















































软件

产品


最近由于研究方向的更换,接触到了目标检测(Object Detection)领域,觉得很有意思,并且阅读了该方向的相关经典文献,包括Fast-RCNN、Faster-RCNN、SSD、YOLO以及RetinaNet等。复现别人代码并且能够得到在公开数据集上和原作者相近甚至相同的实验结果对于我们做研究甚至以后的工作来说是至关重要的。
1.1:Windows操作系统或者Ubuntu,本博客主要介绍如何在win10下安装、配置以及训练该API
1.2:GPU(本人电脑上的GPU是Nvidia TiTAN X),其它型号的GPU也是可以的,同时该API也可以直接利用CPU对其进行训练
1.3:Anaconda2/3
1.4:CUDA Tool kit(本人用的版本是9.0)
1.5:CuDNN(本人用的是版本是7.0)
对Step1的总结:该步最重要的就是配置CUDA以及CuDNN,本人利用的版本是9.0以及7.0,不过CUDA的版本也可以是8.0,而对应的CuDNN的版本可以是7.0或者6.0。建议利用较新的版本,CUDA和CuDNN详细的安装和配置过程请参考YouTube上的一个视频资源 (https://www.youtube.com/watch?v=RplXYjxgZbw)
在刚开始接触该API之时,经常被相关的安装地址所困惑,本人也查阅了相关的博客,但是有些博主可能认为大家都知道,就没说的那么详细(可能是我本人比较笨吧,哈哈)。首先,我在D盘下新建一个文件夹并命名为tensorflow1,然后到 (https://github.com/tensorflow/models)上点击Download ZIP,将该API的源文件下载到刚才建立的文件夹下并解压,最终的形式如下图:(当然,对于盘的选择以及文件夹的命名,各位可以按照自己的喜好选择)
3.1:创建虚拟环境
打开commond窗口,并执行如下指令:conda create -n tensorflow1 pip python=3.5 python=2.7或者python=3.6都行

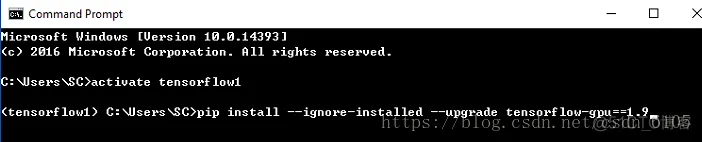
3.2:激活该虚拟环境并安装tensorflow-gpu
在3.1后,首先就是激活刚才创建的虚拟环境:activate tensorflow1 然后安装tensorflow-gpu:pip install --ignore-installed --upgrade tensorflow-gpu==1.9
3.3:安装其它一些必须的包
我们接着在3.2之后的窗口中执行如下指令:
<tensorflow1> C:\Users\SC>conda install -c anaconda protobuf
<tensorflow1> C:\Users\SC>pip install pillow
<tensorflow1> C:\Users\SC>pip install lxml
<tensorflow1> C:\Users\SC>pip install Cython
<tensorflow1> C:\Users\SC>pip install jupyter
<tensorflow1> C:\Users\SC>pip install matplotlib
<tensorflow1> C:\Users\SC>pip install pandas
<tensorflow1> C:\Users\SC>pip install opencv-python
pandas和opencv-python不是该API所必须的包,但是后面在做测试的时候可能会用到。
3.4:配置该API的PYTHONPATH
为了能够使该API正常运行,必须配置好相应的文件路径,具体的操作指令为:
(tensorflow1) C:\Users\SC> set PYTHONPATH=D:\tensorflow1\models;D:\tensorflow1\models\research;D:\tensorflow1\models\research\slim 需要注意的是每当该tensorflow1虚拟环境被激活后,都要重新执行一次上述指令。也可以通过右击我的电脑–>属性–>高级系统设置–>环境变量–>新建系统变量的方式进行设置,这样就可以避免重复执行上述指令。
3.5:编译Protobuf以及安装该API
3.5.1:编译Protobuf
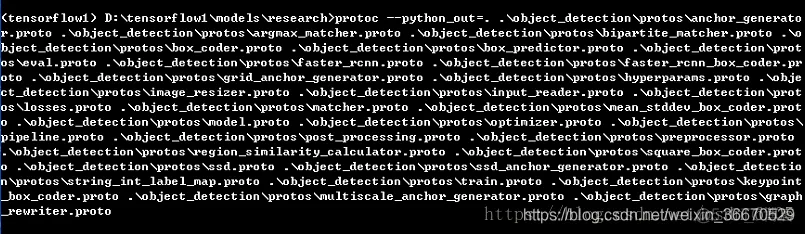
对于Protobuf的介绍,请参见 (https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/index.html)。在3.4后,我们首先cd到该API的research目录下,然后执行如下指令以实现对Protobuf的编译:
<tensorflow1> D:\tensorflow1\models\research>protoc --python_out=.
