None
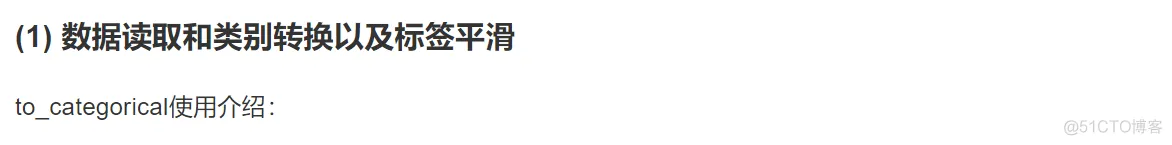
In [5]: tf.keras.utils.to_categorical([1,2,3,4,5], num_classes=10)
Out[5]:
array([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.]], dtype=float32)


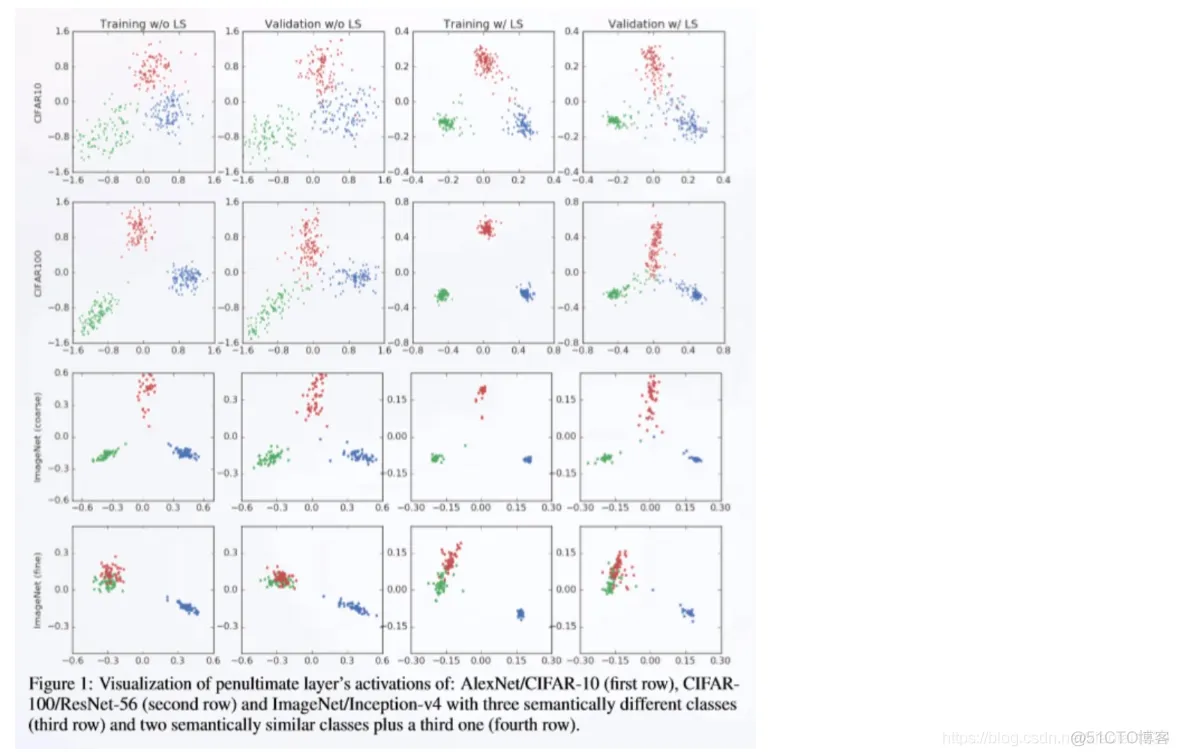
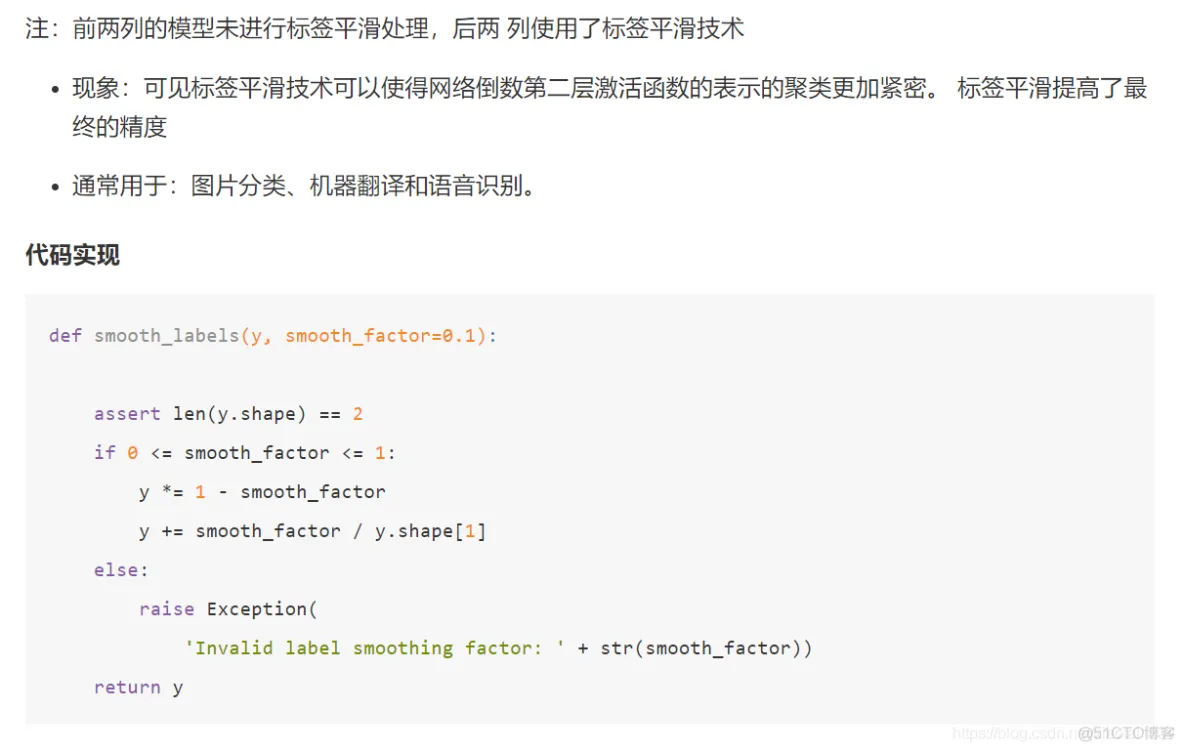

