















































软件

产品


1.TensorFlow 系统架构:
分为设备层和网络层、数据操作层、图计算层、API 层、应用层。其中设备层和网络层、数据操作层、图计算层是 TensorFlow 的核心层。
2.TensorFlow 设计理念:
1)将图的定义和图的运行完全分开。TensorFlow 完全采用符号式编程。
符号式计算一般是先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量之间的计算关系,最后需要对数据流图进行编译,此时的数据流图还是一个空壳,里面没有任何实际数据,只有把需要的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。
如下图所示:定义了一个操作,但实际上并没有运行。
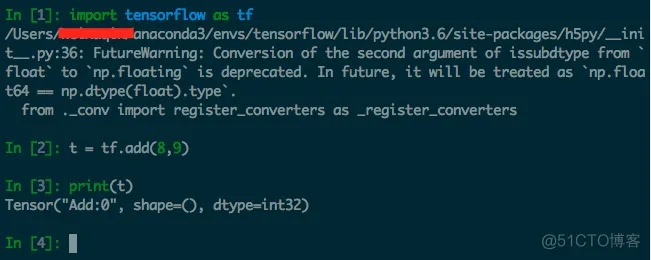
2) TensorFlow 中涉及的运算都要放在图中,而图的运行只发生在会话(session)中。开启会话后,就可以用数据去填充节点,进行运算;关闭会话则不能进行计算。会话提供了操作运行和 Tensor 求值的环境。
一个简单的例子:
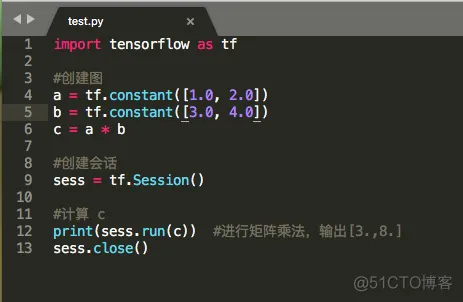
3. TensorFlow 各个概念:
1)边:TensorFlow 的边有两种连接关系:数据依赖(实线表示)和控制依赖(虚线表示)。实现边表示数据依赖,代表数据,即张量。任意维度的数据统称为张量。虚线边称为控制依赖,可以用于控制操作的运行,这类边上没有数据流过,但源节点必须在目的节点开始执行前完成执行。
2)节点:节点代表一个操作,一般用来表示施加的数学运算。
3)图:把操作任务描述成有向无环图。创建图使用 tf.constant() 方法:
a = tf.constant([1.0,2.0])
4)会话:启动图的第一步是创建一个 Session 对象。会话提供在图中执行操作的一些方法。使用 tf.Session() 方法创建对象,调用 Session 对象的 run()方法来执行图:
with tf.Session() as sess:
result = sess.run([product])
print(result)
5)设备:设备是指一块可以用来运算并且拥有自己的地址空间的硬件。方法:tf.device()
6)变量:变量是一种特殊的数据,它在图中有固定的位置,不向普通张量那样可以流动。使用 tf.Variable() 构造函数来创建变量,并且该构造函数需要一个初始值,初始值的形状和类型决定了这个变量的形状和类型。
#创建一个变量,初始化为标量0
state = tf.Variable(0, name="counter")