.\object_detection\protos\anchor_generator.proto .\object_detection\protos\argmax_matcher.proto
.\object_detection\protos\bipartite_matcher.proto .\object_detection\protos\box_coder.proto
.\object_detection\protos\box_predictor.proto .\object_detection\protos\eval.proto
.\object_detection\protos\faster_rcnn.proto .\object_detection\protos\faster_rcnn_box_coder.proto
.\object_detection\protos\grid_anchor_generator.proto .\object_detection\protos\hyperparams.proto
.\object_detection\protos\image_resizer.proto .\object_detection\protos\input_reader.proto
.\object_detection\protos\losses.proto .\object_detection\protos\matcher.proto
.\object_detection\protos\mean_stddev_box_coder.proto .\object_detection\protos\model.proto
.\object_detection\protos\optimizer.proto .\object_detection\protos\pipeline.proto
.\object_detection\protos\post_processing.proto .\object_detection\protos\preprocessor.proto
.\object_detection\protos\region_similarity_calculator.proto .\object_detection\protos\square_box_coder.proto
.\object_detection\protos\ssd.proto .\object_detection\protos\ssd_anchor_generator.proto
.\object_detection\protos\string_int_label_map.proto .\object_detection\protos\train.proto
.\object_detection\protos\keypoint_box_coder.proto
.\object_detection\protos\multiscale_anchor_generator.proto
.\object_detection\protos\graph_rewriter.proto
3.5.2:安装API
在上述操作执行完成后,继续在当前窗口执行如下指令以完成对该API的安装:
<tensorflow1> D:\tensorflow1\models\research>python setup.py build
<tensorflow1> D:\tensorflow1\models\research>python setup.py install
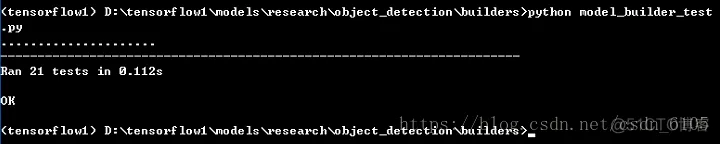
3.6:判断该API是否安装成功以及测试官方demo

如果想要训练一个鲁棒的分类器,该API需要较大量的样本进行训练,但是为了演示如何利用该API训练自己的数据集,我们只是采集了少量的样本并将其分成训练集和测试集。
4.1:利用标注工具进行标注
在这里我们利用的标注工具是LabelImg (https://tzutalin.github.io/labelImg/),具体的使用方式大家可以参考这篇博客 (https://blog.csdn.net/lwplwf/article/details/78367929)。对于样本的采集大家可以按照自己的喜好从网上下载或者从公开数据集中选取部分进行实验,初次接触该API的话建议选取少量的类别。为了节省时间这里我选取的样本是从一个作者的Github里面克隆的 (https://github.com/EdjeElectronics/TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10#1-install-tensorflow-gpu-15-skip-this-step-if-tensorflow-gpu-15-is-already-installed),该作者选取的是扑克牌样本,共有6个类别。所有的训练图片和测试图片都需要进行标注,示例如下:

标注以后,每个图片都会在当前目录下产生一个对应的.xml文件,如下所示:
需要说明一点,建议大家在object_detection目录下新建一个文件夹并命名,然后在里面建立train文件夹和test文件夹用以存放采集的样本,如上图所示。
4.2:将.xml文件转换成csv文件
对于这部分,直接上代码:
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
for folder in ['train','test']:
image_path = os.path.join(os.getcwd(), ('images/' + folder)) //这里就是需要访问的.xml的存放地址
xml_df = xml_to_csv(image_path) // object_detection/images/train or test
xml_df.to_csv(('images/' + folder + '_labels.csv'), index=None)
print('Successfully converted xml to csv.')