from skimage.io import imread
from skimage.transform import resize
import numpy as np
import math
# Here, `x_set` is list of path to the images
# and `y_set` are the associated classes.
class CIFAR10Sequence(Sequence):
def __init__(self, x_set, y_set, batch_size):
self.x, self.y = x_set, y_set
self.batch_size = batch_size
def __len__(self):
return math.ceil(len(self.x) / self.batch_size)
def __getitem__(self, idx):
batch_x = self.x[idx * self.batch_size:(idx + 1) *
self.batch_size]
batch_y = self.y[idx * self.batch_size:(idx + 1) *
self.batch_size]
return np.array([
resize(imread(file_name), (200, 200))
for file_name in batch_x]), np.array(batch_y)

class GarbageDataSequence(Sequence):
"""数据流生成器,每次迭代返回一个batch
可直接用于fit_generator的generator参数,能保证在多进程下的一个epoch中不会重复取相同的样本
"""
def __init__(self, img_paths, labels, batch_size, img_size, use_aug):
# 异常判断
self.x_y = np.hstack((np.array(img_paths).reshape(len(img_paths), 1), np.array(labels)))
self.batch_size = batch_size
self.img_size = img_size
self.alpha = 0.2
self.use_aug = use_aug
self.eraser = get_random_eraser(s_h=0.3, pixel_level=True)
def __len__(self):
return math.ceil(len(self.x_y) / self.batch_size)
@staticmethod
def center_img(img, size=None, fill_value=255):
"""改变图片尺寸到300x300,并且做填充使得图像处于中间位置
"""
h, w = img.shape[:2]
if size is None:
size = max(h, w)
shape = (size, size) + img.shape[2:]
background = np.full(shape, fill_value, np.uint8)
center_x = (size - w) // 2
center_y = (size - h) // 2
background[center_y:center_y + h, center_x:center_x + w] = img
return background
def preprocess_img(self, img_path):
"""图片的处理流程函数,数据增强、center_img处理
"""
# 1、图像读取,[180 , 200]-> (200)max(180, 200)->[300/200 * 180, 300/200 * 200]
# 这样做为了不使图形直接变形,后续在统一长宽
img = Image.open(img_path)
resize_scale = self.img_size[0] / max(img.size[:2])
img = img.resize((int(img.size[0] * resize_scale), int(img.size[1] * resize_scale)))
img = img.convert('RGB')
img = np.array(img)
# 2、数据增强:如果是训练集进行数据增强操作
# 先随机擦除,然后翻转
if self.use_aug:
img = self.eraser(img)
datagen = ImageDataGenerator(
width_shift_range=0.05,
height_shift_range=0.05,
horizontal_flip=True,
vertical_flip=True,
)
img = datagen.random_transform(img)
# 3、把图片大小调整到[300, 300, 3],调整的方式为直接填充小的坐标。为了模型需要
img = self.center_img(img, self.img_size[0])
return img
def __getitem__(self, idx):
# 1、处理图片大小、数据增强等过程
print(self.x_y)
batch_x = self.x_y[idx * self.batch_size: (idx + 1) * self.batch_size, 0]
batch_y = self.x_y[idx * self.batch_size: (idx + 1) * self.batch_size, 1:]
batch_x = np.array([self.preprocess_img(img_path) for img_path in batch_x])
batch_y = np.array(batch_y).astype(np.float32)
# print(batch_y[1])
# 2、mixup进行构造新的样本分布数据
# batch_x, batch_y = self.mixup(batch_x, batch_y)
# 3、输入模型的归一化数据
batch_x = self.preprocess_input(batch_x)
return batch_x, batch_y
def on_epoch_end(self):
np.random.shuffle(self.x_y)
def preprocess_input(self, x):
"""归一化处理样本特征值
:param x:
:return:
"""
assert x.ndim in (3, 4)
assert x.shape[-1] == 3
MEAN_RGB = [0.485 * 255, 0.456 * 255, 0.406 * 255]
STDDEV_RGB = [0.229 * 255, 0.224 * 255, 0.225 * 255]
x = x - np.array(MEAN_RGB)
x = x / np.array(STDDEV_RGB)
return x
def mixup(self, batch_x, batch_y):
"""
数据混合mixup
:param batch_x: 要mixup的batch_X
:param batch_y: 要mixup的batch_y
:return: mixup后的数据
"""
size = self.batch_size
l = np.random.beta(self.alpha, self.alpha, size)
X_l = l.reshape(size, 1, 1, 1)
y_l = l.reshape(size, 1)
X1 = batch_x
Y1 = batch_y
X2 = batch_x[::-1]
Y2 = batch_y[::-1]
X = X1 * X_l + X2 * (1 - X_l)
Y = Y1 * y_l + Y2 * (1 - y_l)
return X, Y
if __name__ == '__main__':
train_data_dir = '../data/garbage_classify/train_data'
batch_size = 32
train_sequence, validation_sequence = data_from_sequence(train_data_dir, batch_size, num_classes=40, input_size=300)
for i in range(100):
print("第 %d 批次数据" % i)
batch_data, bacth_label = train_sequence.__getitem__(i)
print(batch_data.shape, bacth_label.shape)
batch_data, bacth_label = validation_sequence.__getitem__(i)


