















































软件

产品


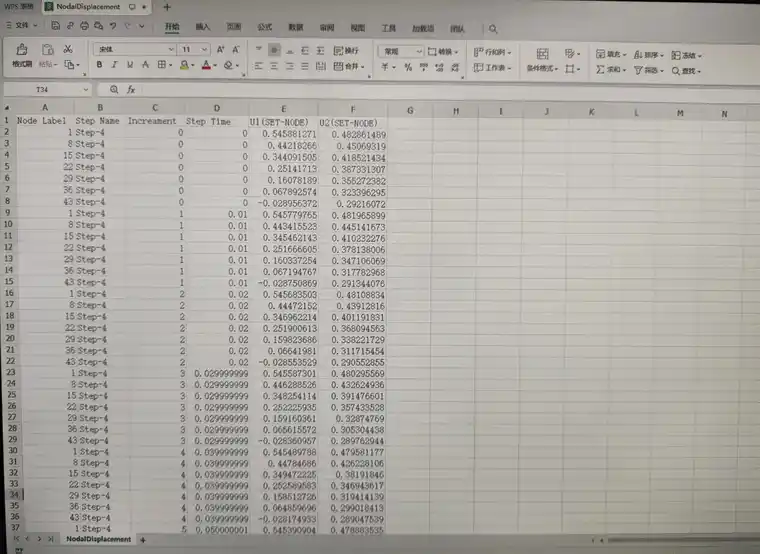
本文介绍如何使用Python脚本二次开发来批量提取ABAQUS输出数据库(ODB)文件中指定Step下的Set节点集变形量。通过详细的步骤说明、代码示例和图片展示,您将学会如何使用该脚本,自动化输出CSV文件包含(Node Label;Step Name、Increment、Step Time,U1,U2)。
如果还需要按Increment提取每个增量下的变形后的节点坐标的话,在提取变形量的基础上,与初始坐标进行简单的计算就可以求得坐标。 (备注:该代码只提取了x,y方向的变形量)
在工程仿真和分析领域,提取ABAQUS输出数据库(ODB)文件中的节点集变形量是一项常见任务。然而,手动提取这些数据是一项繁琐且容易出错的工作。因此,需要一种自动化的方法来批量提取指定步骤下按节点集组织的变形量数据。
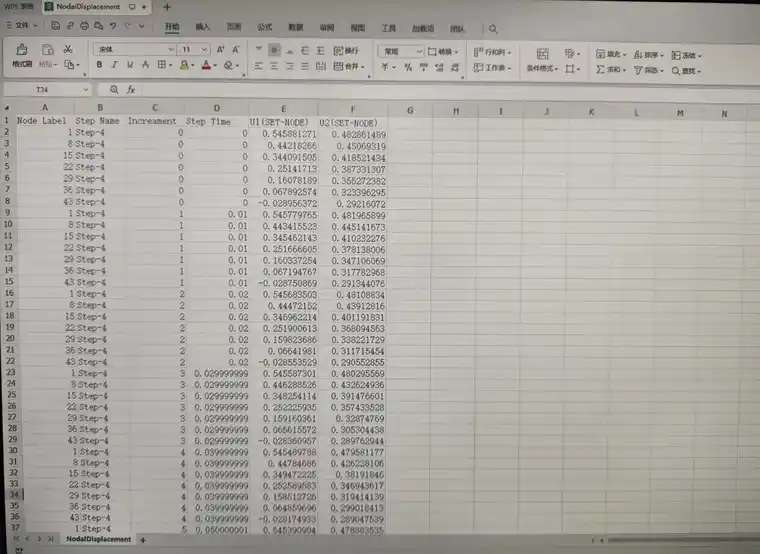
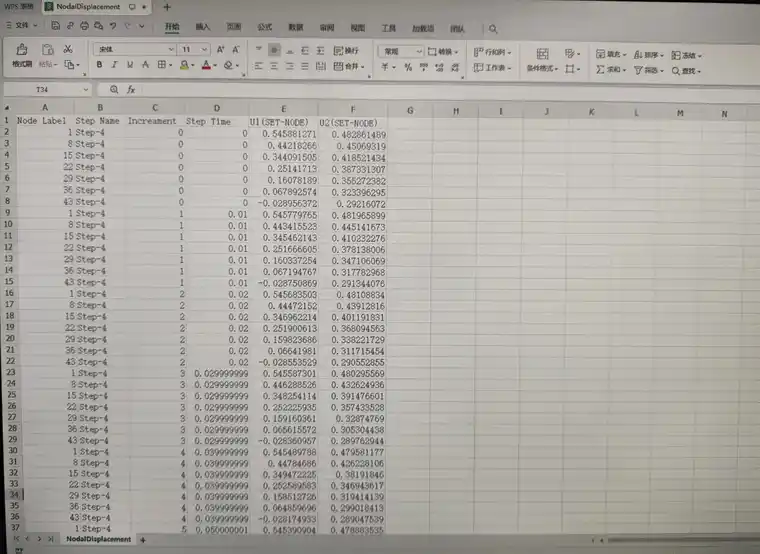
假设我们有一个名为`example.odb`的ODB文件,其中包含名为`Step-x`的步骤和名为`Set-x`的节点集。运行以上代码后,脚本会自动将该步骤下节点集的变形量提取出来,并保存为`NodalDisplacement.csv`文件。(图片展示的是名为`Step-4`的步骤和名为`SET-NODE`的节点集)
1. 在脚本中,设置待处理的ODB文件放置目录。
2. 在脚本中,设置要提取的步骤名称`step_name`和节点集名称`set_name`。
3. 在脚本中,设置一下保存的文件名称。(提取的数据将以CSV格式保存在待处理的ODB文件放置目录下)