main()
上述代码命名为xml_to_csv.py,并存放在object_detection文件夹下。通过运行上述代码,将在images文件夹下产生两个.csv文件,分别为train_labels.csv和test_labels.csv
4.3:将.csv文件转换成TFRecord文件
在步骤4.2完成后,再运行下面代码:
"""
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
# Create test data:
python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('image_dir', '', 'Path to the image directory')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# M1,this code part need to be modified according to your real situation
def class_text_to_int(row_label):
if row_label == 'nine':
return 1
elif row_label == 'ten':
return 2
elif row_label == 'jack':
return 3
elif row_label == 'queen':
return 4
elif row_label == 'king':
return 5
elif row_label == 'ace':
return 6
else:
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), FLAGS.image_dir)
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()
对于步骤4.2和4.3,需要做如下说明:
首先打开commond窗口,然后激活tensorflow1环境,接着根据步骤3.4设置该API的PYTHONPATH,然后cd到object_detection目录下。
1)通过执行python xml_to_csv.py生成相应的.csv文件
2)然后顺序执行下面两条语句
python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
以产生最终的TFRecord格式的文件。其中generate_tfrecord.py是上述代码的命名,输入的.csv文件的路径为csv_input=images/train_labels.csv,图片的存储路径为:image_dir=images/train or test,输出的文件在object_detection文件夹下名称为:train.record 以及 test.record.
4.4:下载预训练的模型,然后进行相关配置
该API为我们提供了很多的预训练的模型,大家可以登录如下网址进行选择下载:
(https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md)
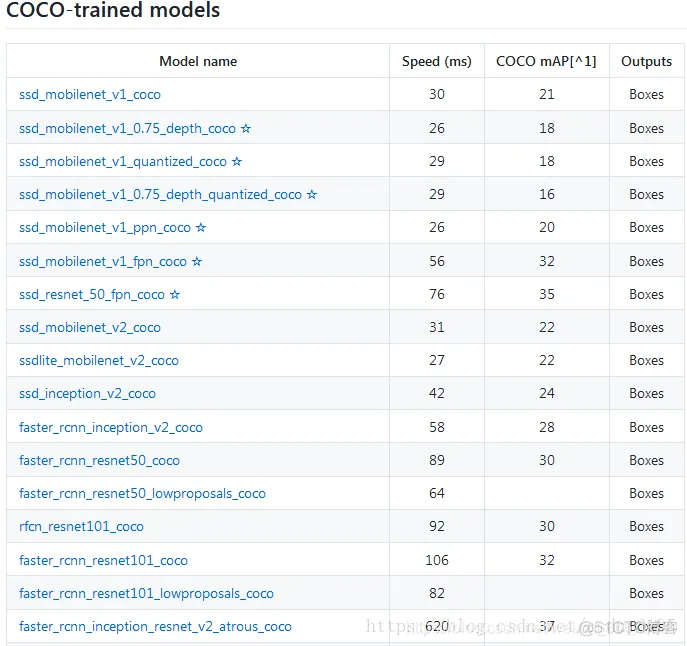
下载的是faster_rcnn_inception_v2_coco模型,并将其放在object_detection文件夹下。下载下来的文件夹名称为:faster_rcnn_inception_v2_coco_2018_01_28
在object_detection文件夹下建立一个training文件夹,然后将上述模型对应的配置文件拷贝到training文件夹下,并进行相应的修改,配置文件的名称为:faster_rcnn_inception_v2_pets,我们需要进行如下修改:(上述模型的配置文件所在的目录为D:\tensorflow1\models\research\object_detection\samples\configs)
# Faster R-CNN with Inception v2, configured for Oxford-IIIT Pets Dataset.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that
