















































软件

产品


TensorFlow 版本1.15pip3 install tensorflow==1.15.0
这是《TensorFlow实战Google深度学习框架(第2版)》的学习笔记,所有代码在TensorFlow 1.15版本中运行正常。虽然现在TensorFlow 2.x很流行了,但是个人觉得先学习下1.x也是很有必要的。
TensorFlow的名字说明了两个最重要的概念——Tensor和Flow。
第一个词Tensor表明了它的数据结构,张量,可理解为多维数组。
而Flow体现了它的计算模型,流。
TensorFlow是一个通过计算图的形式来表达计算的编程,TensorFlow中的每一个计算都是计算图上的一个节点,节点之间的边描述了计算之间的依赖关系。
TensorFlow程序一般可以分为两个阶段。第一个阶段需要定义计算图中所有的计算。第二个阶段执行计算。以下代码给出了计算定义阶段的例子:
import tensorflow as tf# 定义计算图中的计算a = tf.constant([1.0,2.0],
name='a')b = tf.constant([2.0,3.0], name='b')result = a +1.2.3.4.5.除了使用默认的计算图,TensorFlow支持通过tf.Graph函数来生成新的计算图。不同计算图上的张量和运算都不会共享。下面展示如何在不同计算图上定义和使用变量。
import tensorflow as tfg1 = tf.Graph()with g1.as_default():
# 在计算图g1中定义变量v,并设置初始值0 v = tf.get_variable("v",initializer=tf.zeros_initializer()(shape=[1]))
g2 = tf.Graph()with g2.as_default(): # 在计算图g2中定义变量v,并设置初始值1
v = tf.get_variable("v",initializer=tf.ones_initializer()(shape=[1]))
# 在计算图g1中读取变量v的取值with tf.Session(graph=g1) as sess:
# 初始化模型的参数 不加这句会报 Attempting to use uninitialized value v 异常
# 当含有变量时,需要通过这句给变量进行初始化 tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True): print(sess.run(tf.get_variable('v')))
# [0.] # 在计算图g2中读取变量v的取值 with tf.Session(graph=g2) as sess:
tf.global_variables_initializer().run() with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable('v'))) # [1.]1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
20.21.22.23.24.25.TensorFlow中的计算图不仅可以用来隔离张量和计算,还提供了管理张量和计算的机制。
计算图可以通过tf.Graph.device函数来指定运行计算的设备。以下程序可以将加法计算跑在GPU上:
a = tf.constant([1.0,2.0], name='a')b = tf.constant([2.0,3.0], name='b')g = tf
.Graph()with g.device('/gpu:0'): result = a +1.2.3.4.5.6.张量是TensorFlow管理数据的形式。
张量可以理解为多维数组。零阶张量表示标量;第一阶张量为向量,即一维数组;第n阶张量可以理解为一个n维数组。
但在TensorFlow中张量并没有真正保存数字,保存的是如何得到这些数字的计算过程。以向量加法为例,当运行下面代码时,并不会得到加法的结果,而会得到对结果的一个引用。
a = tf.constant([1.0,2.0], name='a')b = tf.constant([2.0,3.0], name='b')result = tf
.add(a, b, name="add")print(result) # Tensor("add_1:0", shape=(2,), dtype=float32)1.2.3.4.从上可以看出,TensorFlow计算的结果是一个张量的结构。一个张量中主要保存了三个属性:名字(name)、维度(shape)和类型(type)。
shape=(2,)说明张量result是一个一维数组,长度为2.一般建议使用dtype来明确指定变量或者常量的类型。