打开Abaqus,输入测试代码,按部就班完成测试,方便后期查询问题。
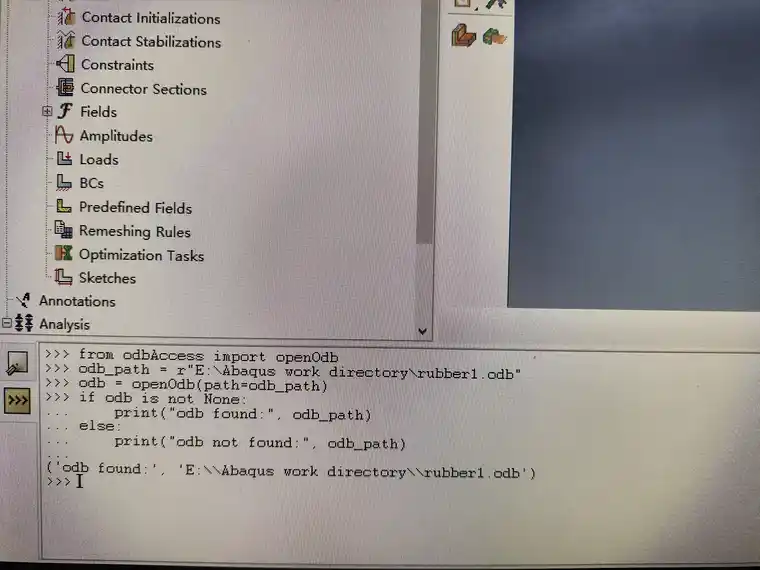
1.识别路径下odb文件是否存在。
from odbAccess import openOdb
odb_path = r"E:\Abaqus work directory\rubber1.odb" #输入读取路径下的odb文件#
odb = openOdb(path=odb_path)
if odb is not None:
print("odb found:", odb_path)
else:
print("odb not found:", odb_path)
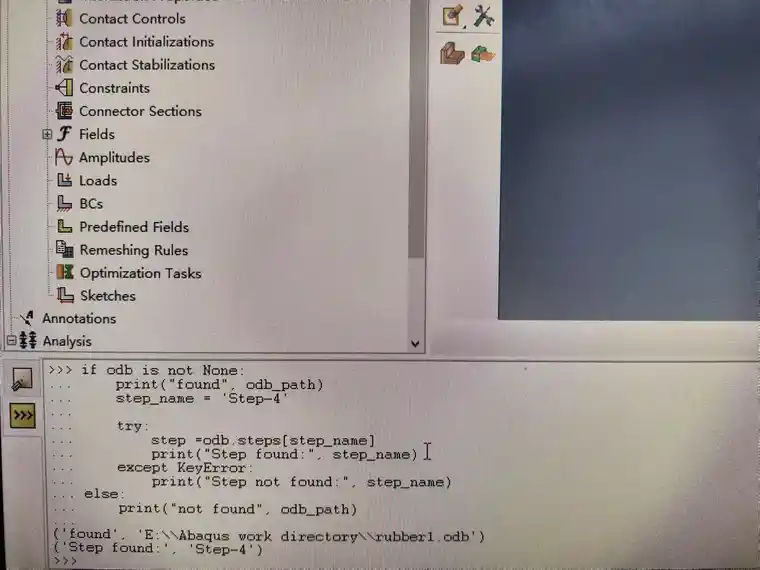
2.识别odb文件中关注的Step-4分析步否存在。
from odbAccess import openOdb
odb_path = r"E:\Abaqus work directory\rubber1.odb"
odb = openOdb(path=odb_path)
if odb is not None:
print("Found:", odb_path)
step_name = 'Step-4'
try:
step = odb.steps[step_name]
print("Step found:", step_name)
except KeyError:
print("Step not found:", step_name)
else:
print("Not found:", odb_path)
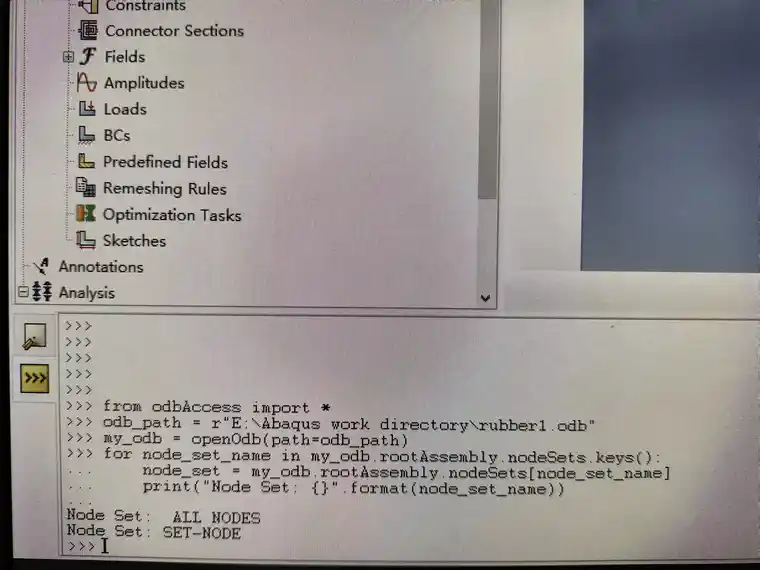
3.识别odb文件中关注的Set组分析步否存在。
from odbAccess import *