# should be configured.
model {
faster_rcnn {
num_classes: 6
image_resizer {
keep_aspect_ratio_resizer {
min_dimension: 600
max_dimension: 1024
}
}
feature_extractor {
type: 'faster_rcnn_inception_v2'
first_stage_features_stride: 16
}
first_stage_anchor_generator {
grid_anchor_generator {
scales: [0.25, 0.5, 1.0, 2.0]
aspect_ratios: [0.5, 1.0, 2.0]
height_stride: 16
width_stride: 16
}
}
first_stage_box_predictor_conv_hyperparams {
op: CONV
regularizer {
l2_regularizer {
weight: 0.0
}
}
initializer {
truncated_normal_initializer {
stddev: 0.01
}
}
}
first_stage_nms_score_threshold: 0.0
first_stage_nms_iou_threshold: 0.7
first_stage_max_proposals: 300
first_stage_localization_loss_weight: 2.0
first_stage_objectness_loss_weight: 1.0
initial_crop_size: 14
maxpool_kernel_size: 2
maxpool_stride: 2
second_stage_box_predictor {
mask_rcnn_box_predictor {
use_dropout: false
dropout_keep_probability: 1.0
fc_hyperparams {
op: FC
regularizer {
l2_regularizer {
weight: 0.0
}
}
initializer {
variance_scaling_initializer {
factor: 1.0
uniform: true
mode: FAN_AVG
}
}
}
}
}
second_stage_post_processing {
batch_non_max_suppression {
score_threshold: 0.0
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 300
}
score_converter: SOFTMAX
}
second_stage_localization_loss_weight: 2.0
second_stage_classification_loss_weight: 1.0
}
}
train_config: {
batch_size: 1
optimizer {
momentum_optimizer: {
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: 0.0002
# schedule {
# step: 0
# learning_rate: .0002
# }
schedule {
step: 900000
learning_rate: .00002
}
schedule {
step: 1200000
learning_rate: .000002
}
}
}
momentum_optimizer_value: 0.9
}
use_moving_average: false
}
gradient_clipping_by_norm: 10.0
# g1
fine_tune_checkpoint: "D:/tensorflow1/models/research/object_detection/faster_rcnn_inception_v2_coco_2018_01_28/model.ckpt"