def mixup(self, batch_x, batch_y):
"""
数据混合mixup
:param batch_x: 要mixup的batch_X
:param batch_y: 要mixup的batch_y
:return: mixup后的数据
"""
size = self.batch_size
l = np.random.beta(self.alpha, self.alpha, size)
X_l = l.reshape(size, 1, 1, 1)
y_l = l.reshape(size, 1)
X1 = batch_x
Y1 = batch_y
X2 = batch_x[::-1]
Y2 = batch_y[::-1]
X = X1 * X_l + X2 * (1 - X_l)
Y = Y1 * y_l + Y2 * (1 - y_l)
return X, Y
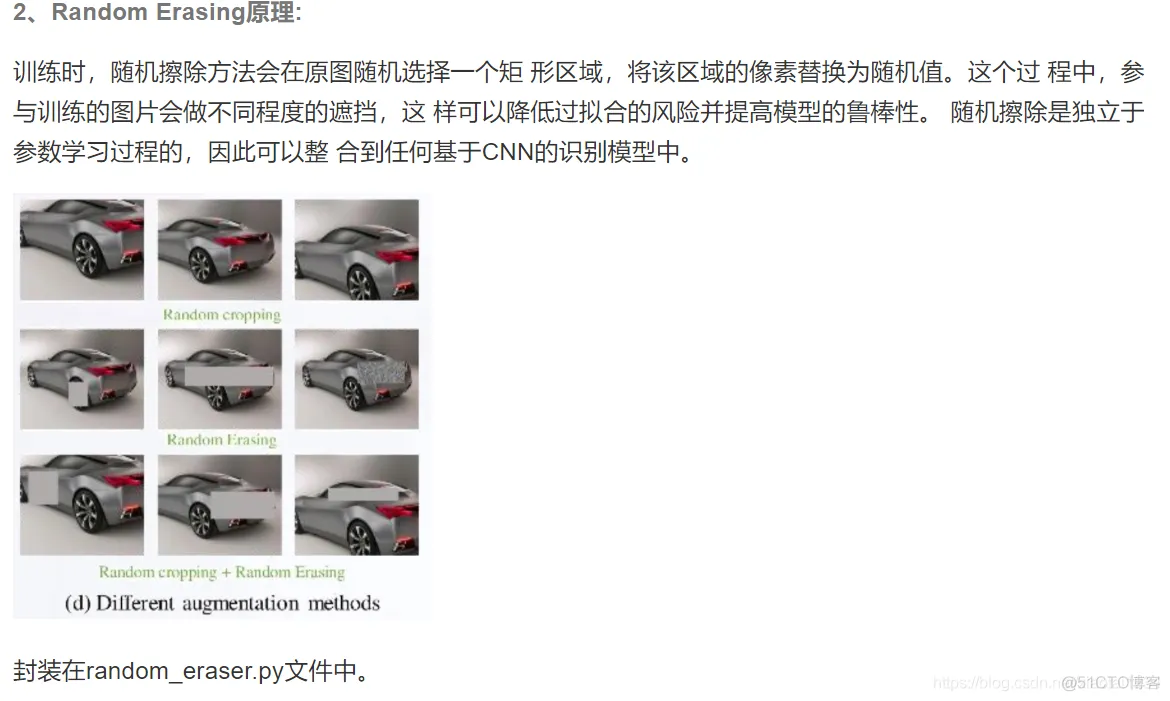
import numpy as np
import tensorflow as tf
def get_random_eraser(p=0.5, s_l=0.02, s_h=0.4, r_1=0.3, r_2=1/0.3, v_l=0, v_h=255, pixel_level=False):
def eraser(input_img):
img_h, img_w, img_c = input_img.shape
p_1 = np.random.rand()
if p_1 > p:
return input_img
while True:
s = np.random.uniform(s_l, s_h) * img_h * img_w
r = np.random.uniform(r_1, r_2)
w = int(np.sqrt(s / r))
h = int(np.sqrt(s * r))
left = np.random.randint(0, img_w)
top = np.random.randint(0, img_h)
if left + w <= img_w and top + h <= img_h:
break
if pixel_level:
c = np.random.uniform(v_l, v_h, (h, w, img_c))
else:
c = np.random.uniform(v_l, v_h)
input_img[top:top + h, left:left + w, :] = c
return input_img
return eraser
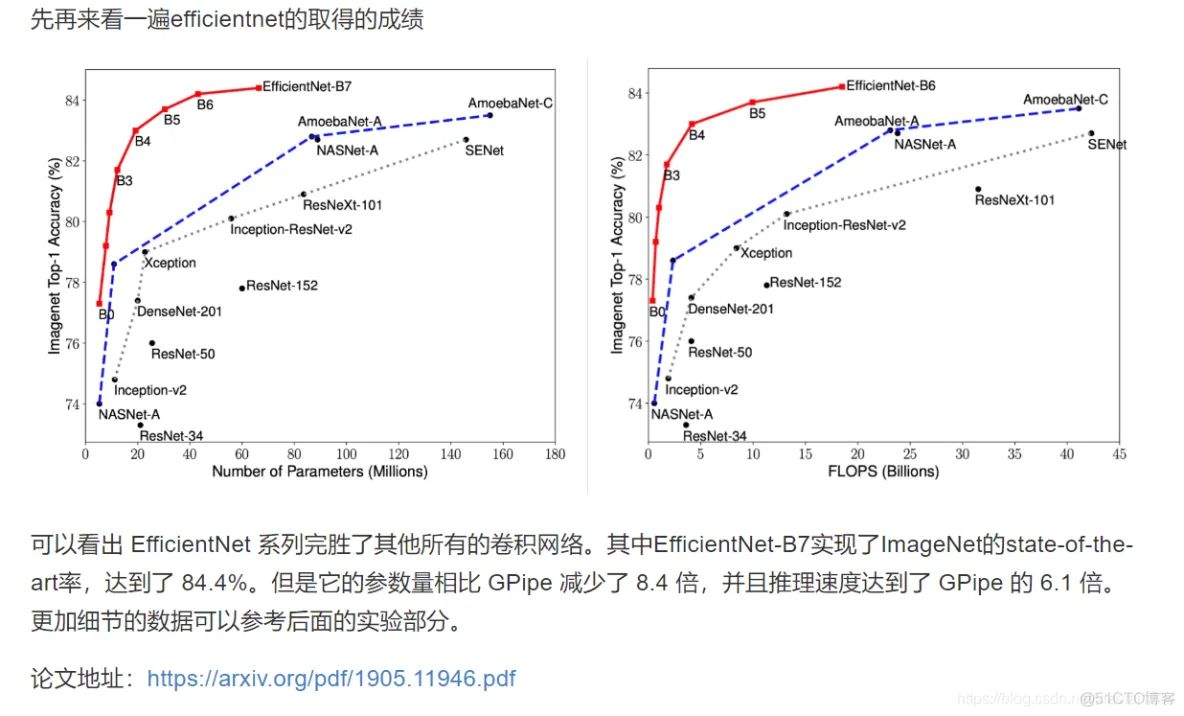