a= tf.constant([l,2],name="a",dtype=tf.float32)1.张量使用主要可以分为两类。
使用张量的第一类情况是对中间结果的引用。当一个计算包含很多中间结果时,使用张量可以大大提高代码的可读性。
# 使用张量记录中间结果a = tf.constant([1.0,2.0], name='a')b = tf
.constant([2.0,3.0], name='b')result = a + b# 直接计算向量的和,
可读性较差result = tf.constant([1.0,2.0], name='a') + tf.constant([2.0,3.0], name='b')1.2.3.4.5.6.7.使用张量的第二类情况是当计算图构造完成之后,张量可以用来获取计算结果。虽然张量本身没有存储具体的结果数字,但通过会话就可以得到这些具体的数字。
会话拥有并管理TensorFlow程序运行时的所有资源。所以计算完成之后需要关闭会话来帮助系统回收资源,否则会出现资源泄漏的问题。
TensorFlow中使用会话的模型一般有两种,第一种需要明确调用会话生成函数和关闭会话函数,这种模式的代码流程如下。
# 定义计算图中的计算a = tf.constant([1.0,2.0], name='a')b = tf
.constant([2.0,3.0], name='b')result = a + b# 创建一个会话sess = tf
.Session()# 使用这个会话来得到运算的结果print(sess.run(result)) # [3. 5.]# 关闭会话,
释放资源sess.close()1.2.3.4.5.6.7.8.9.10.使用这种模式,在完成所有计算之后,需要明确调用Session.close函数来关闭会话并释放资源。然而,当程序因为异常而退出时,关闭会话的函数可能就不会被执行从而导致资源泄漏。为了解决异常退出时资源释放的问题,TensorFlow可通过Python的上下文管理器来使用会话,以下代码展示了如何使用这种模式:
# 定义计算图中的计算a = tf.constant([1.0,2.0], name='a')b = tf.constant([2.0,3.0],
name='b')result = a + b# 创建一个会话,通过上下文管理器来管理这个会话with tf.Session() as sess:
print(sess.run(result)) # [3. 5.]# 当上下文退出时会话关闭和资源释放也自动完成了1.2.3.4.5.6.7.8.9.TensorFlow会自动生成一个默认的计算图,如果没有特殊指定,运算会自动加入这个计算图中。
TensorFlow中的会话也有类似的机制,但TensorFlow不会自动生成默认的会话,而是需要手动指定。
当默认的会话被指定之后可以通过tf.Tensor.eval函数来计算一个张量的取值。如下所示:
# 定义计算图中的计算a = tf.constant([1.0,2.0], name='a')b = tf
.constant([2.0,3.0], name='b')result = a + bsess = tf.Session()with sess.as_default():
#将sess作为默认会话 print(result.eval()) # [3. 5.]1.2.3.4.5.6.7.以下代码也可以完成相同的功能:
# 定义计算图中的计算a = tf.constant([1.0,2.0], name='a')b = tf.constant([2.0,3.0],
name='b')result = a + bsess = tf.Session()print(sess.run(result))print(result
.eval(session=sess))1.2.3.4.5.6.7.在交互式环境下,通过设置默认会话的方式来获取张量的取值更加方便。TensorFlow提供了tf.InteractiveSession函数来在交互式环境下直接构建默认会话。使用这个函数会自动将生成的会话注册为默认会话:
# 定义计算图中的计算a = tf.constant([1.0,2.0], name='a')b = tf
.constant([2.0,3.0], name='b')result = a + bsess = tf.InteractiveSession()print(result.eval())sess
.close()1.2.3.4.5.6.7.通过该函数可以省却将产生的会话注册为默认会话的过程。无论使用哪种方法都可以通过ConfigProto Protocol Buffer来配置需要生成的会话。下面给出了通过ConfigProto配置会话的方法:
config = tf.ConfigProto(allow_soft_placement=True,log_device_placement=True)sess1 = tf
.InteractiveSession(config=config)sess2 = tf.Session(config=config)1.2.3.allow_soft_placement为True时,在以下任意一个条件成立时,GPU上的运算可以放到CPU上进行:
log_device_placement为True时将会在日志中记录每个节点被安排在哪个设备上,以方便调试。
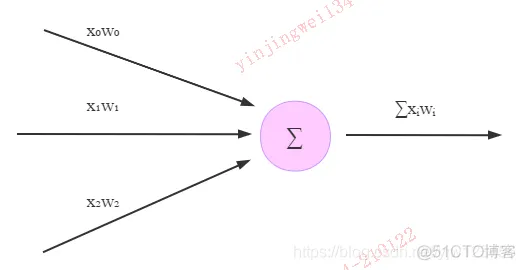
上图是一个最简单的神经元结构,进行的计算就是矩阵乘法。TensorFlow中矩阵乘法是非常容易实现的。
a = tf.matmul(x,w)1.在TensorFlow中,变量(tf.Variable)的作用就是保存和更新神经网络中的参数。和其他编程语言类似, TensorFlow中的变量也需要指定初始值。因为在神经网络中,给参数赋予随机初始值最为常见,所以一般也使用随机数给TensorFlow中的变量初始化。 下面给出了一种在TensorFlow中声明一个的矩阵变量的方法:
weights = tf.Variable(tf.random_normal([2, 3], stddev=2))1.这段代码会产生一个的矩阵,矩阵中元素是均值为0,标准差为2的随机数。下表中给出了TensorFlow中常用的变量声明方法。
| 函数名称 | 功能 | 样例 |
| tf.zeros | 产生全0的数组 | tf.zeros([2,3],int32) -> [[0,0,0],[0,0,0]] |
| tf.ones | 产生全1的数组 | tf.ones([2,3],int32) -> [[1,1,1],[1,1,1]] |
| tf.fill | 产生一个全部为给定数字的数组 | tf.fill([2,3],9) ->[[9,9,9],[9,9,9]] |
| tf.constant | 产生一个给定值的常量 | tf.constant([1,2,3]) -> [1,2,3] |
在神经网络中,偏置(bias)通常会使用常数来设置初始值。以下代码给出了一个样例。
bias = tf.Variable(tf.zeros([3]))1.除了使用随机数或常数,TensorFlow也支持通过其他变量的初始值来初始化新的变量:
w2 = tf.Variable(weights.initialized_value())w3 = tf.Variable(weights.initialized_value() * 2.0)1.2.w2的初始值被设置为与weights变量相同。w3的初始值则是weights初始值的两倍。在TensorFlow中,一个变量的值在被使用之前,这个变量的初始化过程需要被明确地调用。以下样例介绍了如何通过变量实现神经网络的参数并实现前向传播过程。
import tensorflow as tf# 声明w1,w2两个变量。指定随机种子w1 = tf
.Variable(tf.random_normal((2,3), stddev=1, seed=1))w2 = tf
.Variable(tf.random_normal((3,1), stddev=1, seed=1))
# 暂时将输入的特征向量定义为一个常量x = tf.constant([[0.7, 0.9]])
# 1 x 2 的矩阵# 通过前向传播算法获得神经网络的输出a = tf
.matmul(x, w1)y = tf.matmul(a, w2)sess = tf.Session()
# 初始化w1和w2两个变量sess.run(w1.initializer)sess
.run(w2.initializer)print(sess.run(y))
# [[3.957578]]sess.close()1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.在计算y之前,需要将所有用到的变量初始化。虽然在变量定义时给出了变量初始化的方法,但这个方法并没有被真正运行。
所以在计算y之前,需要通过运行w1.initializer和w1.initializer来给变量赋值。
虽然这样直接调用每个变量的初始化过程是一个可行的方案,但是当变量数目增多,或变量之间存在依赖关系时,单个调用的方案就比价麻烦了。
为了解决这个问题,TensorFlow提供了一种更加便捷的方式来完成变量初始化过程。
init_op = tf.global_variables_initializer()sess.run(init_op)1.2.通过tf.global_variables_initializer函数,就不需要将变量一个一个初始化了。我们知道,TensorFlow的核心概念是张量,那么变量和张量是什么关系呢?