from_detection_checkpoint: true
# Note: The below line limits the training process to 200K steps, which we
# empirically found to be sufficient enough to train the pets dataset. This
# effectively bypasses the learning rate schedule (the learning rate will
# never decay). Remove the below line to train indefinitely.
num_steps: 20000
data_augmentation_options {
random_horizontal_flip {
}
}
}
# g2
train_input_reader: {
tf_record_input_reader {
input_path: "D:/tensorflow1/models/research/object_detection/train.record"
}
label_map_path: "D:/tensorflow1/models/research/object_detection/training/labelmap.pbtxt"
}
# g3
eval_config: {
num_examples: 67
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 10
}
# g4
eval_input_reader: {
tf_record_input_reader {
input_path: "D:/tensorflow1/models/research/object_detection/test.record"
}
label_map_path: "D:/tensorflow1/models/research/object_detection/training/labelmap.pbtxt"
shuffle: false
num_readers: 1
}
上述配置文件需要修改的地方已经在代码中标注了,具体解释如下:
#g1:此处是fine_tune模型所在的地址
#g2:输入的训练文件(train.record)的地址,以及标签(labelmap.pbtxt)的所在地址
这里也需要对labelmap.pbtxt进行相应的说明:
首先进入到object_detection文件夹下的data文件夹下,然后随机拷贝一个.pbtxt文件到training文件夹下,进行修改,并重命名为labelmap.pbtxt,具体信息如下:(根据自己的实际情况修改)
item {
id: 1
name: 'nine'
}
item {
id: 2
name: 'ten'
}
item {
id: 3
name: 'jack'
}
item {
id: 4
name: 'queen'
}
item {
id: 5
name: 'king'
}
item {
id: 6
name: 'ace'
}
#g3:number_examples是测试样本的个数(这里我们没有创建验证集,直接用测试集进行代替)
#g4:输入的测试文件(test.record)的地址,以及标签(labelmap.pbtxt)的所在地址
4.5:模型训练
在上述东西都准备完成后,我们仍然在当前路径下执行如下指令进行模型训练:
<tensorflow1> D:\tensorflow1\models\research\object_detection>python model_main.py
--logtostderr --model_dir=training/ --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config
其中model_dir是生成文件的存放地址,pipeline_config_path就是配置文件的存放地址。但是大家可能会遇到第一个问题:
1) “error:No modul named pycocotools”
因为之前的COCOAPI没有windows版本,不过在大神们的努力下github里面开源了能够在windows下执行的文件,具体的安装方式为:重新打开commond窗口,然后cd到D:\tensorflow1文件夹下,接着执行如下语句,
D:\tensorflow1>pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
Collecting pycocotools from git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
Cloning https://github.com/philferriere/cocoapi.git to c:\users\pferr\appdata\local\temp\
pip-build-6n1mxmto\pycocotools
Installing collected packages: pycocotools
Running setup.py install for pycocotools ... done
Successfully installed pycocotools-2.0
然后将编译好的pycocotools文件夹拷贝到Tensorflow object detection API 的research文件夹下,就大功告成了。
但是,为了使得上述编译过程可以顺利进行,电脑上面必须要有Visual C++ 14.0,没有的话建议大家下载visual c++ 2015 build tools进行安装。这一块内容是参考 (https://github.com/philferriere/cocoapi/blob/master/README.md)
2)在上述问题解决了之后,大家还可能遇到如下的问题
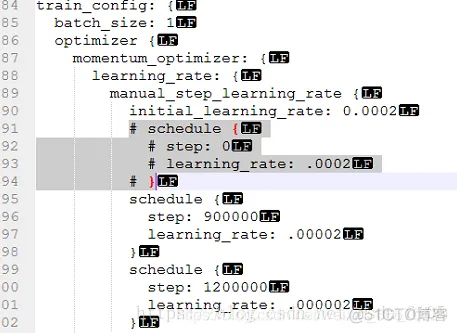
“raise ValueError(‘First step cannot be zero.’)” 解决方案就是修改之前的模型配置文件,具体的操作为:我们首先进入到D:\tensorflow1\models\research\object_detection\training目录下,然后打开配置文件faster_rcnn_inception_v2_pets,然后将下图中的阴影部分给注释掉,然后将initial_learning_rate的值改为和阴影部分中learning_rate的值相同即可:
3)接着我们还可能遇到下述问题
“rv = reductor(4)
TypeError: can’t pickle dict_values objects”
解决方案为:我们进入到D:\tensorflow1\models\research\object_detection下,然后打开model_lib.py文件,接着找到下图中所标出的位置,最后将category_index.values()改为list(category_index.values())即可。
4)待上述问题解决完成后,再执行前面的模型训练语句,但还是会出现错误,主要就是读取完电脑GPU信息后无法继续往下执行,然后提示错误。我上网查了很多解决方案但是都无济于事,偶然间发现了一个博客说最新的目标检测API在利用model_main.py进行训练时可能无法在GPU上顺利执行,因此我们采取了另外一个策略,也即通过运行legacy文件夹下的train.py文件:
<tensorflow1> D:\tensorflow1\models\research\object_detection>python legacy/train.py
--train_dir=training/ --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config
--alsologtostderr
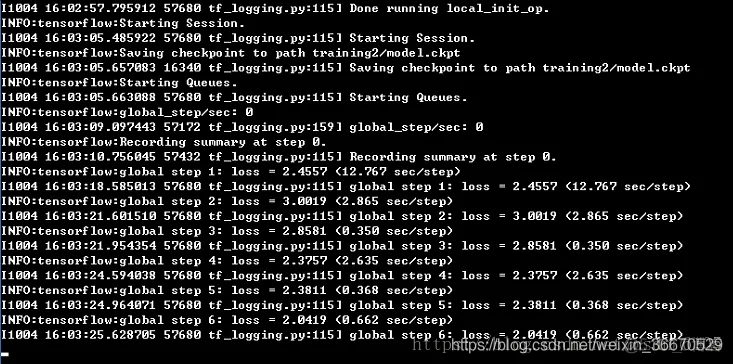
惊喜的发现,问题被解决了,模型可以跑起来了,如下图所示 (前提是,大家一定要把前面出现的问题给解决)。
我们设定的迭代次数是20000次,当迭代次数达到最大后,模型训练结束,我们接着进入到training文件夹下可以看到有如下生成的文件:
4.6:导出Inference Graph
在步骤4.5完成后,模型的训练的就已经finished,接下来就是导出frozen_inference_graph.pb文件,该文件中包含了我们训练好的检测器以及网络架构信息和参数信息等,我们要的就是它。
<tensorflow1> D:\tensorflow1\models\research\object_detection>python export_inference_graph.py
--input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2_pets.config
--trained_checkpoint_prefix training/model.ckpt-20000 --output_directory inference_graph
其中trained_checkpoint_prefix代表checkpoint文件的存放位置,output_directory表示生成的.pb文件的路径,本实验是存放在inference_graph文件夹下。
4.7:测试训练好的检测器
我们在object_detection文件夹下随机放置一张从网上采集的扑克牌图片并命名为test1.jpg,然后在commond窗口中运行下面的代码(代码仍然是放在object_detection文件夹下):
######## Image Object Detection Using Tensorflow-trained Classifier #########
#
# Author: Evan Juras
# Date: 1/15/18
# Description:
# This program uses a TensorFlow-trained classifier to perform object detection.
# It loads the classifier uses it to perform object detection on an image.
# It draws boxes and scores around the objects of interest in the image.
## Some of the code is copied from Google's example at
## https://github.com/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb
## and some is copied from Dat Tran's example at
## https://github.com/datitran/object_detector_app/blob/master/object_detection_app.py
## but I changed it to make it more understandable to me.
# Import packages
import os
import cv2
import numpy as np
import tensorflow as tf
import sys
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
# Import utilites
from utils import label_map_util
from utils import visualization_utils as vis_util
# Name of the directory containing the object detection module we're using
MODEL_NAME = 'inference_graph'
IMAGE_NAME = 'test1.jpg'
# Grab path to current working directory
CWD_PATH = os.getcwd()
# Path to frozen detection graph .pb file, which contains the model that is used
# for object detection.
PATH_TO_CKPT = os.path.join(CWD_PATH,MODEL_NAME,'frozen_inference_graph.pb')
# Path to label map file
PATH_TO_LABELS = os.path.join(CWD_PATH,'training','labelmap.pbtxt')
# Path to image
PATH_TO_IMAGE = os.path.join(CWD_PATH,IMAGE_NAME)
# Number of classes the object detector can identify
NUM_CLASSES = 6
# Load the label map.
# Label maps map indices to category names, so that when our convolution
# network predicts `5`, we know that this corresponds to `king`.
# Here we use internal utility functions, but anything that returns a
# dictionary mapping integers to appropriate string labels would be fine
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# Load the Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
sess = tf.Session(graph=detection_graph)
# Define input and output tensors (i.e. data) for the object detection classifier
# Input tensor is the image
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Output tensors are the detection boxes, scores, and classes
# Each box represents a part of the image where a particular object was detected
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represents level of confidence for each of the objects.
