















































软件

产品


深度学习后面的数学概念已经存在10多年,但是深度学习框架是最近几年才出来的。现在大量的框架在灵活性上和便于工业界使用上做了权衡,灵活性对于科研非常重要,但是对于工业界太慢了,但是换句话说,足够快,能够用于分布式的框架只适用于特别的网络结构,这对科研又不够灵活。
这留给了使用者一个矛盾的境地:我们是否应该尝试用没有那么灵活的框架做科研,这样当应用于工业界的时候,我们不必再重新用另外一个框架复现代码;或者是我们是否应该在做研究的时候使用一个框架,在工业界应用的时候使用另外一个完全不同的框架呢?
如果选择前者,那么做研究的时候并不方便尝试很多不同类型的网络,如果选择后者,我们必须要重新复现代码,这容易导致实验结果和工业应用上不同,我们也需要付出很多精力去学习。
TensorFlow的出现希望解决这个矛盾的事情。
0-d tensor:标量,1-d tensor:向量,2-d tensor:矩阵
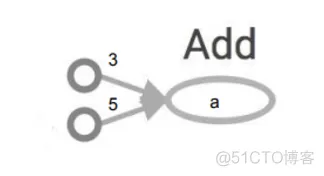
import tensorflow as tf
a = tf.add(3, 5)
print(a)
>> Tensor("Add: 0", shape=(), dtype=int32)
并不能得到8,需要开启session,在session中操作能够被执行,Tensor能够被计算,这点有点反人类,跟一般的推断式编程是不同的,比如PyTorch
import tensorflow as tf
a = tf.add(3, 5)
sess = tf.Session()
print(sess.run(a))
sess.close()
>> 8
当然可以使用一种更高效的写法
import tensorflow as tf
a = tf.add(3, 5)
with tf.Session() as sess:
print(sess.run(a))
当然可以建立更复杂的计算图如下
x = 2
y = 3
add_op = tf.add(x, y)
mul_op = tf.mul(x, y)
useless = tf.mul(x, add_op)
pow_op = tf.pow(add_op, mul_op)
with tf.Session() as sess:
z, not_useless = sess.run([pow_op, useless])
在sess.run调用的时候使用[]来得到多个结果。
也可以将图分成很多小块,让他们在多个CPU和GPU下并行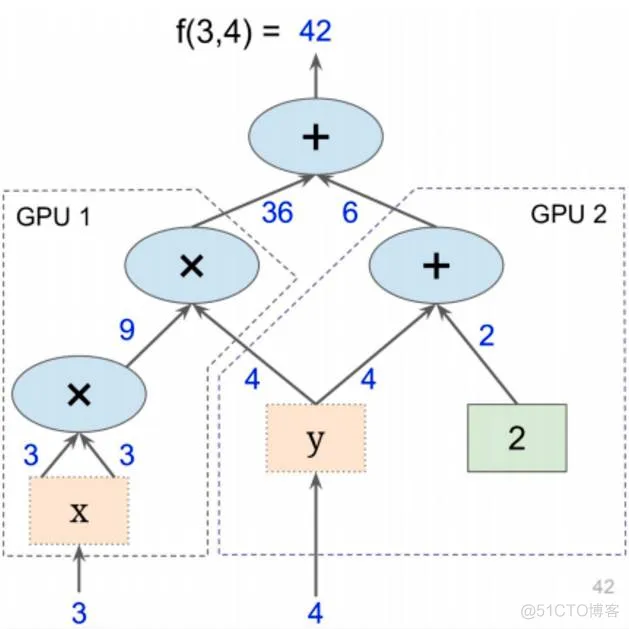
可以将计算图的一部分放在特定的GPU或者CPU下
with tf.device('/gpu:2'):
a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]], name='a')
b = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
尽量不要使用多个计算图,因为每个计算图需要一个session,而每个session会使用所有的显卡资源,必须要用python/numpy才能在两个图之间传递数据,最好在一个图中建立两个不联通的子图
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















