















































软件

产品


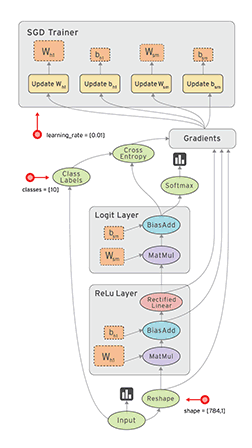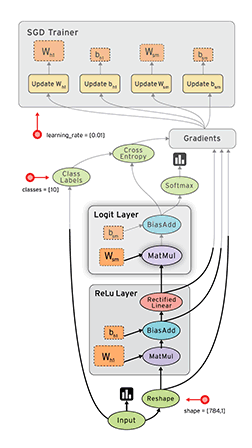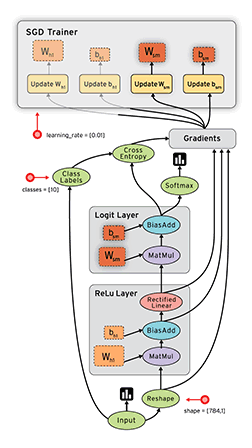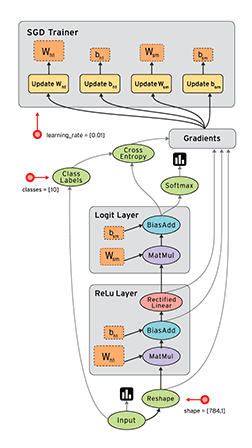
Tensorflow 是一个使用数据流图 (data flow graphs) 技术来进行数值计算的开源软件库。数据流图是是一个有向图,使用节点(一般用圆形或者方形描述,表示一个数学操作或者数据输入的起点和数据输出的终点)和线(表示数字、矩阵或者 Tensor 张量)来描述数学计算。数据流图可以方便的将各个节点分配到不同的计算设备上完成异步并行计算,非常适合大规模的机器学习应用。
TensorFlow支持各种异构的平台,支持多CPU/GPU,服务器,移动设备,具有良好的跨平台的特性;TensorFlow架构灵活,能够支持各种网络模型,具有良好的通用性;此外,TTensorFlow 内核采用 C/C++ 开发,并提供了 C++,Python,Java,Go 语言的 Client API。其架构灵活,能够支持各种网络模型,具有良好的通用性和可扩展性。tensorflow.js支持在web端使用webGL运行GPU训练深度学习模型,支持在IOS、Android系统中加载运行机器学习模型。
TensorFlow的系统结构以C API为界,将整个系统分为「前端」和「后端」两个子系统:
1.前端系统:提供编程模型,负责构造计算图;
2.后端系统:提供运行时环境,负责执行计算图。
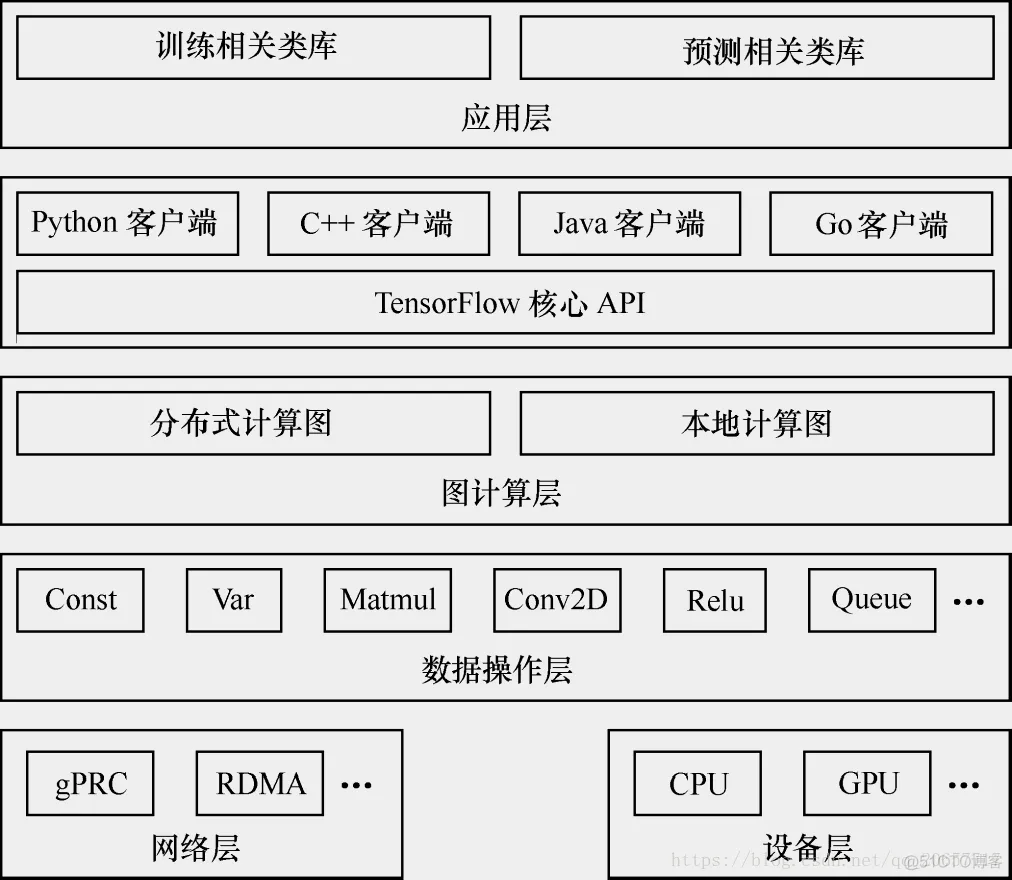
1.支持多语言的客户端,方便用户构造各种复杂的计算图,实现所需的模型设计。客户端以会话为桥梁连接后段的运行时,并启动计算图的执行过程
2.分布式 Master 负责将计算图拆分为多个子图,以便在不通的进程和设备上并行执行
3.Worker Service 负责在硬件环境(如 CPU 或 GPU)上调用 OP 的 Kernel 实现完成图的计算,并从其他 Worker Service 接受计算结果或将计算结果发送给其他 Worker Services
