















































软件

产品


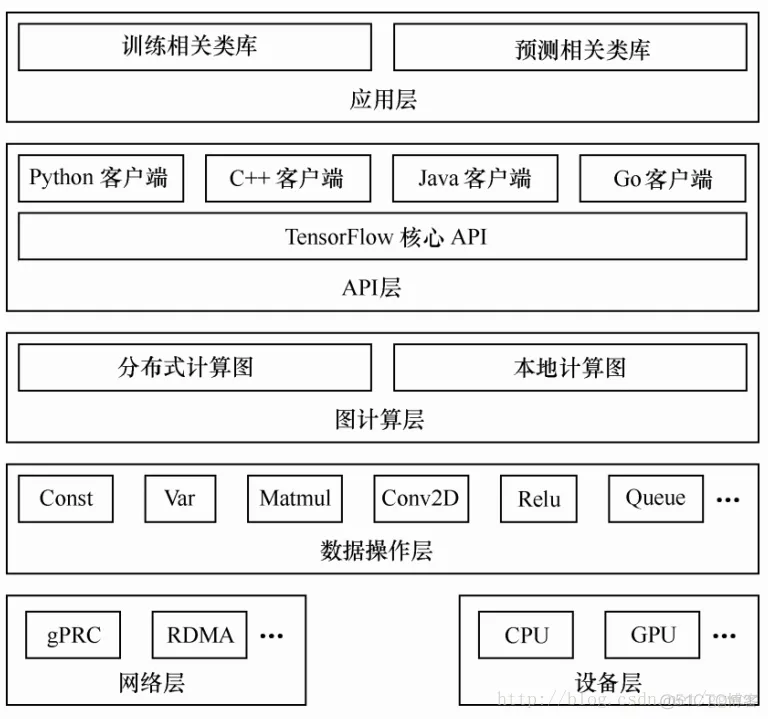
上图是TensorFlow 的系统架构,自底向上分为设备层和网络层、数据操作层、图计算层、 API 层、应用层,其中设备层和网络层、数据操作层、图计算层是TensorFlow 的核心层。
1)网络通信层包括 gRPC(google Remote Procedure Call Protocol)和远程直接数据存取(Remote Direct Memory Access, RDMA),这都是在分布式计算时需要用到的。
2) 设备管理层包括 TensorFlow 分别在 CPU、 GPU、 FPGA 等设备上的实现,也就是对上层提供了一个统一的接口,使上层只需要处理卷积等逻辑,而不需要关心在硬件上的卷积的实现过程。
3) 数据操作层,主要包括卷积函数、激活函数等操作
4) 图计算层,也是我们要了解的核心,包含本地计算图和分布式计算图的实现。

