















































软件

产品


本文准备介绍tensorflow对在线学习的支持。所谓在线学习也就是模型一边训练一边服务,与之相对的则是离线学习(或称为批量学习):
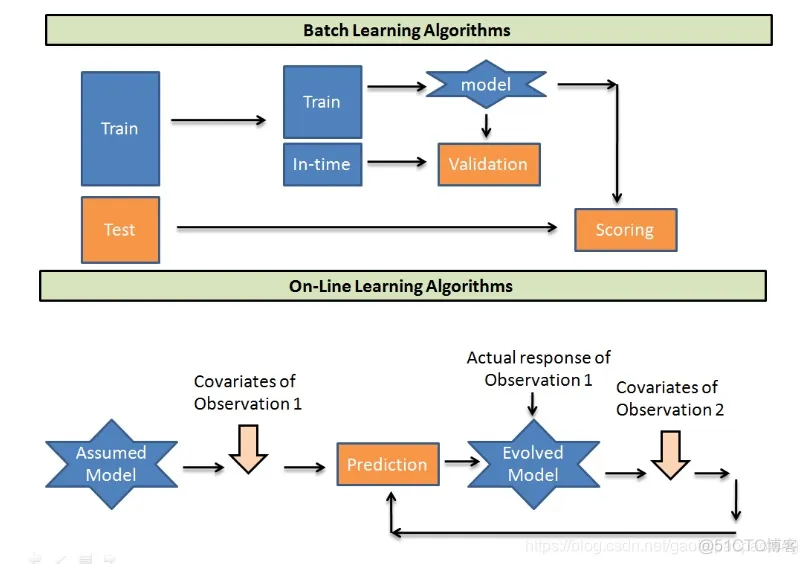
在工程实现上,一般采用架构如下:
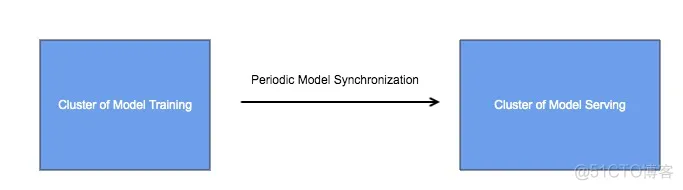
通过周期性的模型同步,将训练集群和服务集群相互隔离,这样做是有必要的,因为两个集群的业务场景不一样,对他们的要求也不一样:
tensorflow体系中,模型训练集群采用tensorflow,模型服务集群一般采用tensorflow serving,模型以文件的形式存储,模型同步是通过文件系统完成的,比如HDFS。tensorflow serving是模型服务方面的高性能开源库,支持模型的版本管理和检查,以及自动更新。
这种结构能满足大多数情况下的业务场景的需求,但是在一些极端场景下,这些还不够。比如作者就曾遇到这样的常见,模型的体积超出了单机内存的上限,如何处理呢?
具体来说,在模型训练的时候,可以采用PS结构,将超大的模型分散到多台参数服务器上;但是到了模型服务的时候,tensorflow serving并不支持PS结构,模型必须单机完整加载模型。
也许你会想到,直接用tensorflow做模型服务,并且也同样采用PS结构呢?
这个架构的问题在于tensorflow ps集群不支持热扩展,当需要添加机器的时候,需要全部重启。
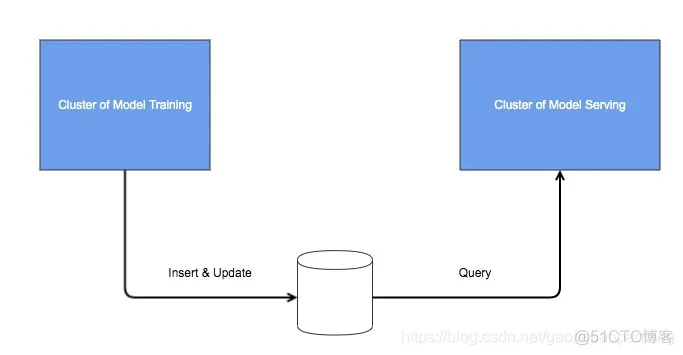
回到我们模型超大的问题,解决这个问题的关键在于tensorflow的一个很好的特征,那就是可以自定义OP。
这里提供一个解决的思路,具体实现的方式可以有很多种方式,就不在这里详述了:
结构如下:
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