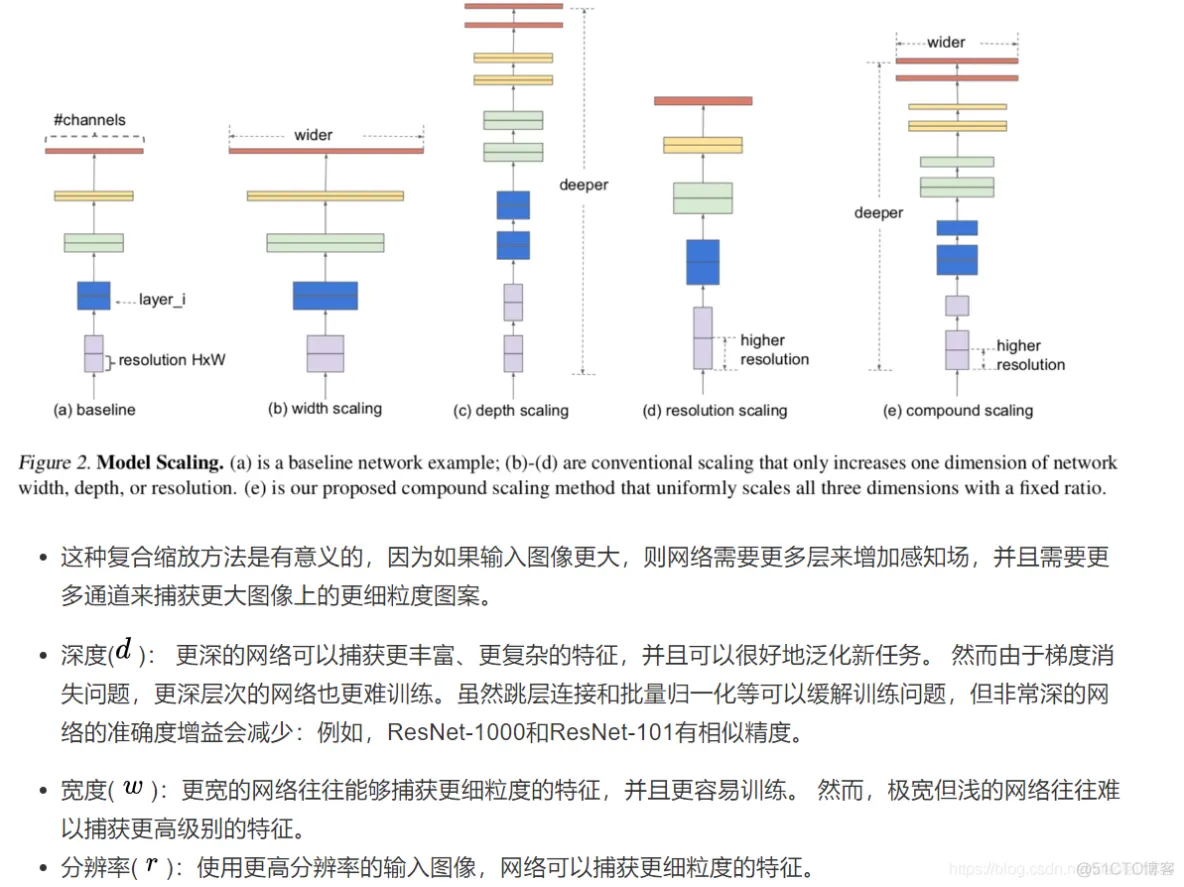




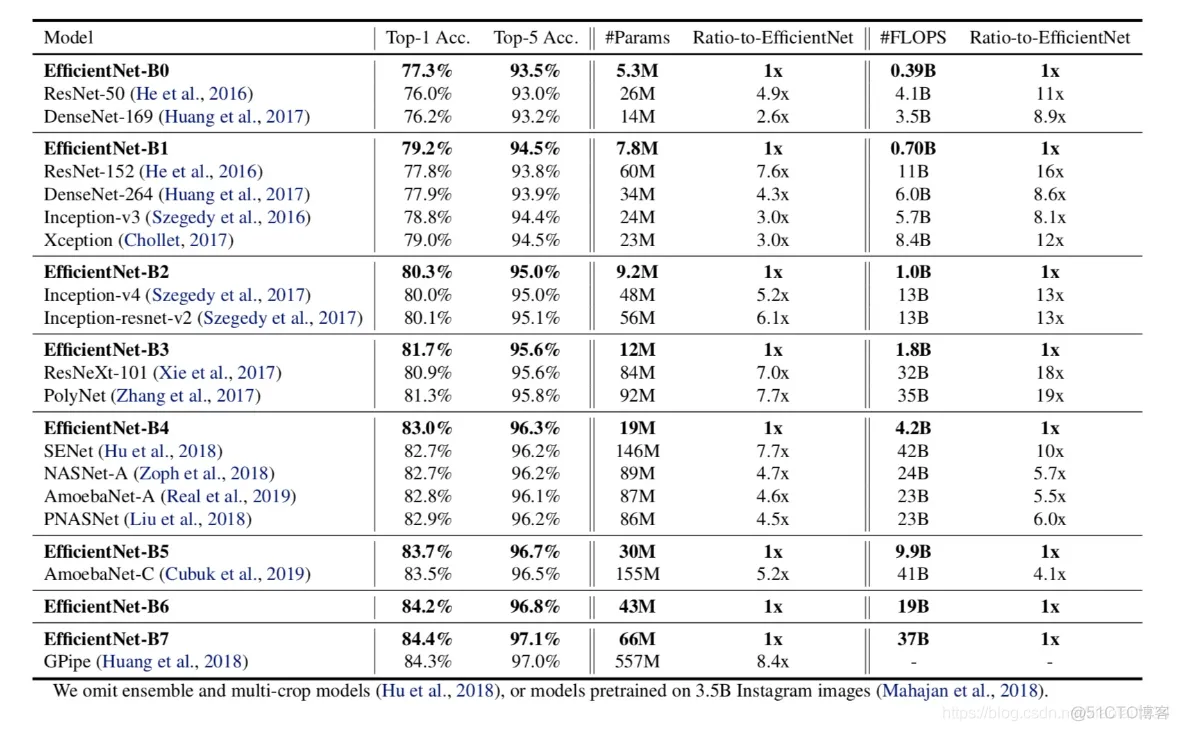
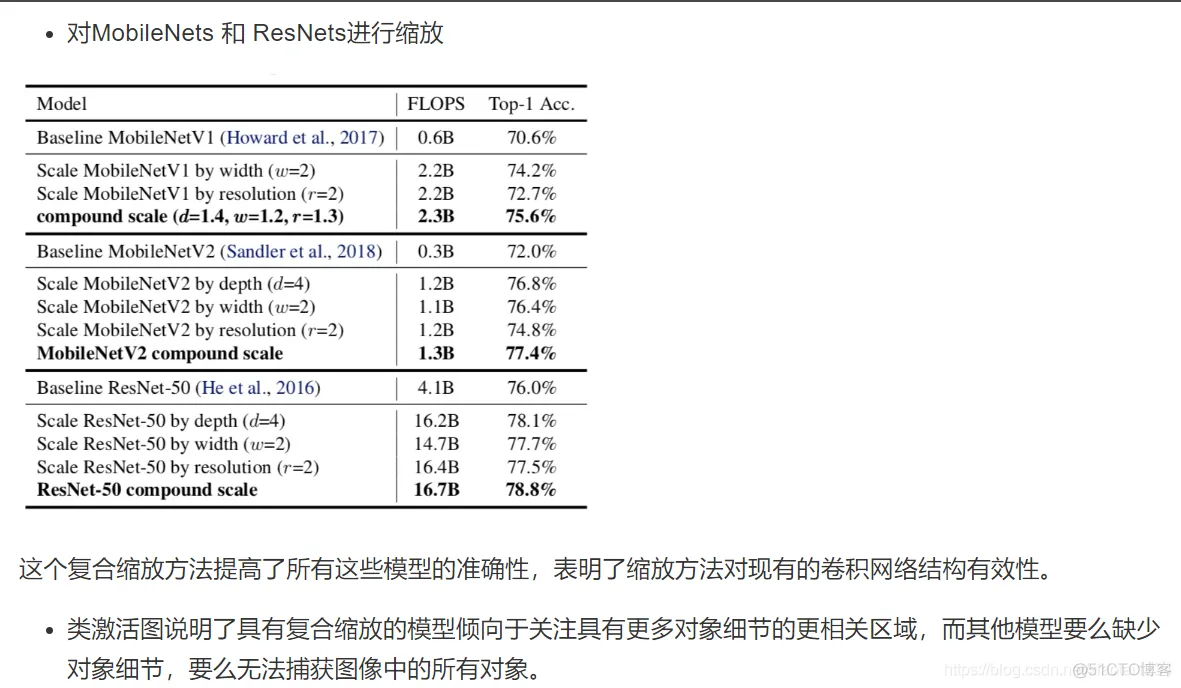