7)内核:内核是能够运行在特定设备(如 CPU、GPU)上的一种对操作的实现。
4.TensorFlow 批标准化:
批标准化(BN)是为了克服神经网络层数加深导致难以训练而诞生的。
方法:批标准化一般用在非线性映射(激活函数)之前,对 x=Wu+b 做规划化,使结果(输出信号各个维度)的均值为0,方差为1。
用法:在遇到神经网络收敛速度很慢火梯度爆炸等无法训练的情况下,都可以尝试用批标准化来解决。
5.神经元函数:
1)激活函数:激活函数运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络。介绍几个常用的激活函数。
a.sigmoid 函数。sigmoid 将一个 real value 映射到 (0, 1) 的区间,这样可以用来做二分类。
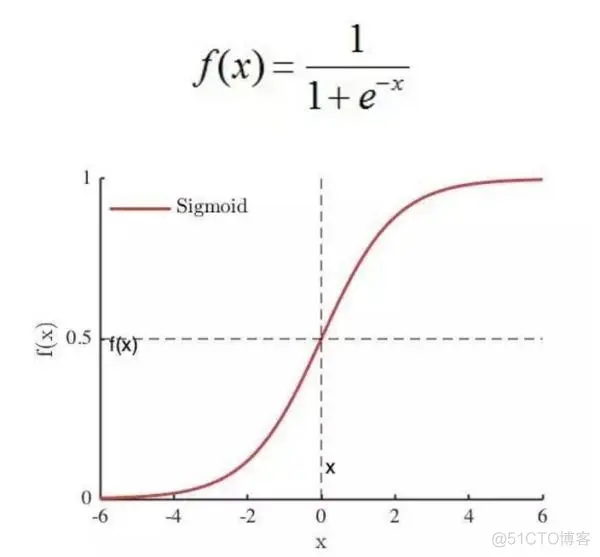
使用方法如下:
a = tf.constant([[1.0,2.0], [1.0, 2.0], [1.0, 2.0]])
sess = tf.Session()
print(sess.run(tf.sigmoid(a))
b.softmax 函数。softmax把一个 k 维的 real value 向量(a1, a2 a3, a4, ...)映射成一个(b1, b2, b3, b4, ...)其中bi 是一个0-1的常数,然后可以根据 bi 的大小来进行多分类的任务,如取权重最大的一维。
函数表达式:
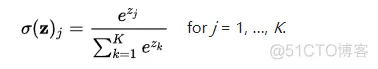
其输出的是一个多维向量,不论有多少个分量,其和加都是1,每个向量的分量维度都是一个小于1的值,这也是与 sigmoid 函数的重要区别。
函数图像:

c.relu 函数。relu 函数可以解决 sigmoid 函数梯度下降慢,消失的问题。
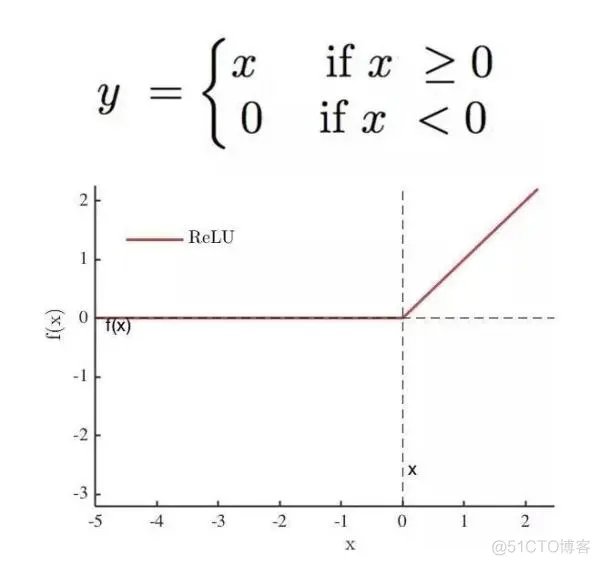
使用方法如下:
a = tf.constant([-1.0, 2.0])
with tf.Session() as sess:
b = tf.nn.relu(a)
print(sess.run(b))
d.dropout 函数。一个神经元将以概率keep_prob 决定是否被抑制。如果被抑制,该神经元输出就为0;如果不被抑制,那么该神经元的输出值将被放大到原来的1/keep_prob 倍。(可以解决过拟合问题)。
使用方法如下:
a = tf.constant([[-1.0, 2.0, 3.0, 4.0]])
with tf.Sessin() as sess:
b = tf.nn.dropout(a, 0.5, noise_shape=[1,4])
print(sess.run(b))
2)卷积函数:卷积函数是构建神经网络的重要支架,是在一批图像上扫描的二维过滤器。这里简单介绍一下卷积函数的几个方法。