# The score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
# Number of objects detected
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Load image using OpenCV and
# expand image dimensions to have shape: [1, None, None, 3]
# i.e. a single-column array, where each item in the column has the pixel RGB value
image = cv2.imread(PATH_TO_IMAGE)
image_expanded = np.expand_dims(image, axis=0)
# Perform the actual detection by running the model with the image as input
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict={image_tensor: image_expanded})
# Draw the results of the detection (aka 'visulaize the results')
vis_util.visualize_boxes_and_labels_on_image_array(
image,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8,
min_score_thresh=0.80)
# All the results have been drawn on image. Now display the image.
cv2.imshow('Object detector', image)
# Press any key to close the image
cv2.waitKey(0)
# Clean up
cv2.destroyAllWindows()
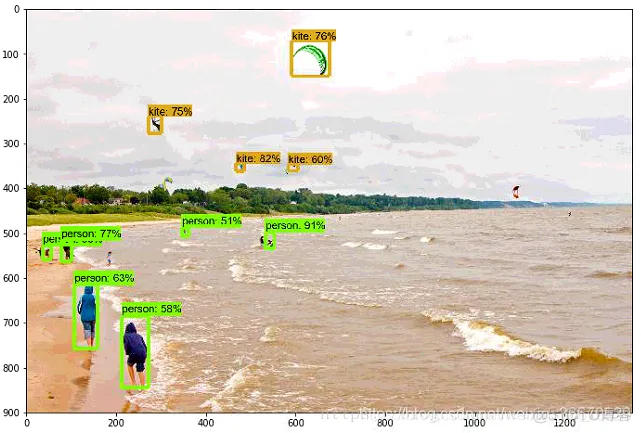
该代码所需的相关的文件以及对应的存放地址已经在代码中列出,各位可以根据自己的实际情况进行更改。最终的可视化测试结果如下,效果还是比较可观的: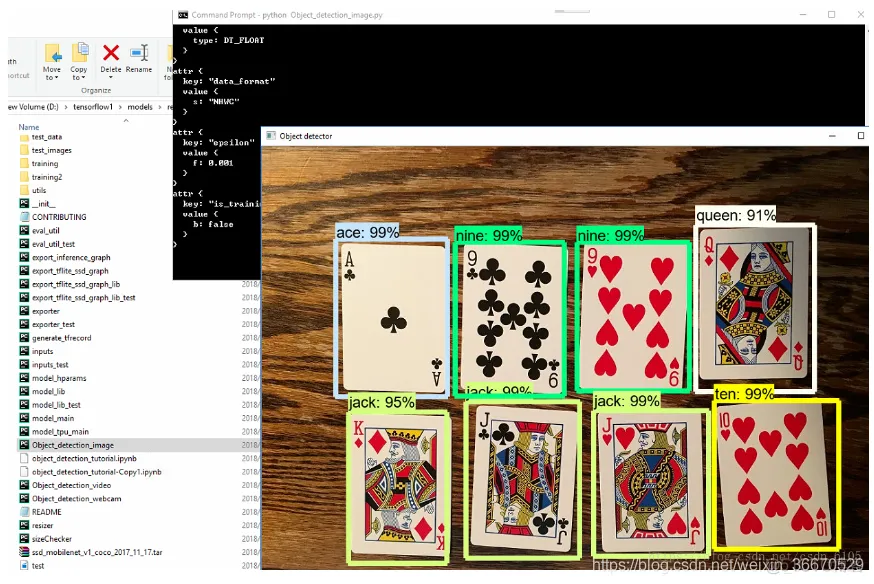
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