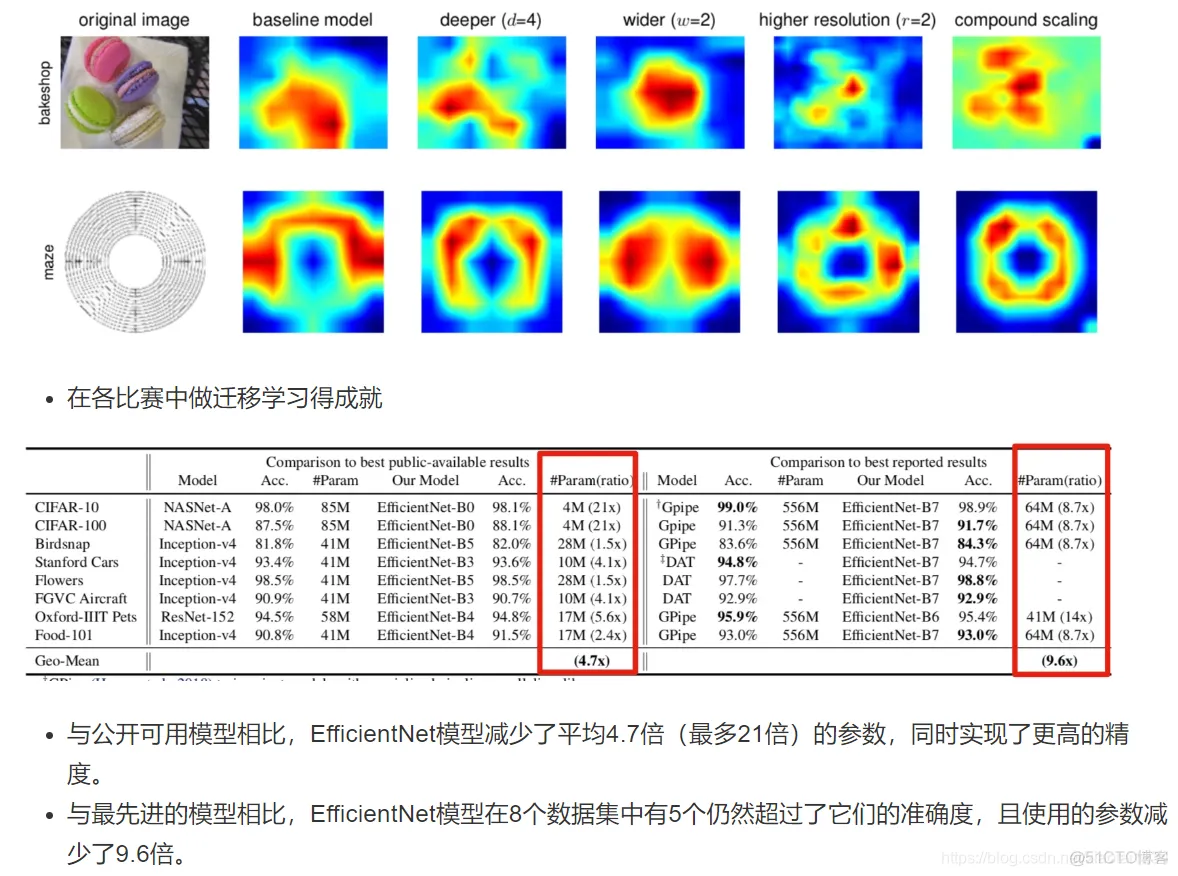
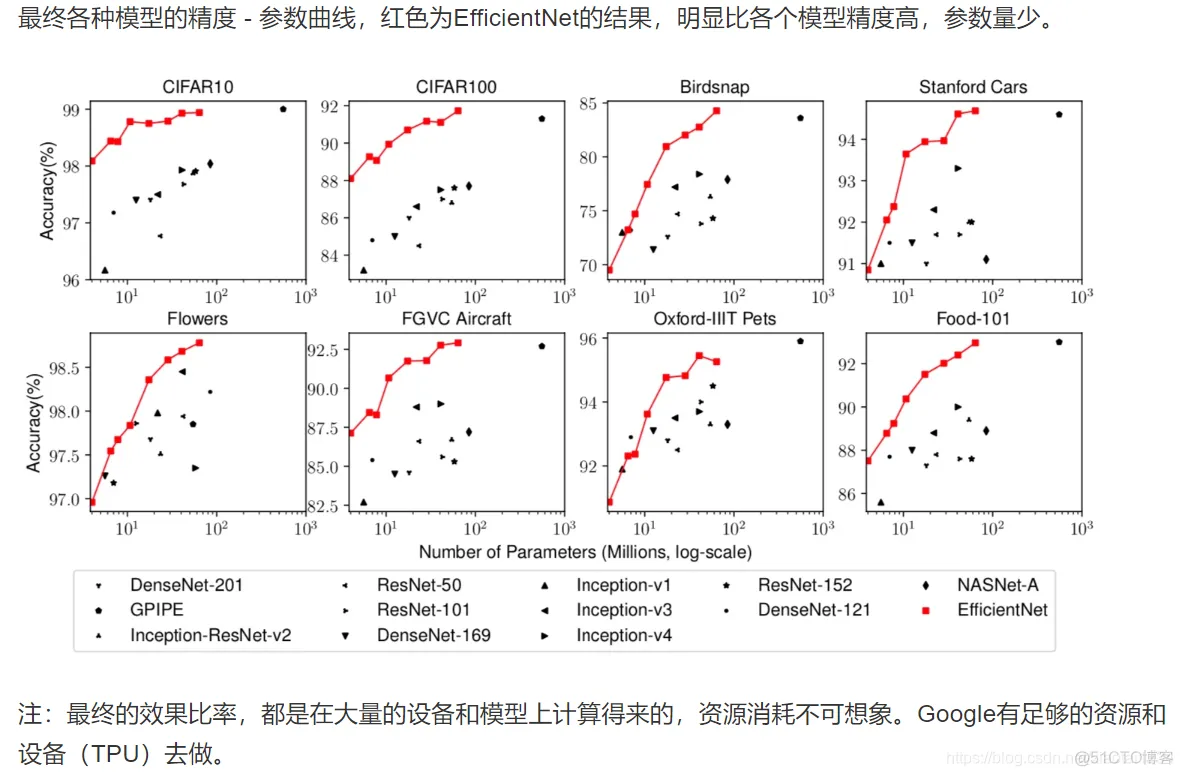
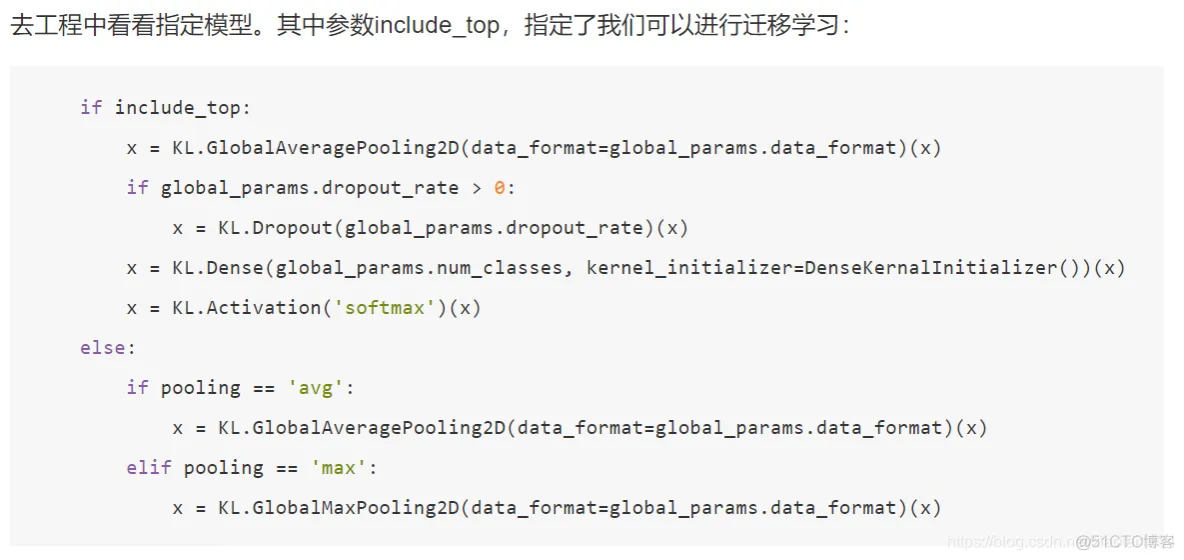