a. 这个函数计算 N 维卷积的和。
tf.nn.convolution(input, filter, padding, strides=None, dilation_rate=None, name=None, data_format=None)
b.这个函数的作用是对一个四维的输入数据 input 和四维的卷积核 filter 进行操作,然后对输入数据进行一个二维的卷积操作,最后得到卷积之后的结果。
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None, name=None)
此外还有 tf.nn.depthwise_conv2d()、tf.nn.separable_conv2d() 等方法,这里不再一一说明。
3)池化函数:在神经网络中,池化函数一般跟在卷积函数的下一层池化操作是利用一个矩阵窗口在张量上进行扫描,将每个矩阵窗口中的值通过取最大值或平均值来减少元素个数。每个池化操作的矩阵窗口大小是有 ksize 指定的,并且根据步长 strides 决定移动步长。
a.计算池化区域中元素的平均值。
tf.nn.avg_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
b.计算池化区域中元素的最大值。
tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
6.模型的存储于加载
1)模型存储主要是建立一个 tf.train.Saver() 来保存变量,通过在 tf.train.Saver 对象上调用 Saver.save() 生成,并且制定保存的位置,一般模型的扩展名为 .ckpt。
saver.save(sess, ckpt_dir + "/model.ckpt", global_step=global_step)
2)加载模型可以用 saver.resotre 来进行模型的加载。
with tf.Session() as sess:
tf.initialize_all_variables().run()
ckpt = tf.train.get_checkpoint_state(ckpt_dir)
if ckpt and ckpt.model_checkpoint_path:
print(ckpt.model_checkpoint_path)
saver.restore(sess, ckpt.model_checkpoint_path) #加载所有的参数
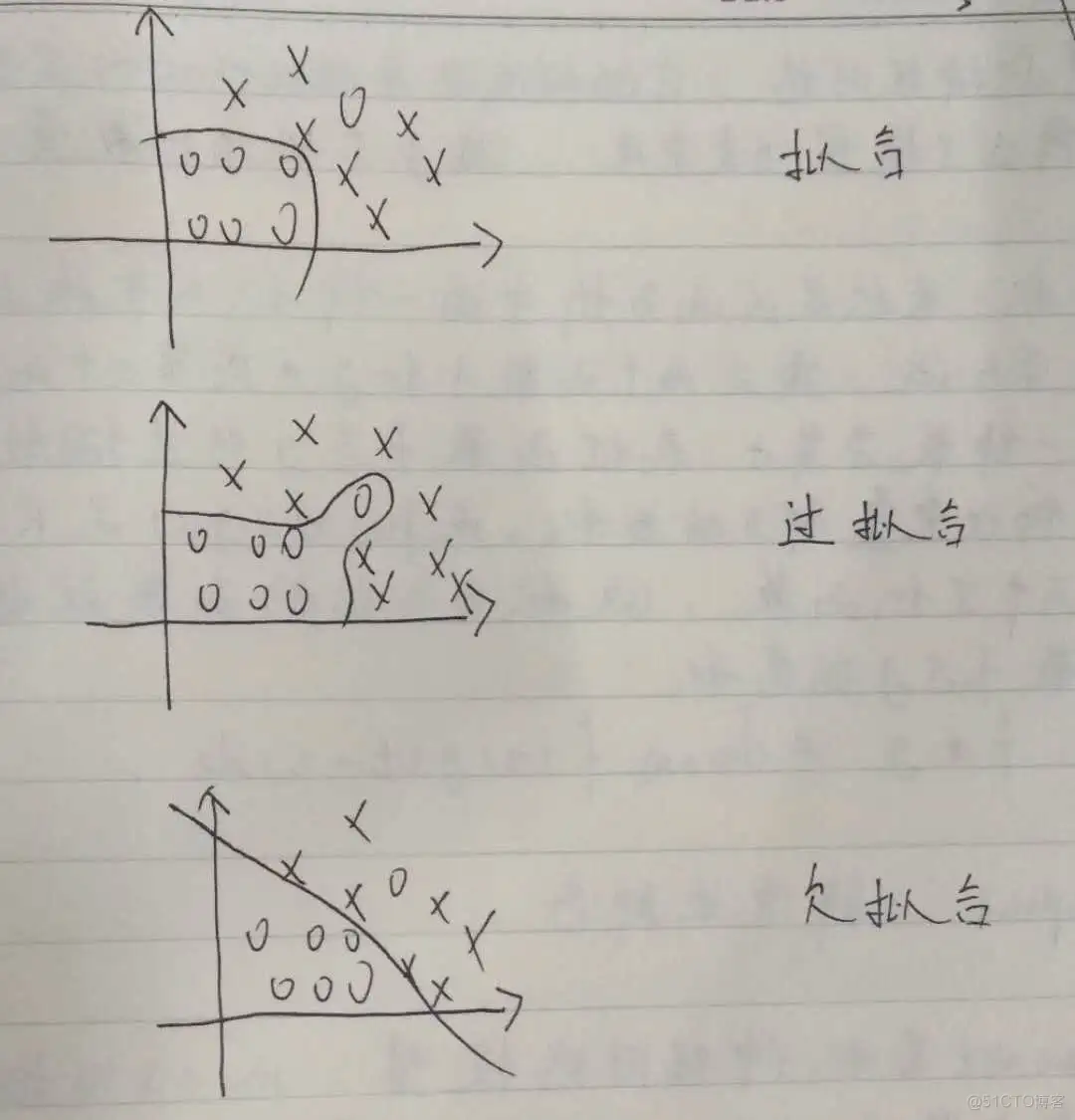
PS: 一张图看懂拟合、过拟合和欠拟合。画的有点丑就是。。。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