在TensorFlow中,变量的声明函数tf.Variable是一个运算。这个运算的输出结果就是一个张量,这个张量也是本节介绍的变量。所以变量只是一种特殊的张量。
所有的变量都会被自动加入到GraphKeys.VARIABLES这个集合中。通过tf.global_variables()函数可以拿到当前计算图上所有的变量。
当构建机器学习模型时,可以通过变量声明函数中的trainable参数来区分需要优化的参数和其他参数。如果声明变量时参数trainable为True,那么这个变量将会被加入到GraphKeys.TRAINABLE_VARIABLES集合。
可以通过tf.trainable_variables()函数得到所有需要优化的参数。TensorFlow中提供的神经网络优化算法会将GraphKeys.TRAINABLE_VARIABLES集合中的变量作为默认的优化对象。
一个变量在构建之后,它的类型就不能再改变了。它就不能被赋予其他类型的值,以下代码会报出类型不匹配错误:
w1 = tf.Variable(tf.random_normal([2,3], stddev=1),name='w1')w2 = tf.Variable(tf
.random_normal([2,3], dtype=tf.float64,stddev=1),name='w2')w1.assign(w2)1.2.3.通过TensorFlow实现反向传播算法的第一步是使用TensorFlow表达一个batch的数据。在前面我们尝试使用常量来表达过一个样例:
x = tf.constant([[0.7, 0.9]])1.但是如果每轮迭代中的数据都要通过常量来表示,那么TensorFlow的计算图将会太大。因为每生成一个变量,TensorFlow都会在计算图中增加一个节点。一般来说,一个神经网络的训练过程会需要经过几百万轮甚至几亿轮的迭代,这样计算图就会非常大,而且利用率很低。
为了避免这个问题,TensorFlow提供了placeholder机制用于提供输入数据。placeholder占位符的意思,相当于定义了一个位置,这个位置中的数据在程序运行时再指定。这样在程序中就不需要生成大量常量来提供输入数据,而只需要将数据通过placeholder传入TensorFlow计算图。在placeholder定义时,这个位置上的数据类型是需要指定的。和其他张量一样,placeholder的类型也是不可改变的。
placeholder中数据的维度信息可以根据提供的数据推导得出,所以不一定要给出。下面给出了通过placeholder实现前向传播算法的代码。
import tensorflow as tfw1 = tf.Variable(tf.random_normal([2,3], stddev=1),
name='w1')w2 = tf.Variable(tf.random_normal([3,1], stddev=1),name='w2')
# 定义placeholder作为存放输入数据的地方。这里维度不一定要定义# 但如果维度是确定的,
那么给出维度可以降低出错的概率x = tf.placeholder(tf.float32, shape=(1,2), name='input')a = tf
.matmul(x, w1)y = tf.matmul(a, w2)sess = tf.Session()init_op = tf
.global_variables_initializer()sess.run(init_op)# 下面这行将报错# print(sess.run(y))
# InvalidArgumentError: You must feed a value for placeholder tensor
'input' with dtype float and shape [1,2]# 下面这行不会print(sess.run(y,
feed_dict={x: [[0.7, 0.9]]}))1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.在这段代码中计算前向传播结果时,需要提供一个feed_dict来指定x的取值。feed_dict是一个字典,在字典中需要给出每个用到的placeholder的取值。如果某个需要的placeholder没有被指定取值,那么程序将会报错。
以上代码只计算了一个样例的前向传播结果,但在训练神经网络时需要每次提供一个batch的训练样例。对于这样的需求,placeholder也可以很好地支持。
在上面的程序中,如果将输入的矩阵改为的矩阵,那么就可以得到n个样例的前向传播结果了。 得到前向传播的结果为的矩阵,这个矩阵的每一行就代表了一个样例的前向传播结果。以下代码给出了一个示例:
import tensorflow as tfw1 = tf.Variable(tf.random_normal([2,3], stddev=1),
name='w1')w2 = tf.Variable(tf.random_normal([3,1], stddev=1),name='w2')
# 这里假设batch大小为3,n=3x = tf.placeholder(tf.float32, shape=(3,2),
name='input')a = tf.matmul(x, w1)y = tf.matmul(a, w2)sess = tf.