import numpy as np
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
class WarmUpCosineDecayScheduler(tf.keras.callbacks.Callback):
"""带有warmup的余弦退火学习率调度
"""
def __init__(self,
learning_rate_base,
total_steps,
global_step_init=0,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0,
verbose=0):
"""
初始化参数
:param learning_rate_base: 基础学习率
:param total_steps: 总共迭代的批次步数 epoch * num_samples / batch_size
:param global_step_init: 初始
:param warmup_learning_rate: 预热学习率默认0.0
:param warmup_steps:预热的步数默认0
:param hold_base_rate_steps:
:param verbose:
"""
super(WarmUpCosineDecayScheduler, self).__init__()
self.learning_rate_base = learning_rate_base
self.total_steps = total_steps
self.global_step = global_step_init
self.warmup_learning_rate = warmup_learning_rate
self.warmup_steps = warmup_steps
self.hold_base_rate_steps = hold_base_rate_steps
# 是否在每次训练结束打印学习率
self.verbose = verbose
# 记录所有批次下来的每次准确的学习率,可以用于打印显示
self.learning_rates = []
def on_batch_end(self, batch, logs=None):
# 1、批次开始前当前步数+1
self.global_step = self.global_step + 1
# 2、获取优化器上一次的学习率,并记录
lr = K.get_value(self.model.optimizer.lr)
self.learning_rates.append(lr)
def on_batch_begin(self, batch, logs=None):
# 1、通过参数以及记录的次数和上次学习率
lr = cosine_decay_with_warmup(global_step=self.global_step,
learning_rate_base=self.learning_rate_base,
total_steps=self.total_steps,
warmup_learning_rate=self.warmup_learning_rate,
warmup_steps=self.warmup_steps,
hold_base_rate_steps=self.hold_base_rate_steps)
# 2、设置优化器本次的学习率
K.set_value(self.model.optimizer.lr, lr)
if self.verbose > 0:
print('\n批次数 %05d: 设置学习率为'
' %s.' % (self.global_step + 1, lr))