4.数据操作层是 OP 在硬件设备上的特定实现,负责执行 OP 运算,如数值计算、多维数组操作、控制流、状态管理等(如下图所示),每一个OP根据设备类型都会存在一个优化了的Kernel实现。在运行时,运行时根据本地设备的类型,为OP选择特定的Kernel实现,完成该OP的计算。其中,大多数Kernel基于Eigen::Tensor实现。Eigen::Tensor是一个使用C++模板技术,为多核CPU/GPU生成高效的并发代码。但是,TensorFlow也可以灵活地直接使用cuDNN实现更高效的Kernel。
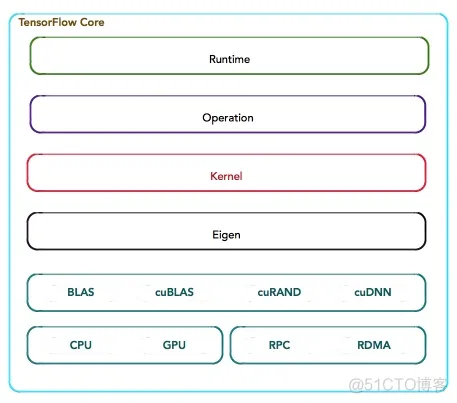
此外,TensorFlow实现了矢量化技术,使得在移动设备,及其满足高吞吐量,以数据为中心的应用需求,实现更高效的推理。
如果对于复合OP的子计算过程很难表示,或执行效率低下,TensorFlow甚至支持更高效的Kernle实现的注册,其扩展性表现相当优越。
假设存在两个任务
/job:ps/task:0: 负责模型参数的存储和更新
/job:worker/task:0: 负责模型的训练或推理
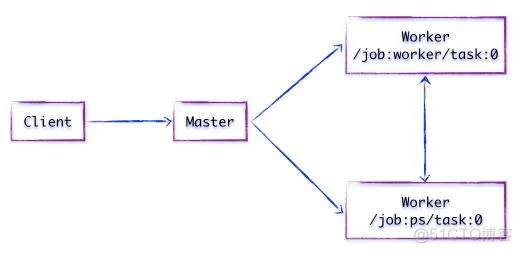
组件交互过程为
1.客户端通过 TensorFlow 的编程接口构造计算图
2.客户端建立 Session 会话,将 Protobuf 格式的图定义GraphDef发送给 Distributed Master
3.Distributed Master 根据 Session.run 的 Fetching 参数,从计算图中反向遍历,找到所依赖的最小子图;然后将该子图再次分裂为多个字图片段,以便在不同进程和设备上运行
4.Distributed Master 将这些子图片段分发给 Work Service,并负责任务集的协同
5.随后 Work Service 启动「本地子图」的执行过程,包括
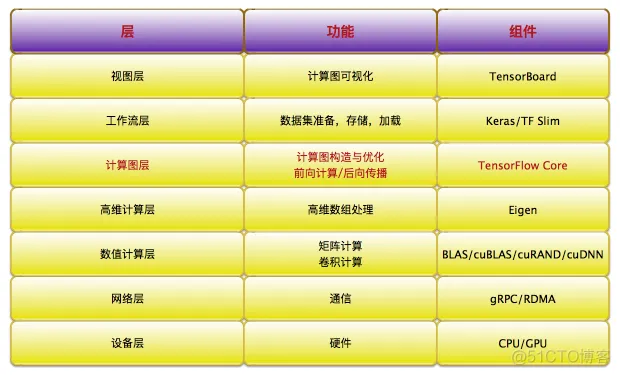
最后,按照TensorFlow的软件层次,通过一张表格罗列TensorFlow的技术栈,以便更清晰地对上述内容做一个简单回顾。
当输入数据是高维且稀疏、特征工程非常困难或者有大规模训练数据且可以fine-tune一个预训练模型时应该使用深度学习模型。
首先要理解正在解决问题的性质,使用目标函数、网络结构去拟合这些性质(多分类问题:交叉熵损失函数。。。)
然后设计合适的模型,最大化模型内的并行度,在模型内进行Embarrassingly parallel的并行计算,在模型内最小化串行依赖,然后最小化每个算子的复杂度。(摘至李嘉璇-tensorflow技术解析与实战作者)
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