Session()init_op = tf.global_variables_initializer()sess.run(init_op)
# 下面这行将报错# print(sess.run(y)) # InvalidArgumentError:
You must feed a value for placeholder tensor 'input' with dtype float and shape [1,2]
# 下面这行不会print(sess.run(y, feed_dict={x: [[0.7, 0.9],[0.1, 0.4],[0.5, 0.8]]}))1.2.3.4.5.6.7.8.9.10.
11.12.13.14.15.16.17.18.输出结果为:
[[-4.2367287] [-1.478172 ] [-3.5316126]]1.2.3.在得到一个batch的前向传播结果之后,需要定义一个损失函数来刻画当前的预测值和真实值之间的差距。然后通过反向传播算法来调整神经网络参数的取值是的差距可以被缩小。下面定义一个简单的损失函数,并通过TensorFlow定义了反向传播的算法:
y = tf.sigmoid(y)# 定义损失函数来刻画预测值与真实值的差距cross_entropy = -tf
.reduce_mean( y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)) + (1-y)
* tf.log(tf.clip_by_value(1-y, 1e-10, 1.0)))# 定义学习率learning_rate = 0.001
# 定义反向传播算法来优化神经网络中的参数train_step = tr.train
.AdamOptimizer(learning_rate).minimize(cross_entropy)1.2.3.4.5.6.7.8.9.在定义了反向传播算法后,通过运行sess.run(train_step)就可以对所有在GraphKeys.TRAINABLE_VARIABLES集合中的变量进行初始化,使得在当前batch下损失函数更小。下面给出一个完整的训练神经网络样例程序。
import tensorflow as tffrom numpy.random import RandomState
# 定义训练数据batch的大小batch_size = 8
# 定义神经网络的参数w1 = tf.Variable(tf.random_normal([2,3], stddev=1),name='w1')w2 = tf
.Variable(tf.random_normal([3,1], stddev=1),name='w2')
# 在shape的一个维度上用None可以方便使用不同的batch大小。
x = tf.placeholder(tf.float32, shape=(None,2), name='x-input')y_ = tf
.placeholder(tf.float32, shape=(None,1), name='y-input')
# 定义神经网络前向传播的过程a = tf.matmul(x, w1)y = tf.matmul(a, w2)
# 定义损失函数和反向传播的算法y = tf.sigmoid(y)cross_entropy = -tf.reduce_mean( y_
* tf.log(tf.clip_by_value(y, 1e-10, 1.0)) + (1-y) * tf.log(tf.clip_by_value(1-y, 1e-10, 1.0)))
# 定义学习率learning_rate = 0.001# 定义反向传播算法来优化神经网络中的参数train_step = tf
.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
# 通过随机数生成一个模拟数据集rdm = RandomState(1)dataset_size = 128X = rdm.rand(dataset_size, 2)
# 定义规则设置样本的标签 0表示负样本,1表示正样本Y = [[int(x1 + x2 < 1)] for (x1, x2) in X]
# 创建一个会话来运行程序with tf.Session() as sess: init_op = tf.global_variables_initializer()
# 初始化变量 sess.run(init_op) print(sess.run(w1)) print(sess.run(w2))
# 设置训练的轮数 STEPS = 5000 for i in range(STEPS):
# 每次选取batch_size个样本进行训练 start = (i * batch_size) % dataset_size
end = min(start + batch_size, dataset_size)
# 通过选取的样本训练神经网络并更新参数 sess.run(train_step,
feed_dict={x: X[start:end], y_: Y[start:end]}) if i % 1000 == 0:
# 每隔一段时间计算在所有数据上的交叉熵并输出 total_cross_entropy = sess.run(cross_entropy,
feed_dict={x: X, y_ : Y}) print('After %d training step(s),
cross entropy on all data is %g' % (i, total_cross_entropy)) print(sess.run(w1))
print(sess.run(w2))1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.
29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.输出为:
After 0 training step(s), cross entropy on all data is 0.763093After 1000 training step(s),
cross entropy on all data is 0.339521After 2000 training step(s),
cross entropy on all data is 0.0988844After 3000 training step(s),
cross entropy on all data is 0.0507982After 4000 training step(s),
cross entropy on all data is 0.0306918[[ 1.3071561 -0.8735636 2.927468 ]
[ 3.5681686 -0.4556637 4.314473 ]][[ 1.750785 ] [-1.4868999] [ 2.7453477]]1.2.3.4.5.6.7.8.9.10.以上程序实现了训练神经网络的全部过程。从这个程序可以总结出训练神经网络的过程可以分为三个步骤:
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