def cosine_decay_with_warmup(global_step,
learning_rate_base,
total_steps,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0):
"""
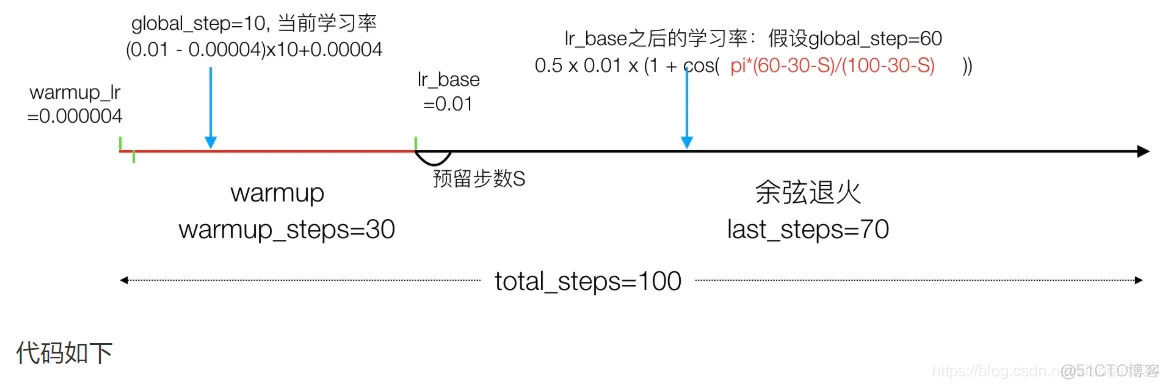
每批次带有warmup余弦退火学习率计算
:param global_step: 当前到达的步数
:param learning_rate_base: warmup之后的基础学习率
:param total_steps: 总需要批次数
:param warmup_learning_rate: warmup开始的学习率
:param warmup_steps:warmup学习率 步数
:param hold_base_rate_steps: 预留总步数和warmup步数间隔
:return:
"""
if total_steps < warmup_steps:
raise ValueError('总步数必须大于warmup')
# 1、余弦退火学习率计算
# 从warmup结束之后计算
# 0.5 * 0.01 * (1 + cos(pi*(1-5-0)/(10 - 5 - 0))
learning_rate = 0.5 * learning_rate_base * (1 + np.cos(
np.pi *
(global_step - warmup_steps - hold_base_rate_steps
) / float(total_steps - warmup_steps - hold_base_rate_steps)))
# 2、warmup之后的学习率计算
# 如果预留大于0,判断目前步数是否 > warmup步数+预留步数,是的话返回刚才上面计算的学习率,不是的话使用warmup之后的基础学习率
if hold_base_rate_steps > 0:
learning_rate = np.where(global_step > warmup_steps + hold_base_rate_steps,
learning_rate, learning_rate_base)
# 3、warmup步数是大于0的
if warmup_steps > 0:
if learning_rate_base < warmup_learning_rate:
raise ValueError('warmup后学习率必须大于warmup开始学习率')
# 1、计算一个0.01和0.000006的差距/warmup_steps,得到warmup结束前增加多少
slope = (learning_rate_base - warmup_learning_rate) / warmup_steps
# 2、计算warmup下一步第global_step的学习率
warmup_rate = slope * global_step + warmup_learning_rate
# 3、判断global_step小于warmup_steps的话,返回这个warmup当时的学习率,否则直接返回余弦退火计算的
learning_rate = np.where(global_step < warmup_steps, warmup_rate,
learning_rate)
# 4、如果最后当前到达的步数大于总步数,则归0,否则返回当前的计算出来的学习率(可能是warmup学习率也可能是余弦衰减结果)
return np.where(global_step > total_steps, 0.0, learning_rate)
通过以下代码进行测试:
if __name__ == '__main__':
# 1、创建模型
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 2、参数设置
sample_count = 1000 # 样本数
epochs = 4 # 总迭代次数
warmup_epoch = 3 # warmup 迭代次数
batch_size = 16 # 批次大小
learning_rate_base = 0.0001 # warmup后的初始学习率
total_steps = int(epochs * sample_count / batch_size) # 总迭代批次步数
warmup_steps = int(warmup_epoch * sample_count / batch_size) # warmup总批次数
# 3、创建测试数据
data = np.random.random((sample_count, 100))
labels = np.random.randint(10, size=(sample_count, 1))
# 转换目标类别
one_hot_labels = tf.keras.utils.to_categorical(labels, num_classes=10)
# 5、创建余弦warmup调度器
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=4e-06, # warmup开始学习率
warmup_steps=warmup_steps,
hold_base_rate_steps=0,
)
# 训练模型
model.fit(data, one_hot_labels, epochs=epochs, batch_size=batch_size, verbose=0, callbacks=[warm_up_lr])
print(warm_up_lr.learning_rates)
结果:
[4e-06, 4.513369e-06, ...., 7.281053e-05, 7.0564354e-05, 6.826705e-05, 6.592433e-05, 6.354202e-05, 6.112605e-05, 5.868241e-05, 5.6217184e-05, 5.3736505e-05, 5.1246534e-05, 4.8753467e-05, 4.6263496e-05, 4.3782813e-05, 4.131759e-05, 3.8873954e-05, 3.6457976e-05, 3.4075667e-05, 3.173295e-05, 2.9435645e-05, 2.7189468e-05, 2.5e-05, 2.2872688e-05, 2.0812817e-05, 1.882551e-05, 1.6915708e-05, 1.5088159e-05, 1.3347407e-05, 1.1697778e-05, 1.0143374e-05, 8.688061e-06, 7.335456e-06, 6.0889215e-06, 4.9515565e-06, 3.9261895e-06, 3.015369e-06, 2.2213596e-06, 1.5461356e-06, 9.913756e-07, 5.584587e-07, 2.4846122e-07, 6.215394e-08, 0.0, 0.0]
parser = argparse.ArgumentParser()
parser.add_argument("data_url", type=str, default='./data/garbage_classify/train_data', help="data dir", nargs='?')
parser.add_argument("train_url", type=str, default='./garbage_ckpt/', help="save model dir", nargs='?')
parser.add_argument("num_classes", type=int, default=40, help="num_classes", nargs='?')
parser.add_argument("input_size", type=int, default=300, help="input_size", nargs='?')
parser.add_argument("batch_size", type=int, default=16, help="batch_size", nargs='?')
parser.add_argument("learning_rate", type=float, default=0.0001, help="learning_rate", nargs='?')
parser.add_argument("max_epochs", type=int, default=30, help="max_epochs", nargs='?')
parser.add_argument("deploy_script_path", type=str, default='', help="deploy_script_path", nargs='?')
parser.add_argument("test_data_url", type=str, default='', help="test_data_url", nargs='?')

import multiprocessing
import numpy as np
import argparse
import tensorflow as tf
from tensorflow.keras.callbacks import TensorBoard, Callback
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, RMSprop
from efficientnet import model as EfficientNet
from data_gen import data_from_sequence
from utils.lr_scheduler import WarmUpCosineDecayScheduler
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
# 注意关闭默认的eager模式
tf.compat.v1.disable_eager_execution()
def train_model(param):
"""训练模型
:param param: 传入的命令参数
:return:
"""
# 1、建立读取数据的sequence
train_sequence, validation_sequence = data_from_sequence(param.data_url, param.batch_size,
param.num_classes, param.input_size)

# 2、建立模型,指定模型训练相关参数
model = model_fn(param)
optimizer = Adam(lr=param.learning_rate)
objective = 'categorical_crossentropy'
metrics = ['accuracy']
# 模型修改
# 模型训练优化器指定
model.compile(loss=objective, optimizer=optimizer, metrics=metrics)
model.summary()
# 判断模型是否加载历史模型
if os.path.exists(param.train_url):
filenames = os.listdir(param.train_url)
model.load_weights(filenames[-1])
print("加载完成!!!")
def model_fn(param):
"""迁移学习修改模型函数
:param param:
:return:
"""
base_model = EfficientNet.EfficientNetB3(include_top=False, input_shape=(param.input_size, param.input_size, 3),
classes=param.num_classes)
x = base_model.output
x = GlobalAveragePooling2D(name='avg_pool')(x)
predictions = Dense(param.num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
return model

sample_count = len(train_sequence) * param.batch_size
epochs = param.max_epochs
warmup_epoch = 5
batch_size = param.batch_size
learning_rate_base = param.learning_rate
total_steps = int(epochs * sample_count / batch_size)
warmup_steps = int(warmup_epoch * sample_count / batch_size)
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=0,
warmup_steps=warmup_steps,
hold_base_rate_steps=0,
)
#(3)模型保存相关参数
check = tf.keras.callbacks.ModelCheckpoint(param.train_url+'weights_{epoch:02d}-{val_acc:.2f}.h5',
monitor='val_acc',
save_best_only=True,
save_weights_only=False,
mode='auto',
period=1)