odb_path = r"E:\Abaqus work directory\rubber1.odb"
my_odb = openOdb(path=odb_path)
for node_set_name in my_odb.rootAssembly.nodeSets.keys():
node_set = my_odb.rootAssembly.nodeSets[node_set_name]
print("Node Set: {}".format(node_set_name))
代码中odb路径、输出文件名称、set组名称,根据实际情况自行修改。
代码为附件:1 Python脚本-odb文件变形量提取
提取节点变形量到此全部完成,提取的数据将以CSV格式保存在待处理的ODB文件放置目录下。如果需要提取变形后的节点坐标的话,我们还要继续进行。
方法一:提取初始节点坐标可以通过Abaqus后处理查询结果,在CSDN上可以查询到,此处不再赘述。
方法二:通过Python脚本,按节点编号提取初始节点坐标。
代码为附件:2 Python脚本-初始节点提取
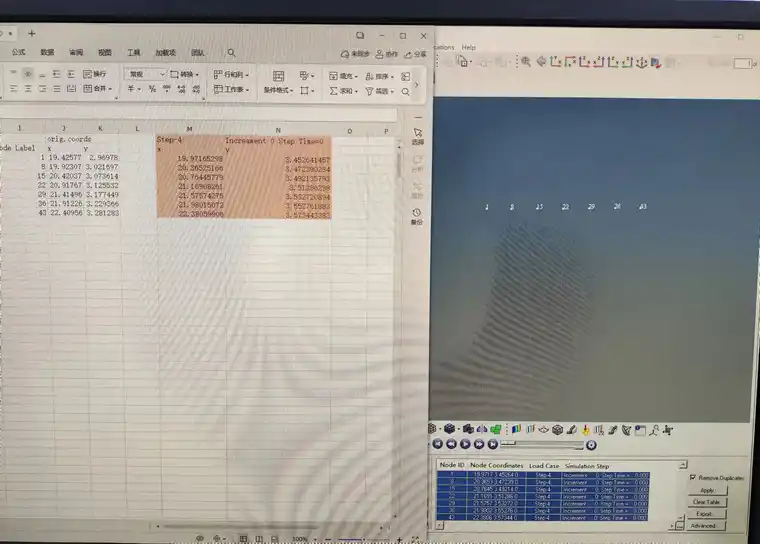
通过数据处理,将对应值求和即可求得变形后的节点坐标。以编号1号节点为例,节点初始坐标(X=19.42577,Y=2.96978),变形量(U1=0.54588,U2=0.48286),可求得编号1号节点变形后的坐标(X+U1,Y+U2),即为(19.97165,3.45264)。
验证坐标如下图所示,使用Hyperview后处理,可以看出提取节点坐标与Python脚本后处理的节点坐标一致。综上所述可以看出该脚本可满足需求。

免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















