















































软件

产品


import numpy as npimport tensorflow as tfimport matplotlib.pyplot as pltdef moving_average(a,w=10):
if(len(a)<w): return a[:] return [val if idx <w else sum(a[idx-w:idx])/w for idx,
val in enumerate(a)]X_train=np.linspace(-1,1,100)Y_train=2*X_train+np.random.randn(*X_train.shape)*0.3
# 训练数据X=tf.placeholder('float')Y=tf.placeholder('float')# 占位符W=tf.Variable(tf.random_normal([1]),
name='weight')b=tf.Variable(tf.zeros([1]),name='bias')# 定义权重和偏置z=tf.multiply(X,W)+b# 定义前向结构
# 反向模型的搭建即反向优化loss=tf.reduce_mean(tf.square(Y-z))
# 定义学习率:代表调整参数的速度,这个值一般小于一,这个值越大,表明调整幅度的速度越大,但不精确
# 这个值越小,调整幅度越小,但是速度慢learn_rate=0.01
# 定义优化器:GridientDescentOptimizer梯度下降算法optimizer=tf.train.GradientDescentOptimizer(learn_rate)
.minimize(loss)# 迭代训练模型,初始化所有变量init=tf.global_variables_initializer()
# 定义训练次数training_epochs=20# 定义显示信息display_step=2with tf.Session() as sess:
sess.run(init) plot_data={'batch_size':[],'loss_value':[]}
for epoch in range(training_epochs): for x,y in zip(X_train,Y_train):
sess.run(optimizer,feed_dict={X:x,Y:y}) if epoch % display_step == 0:
loss_value = sess.run(loss, feed_dict={X:x, Y:y}) print('Epoch:', epoch + 1, '
Loss=', loss_value, 'w=',sess.run(W),'b=',sess.run(b)) if not (loss == 'NA'):
plot_data['batch_size'].append(epoch) plot_data['loss_value'].append(loss_value)
print('Finished!') # 可视化模型 plt.plot(X_train, Y_train, 'ro', label='Origin data')
plt.plot(X_train, sess.run(W) * X_train + sess.run(b),label='FittedLine') plt.legend()
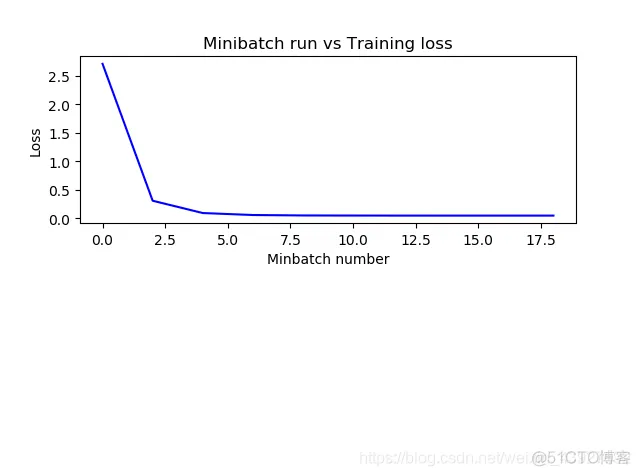
plt.show() plot_data['avgloss']=moving_average(plot_data['loss_value']) plt.figure(1)
plt.subplot(211) plt.plot(plot_data['batch_size'],plot_data['avgloss'],'b',linewidth=1.5)
plt.xlabel('Minbatch number') plt.ylabel('Loss') plt.title('Minibatch run vs Training loss')
plt.show()1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33
.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.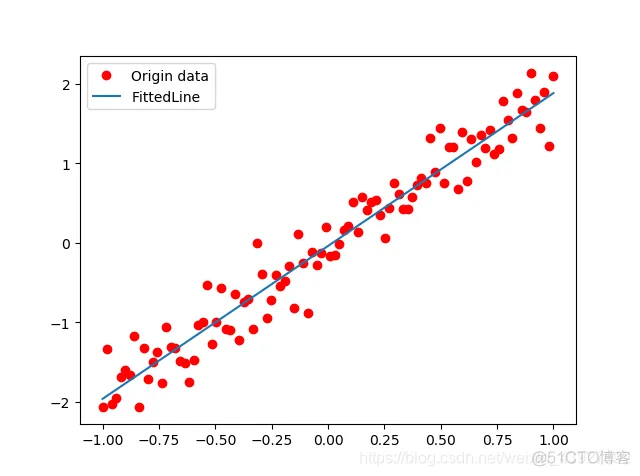
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