import tensorflow as tf
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
def main():
num_epochs = 1
batch_size = 32
learning_rate = 0.001
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(120, activation=tf.nn.relu),
tf.keras.layers.Dense(100),
tf.keras.layers.Softmax()
])
(train, train_label), (test, test_label) = \
tf.keras.datasets.cifar100.load_data()
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit(train, train_label, epochs=num_epochs, batch_size=batch_size)
tf.saved_model.save(model, "./saved/mlp/1")
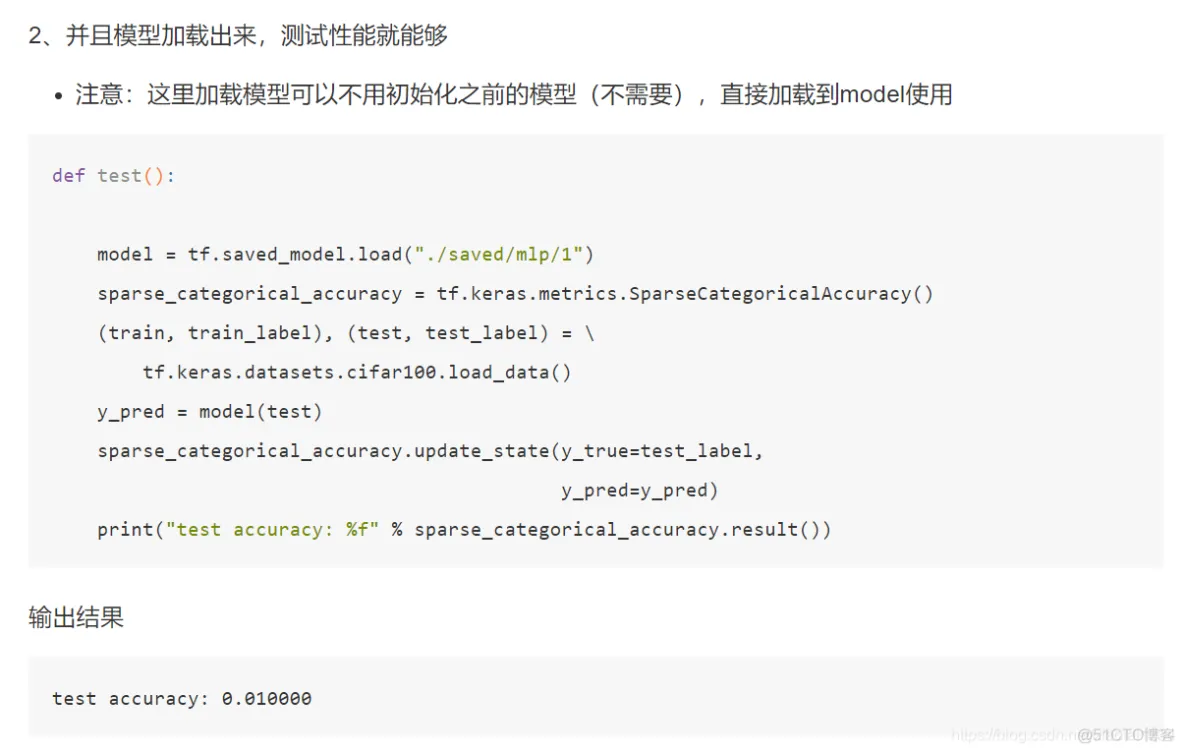



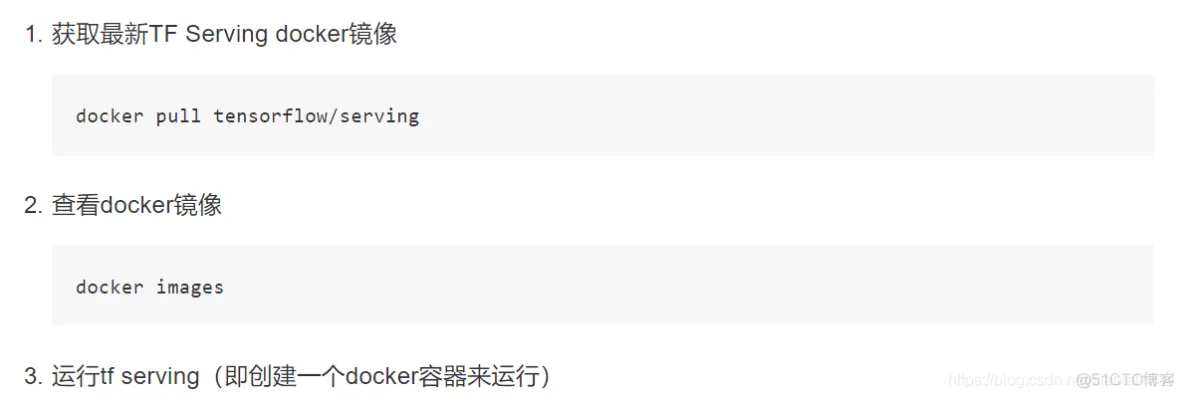
docker run -p 8501:8501 -p 8500:8500 --mount type=bind,source=/home/ubuntu/detectedmodel/commodity,target=/models/commodity -e MODEL_NAME=commodity -t tensorflow/serving

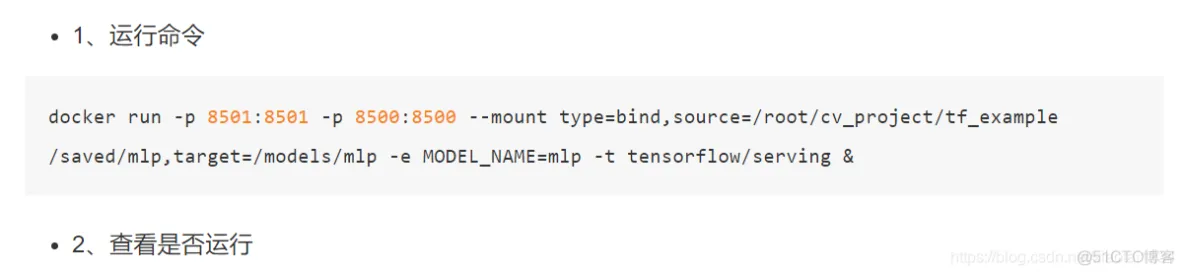
itcast:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS POR
TS NAMES
1354f9aeab33 tensorflow/serving "/usr/bin/tf_serving…" 7 seconds ago Up 5 seconds 0.0
.0.0:8500-8501->8500-8501/tcp gifted_jackson


示例使用Python 的 Requests 库(你可能需要使用 pip install requests 安装该库)向本机的 TensorFlow Serving 服务器发送20张图像并返回预测结果,同时与测试集的真实标签进行比较。
def client():
import json
import numpy as np
import requests
(_, _), (test, test_label) = \
tf.keras.datasets.cifar100.load_data()
data = json.dumps({
"instances": test[0:20].tolist() # array转换成列表形式
})
headers = {"content-type": "application/json"}
json_response = requests.post(
'http://localhost:8501/v1/models/mlp:predict',
data=data, headers=headers)
predictions = np.array(json.loads(json_response.text)['predictions'])
print(np.argmax(predictions, axis=-1))
print(test_label[0:20])
if __name__ == '__main__':
# main()
# test()
client()
输出:
[67 67 67 67 67 67 67 67 67 67 67 67 67 67 67 67 67 67 67 67]
[[49]
[33]
[72]
[51]
[71]
[92]
[15]
[14]
[23]
[ 0]
[71]
[75]
[81]
[69]
[40]
[43]
[92]
[97]
[70]
[53]]
因为模型并没有训练多久,只迭代一次,所以效果不好,主要是完成整个流程。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















