















































软件

产品


基础知识
历史输出变量与场输出变量所在位置不同,如下图所示。其中历史变量位于steps下的historyRegions容器。
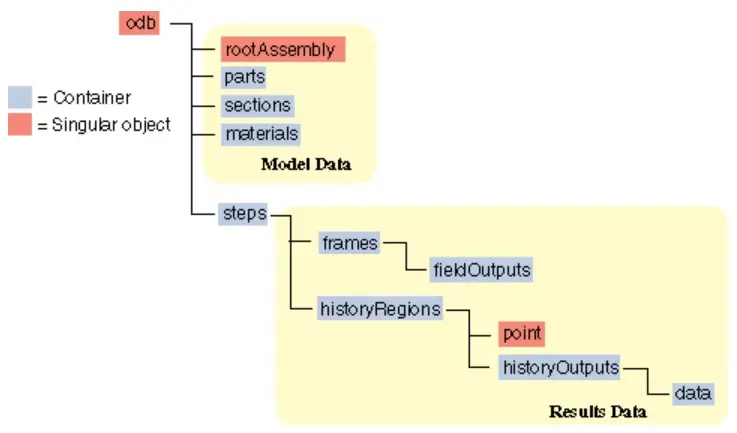
历史变量所在位置
基础案例
在计算模型中定义了一圈接地弹簧,如下图所示。
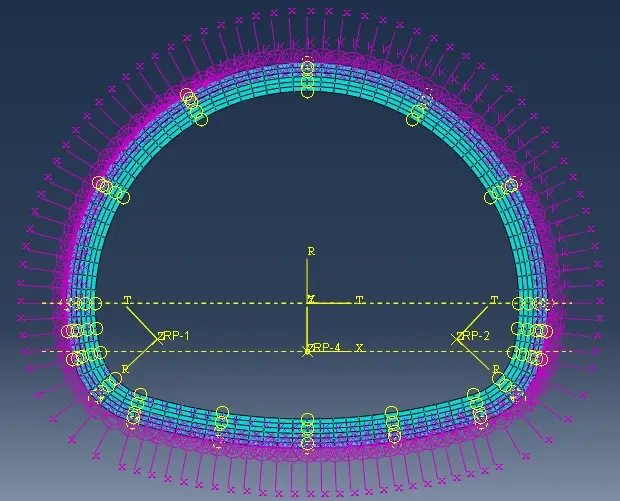
接地弹簧展示
为了得到弹簧的受力结果,在step模块的历史变量中添加申请,获取弹簧径向受力[S11]。(因为不是标准圆形隧道,所以定义弹簧时为了保证沿径向分布,需要定义局部坐标系,并且由于网格划分导致的单元大小不一致的原因,我这里定义了5种接地弹簧,所以有五个历史输出变量)
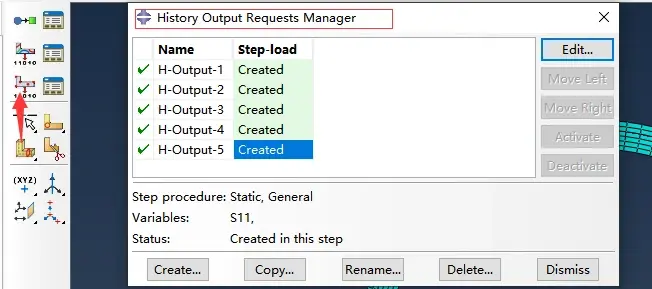
历史输出变量的输出请求
为了节约空间,只提取最终状态的弹簧受力,所以输出中的Frequency仅要求了在最后输出“Last increment”。
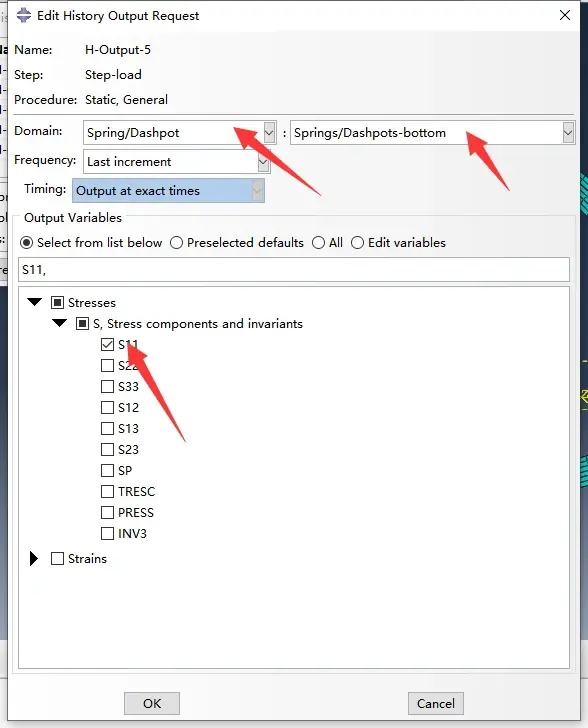
历史输出变量的详细设置
获取区域名称
历史输出变量里不容易处理的是获取所要提取的名称,因此,先要找到名称。
将以下代码复制到ABAQUS 命令行输出名称,记得将file_name改为你的odb文件名,将dir_path改为你的odb文件所在的文件夹。
from odbAccess import openOdb
from abaqusConstants import *
import os
# 指明odb文件所在位置并打开
file_name = '你的文件名'
dir_path = r'你的ODB文件所在的文件夹'
file_path = os.path.join(dir_path, file_name)
# 获取odb对象
my_odb = openOdb(file_path)
# 获取分析步
step = my_odb.steps['Step-load']
# 获取名称
print(step.historyRegions)输入完后按回车,就出现了浩浩汤汤的变量名

获取的变量名称
完整代码及结果
from odbAccess import openOdb
from abaqusConstants import *
import numpy as np
import os
# 指明odb文件所在位置并打开
file_name = '你的ODB文件名'
output_name = "弹簧受力结果.csv"
dir_path = r'ODB文件所在的文件夹'
file_path = os.path.join(dir_path, file_name)
output_path = os.path.join(dir_path, output_name)
# 获取odb对象
my_odb = openOdb(file_path)
# 获取分析步
step = my_odb.steps['Step-load']
# 定义空二维数组,用于存储结果数据,因为定义了93个弹簧,所以这里就搞了93行
data = np.zeros((93, 2), dtype='float32')
# 提取单元编号及轴力结果
for element_number in range(1, 94):
data_name = 'Element ASSEMBLY.{} Int Point 1'.format(element_number)
region = step.historyRegions[data_name]
S11 = region.historyOutputs['S11'].data[-1][1]
data[element_number-1, :] = [element_number, S11]
# 将结果保存到同目录下的csv文件
np.savetxt(output_path, data, delimiter=',')结果如下图,第一列为单元号,第二列为数值。
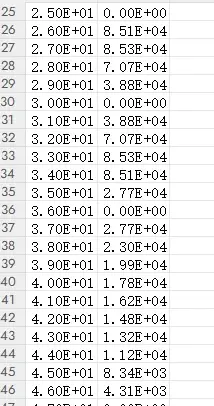
结果
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