上图讲述了TensorFlow的运行原理。图中包含输入(input)、塑型(reshape)、 Relu 层(Relu layer)、 Logit 层(Logit layer)、 Softmax、交叉熵(cross entropy)、梯度(gradient)、 SGD 训练(SGD Trainer)等部分,是一个简单的回归模型。
它的计算过程是,首先从输入开始,经过塑形后,一层一层进行前向传播运算。 Relu 层(隐藏层)里会有两个参数,即 Wh1和 bh1,在输出前使用ReLu(Rectified Linear Units)激活函数做非线性处理。然后进入 Logit 层(输出层),学习两个参数 Wsm和 bsm。用 Softmax 来计算输出结果中各个类别的概率分布。用交叉熵来度量两个概率分布(源样本的概率分布和输出结果的概率分布)之间的相似性。然后开始计算梯度,这里是需要参数 Wh1、 bh1、 Wsm和 bsm,以及交叉熵后的结果。随后进入 SGD 训练,也就是反向传播的过程,从上往下计算每一层的参数,依次进行更新。也就是说,计算和更新的顺序为 bsm、 Wsm、 bh1和 Wh1。
顾名思义, TensorFlow 是指“张量的流动”。TensorFlow 的数据流图是由节点(node)和边(edge)组成的有向无环图(directed acycline graph, DAG)。TensorFlow 由 Tensor 和 Flow 两部分组成,Tensor(张量)代表了数据流图中的边,而 Flow(流动)这个动作就代表了数据流图中节点所做的操作。
TensorFlow 的边有两种连接关系:数据依赖和控制依赖。
实线边表示数据依赖,代表数据,即张量。张量在数据流图中从前往后流动一遍就完成了一次前向传播(forword propagation而残差从后向前流动一遍就完成了一次反向传播(backword propagation)。
虚线边,称为控制依赖(control dependency),可以用于控制操作的运行,这被用来确保 happens-before 关系,这类边上没有数据流过,但源节点必须在目的节点开始执行前完成执行。常用代码如下:
tf.Graph.control_dependencies(control_inputs)
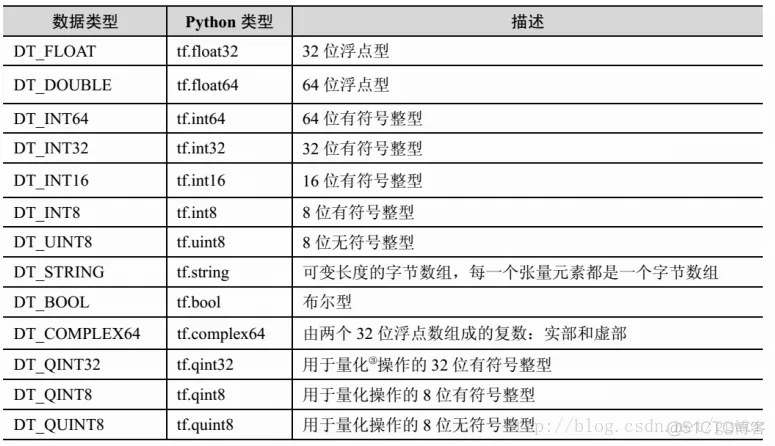
TensorFlow 支持的张量具有下表 所示的数据属性。
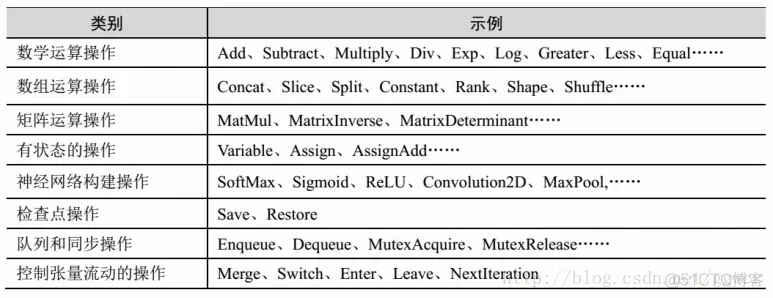
图中的节点又称为算子,它代表一个操作(operation, OP),一般用来表示施加的数学运算,也可以表示数据输入(feed in)的起点以及输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。
构建图的第一步是创建各个节点。具体如下:
import tensorflow as tf
# 创建一个常量运算操作,产生一个 1×2 矩阵
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量运算操作,产生一个 2×1 矩阵
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法运算 ,把 matrix1 和 matrix2 作为输入
# 返回值 product 代表矩阵乘法的结果
product = tf.matmul(matrix1, matrix2)
启动图的第一步是创建一个 Session 对象。会话(session)提供在图中执行操作的一些方法。一般的模式是,建立会话,此时会生成一张空图,在会话中添加节点和边,形成一张图,然后执行。
会话是图交互的一个桥梁,一个会话可以有多个图,会话可以修改图的结构,也可以往图中注入数据进行计算。因此,会话主要有两个 API 接口: Extend 和 Run。 Extend 操作是在 Graph中添加节点和边, Run 操作是输入计算的节点和填充必要的数据后,进行运算,并输出运算结果。
设备(device)是指一块可以用来运算并且拥有自己的地址空间的硬件,如 GPU 和 CPU。 TensorFlow 为了实现分布式执行操作,充分利用计算资源,可以明确指定操作在哪个设备上执行。具体如下:
with tf.Session() as sess:
# 指定在第二个 gpu 上运行
with tf.device("/gpu:1"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















