















































软件

产品


背景
在 python提取Abaqus后处理节点集合数据并生成文本文件 - 哔哩哔哩 (bilibili.com)中我们详细讲了如何运用python 脚本提取在CAE界面已经定义好了集合结果数据。
但是,存在这样一个问题,就是每次我们创建CAE模型时还得定义集合,多了这一步操作,而且,假如小伙伴们已经算了很多的ODB结果文件了,但是没有定义集合,那岂不是凉凉?
本次专栏旨在解决在CAE界面没有定义节点集合的问题。
即如果已知我知道想要提取的节点编号,可以在后处理中通过python代码定义相关集合并提取数据。这是非常实用的,比如你计算了非常多的工况,有很多ODB文件,而这些工况中仅仅只改变了荷载大小,但是网格、节点编号没有丝毫改变,那么我们就可以先在一个ODB文件中找到我们想要知道的节点编号,然后编写脚本,就可以提取所有的ODB文件的信息了。
案例
还是熟悉的二维平面问题,CAE文件同 python提取Abaqus后处理节点集合数据并生成文本文件 - 哔哩哔哩 (bilibili.com),我们要在后处理中提取节点编号为56、57、58、59的位移数据。
代码
以下是全部代码,大家注意用的时候将对应的路径及其他信息修改为自己的路径,哪里需要更改我已经在对应代码的后方进行了标注。
from odbAccess import openOdb
from textRepr import *
# 获取odb对象
my_odb = openOdb(r"D:\SIMULIA2020\script_learning\case3\ODBandOtherRealtingFiles\Job-1.odb") #改为你自己ODB文件所在地址
# 获取指定分析步
step = my_odb.steps['Step-1'] #改为你所要提取分析步
# 选取最后一帧
frame = step.frames[-1] #改为你所要提取的帧
# 获取全局位移场变量
dis_field = frame.fieldOutputs['U'] #改为你所想要提取的变量
# *****************************************************
# 指定想要获取的节点编号
node_Labels = (55,56,57,58) #改为你想提取的节点编号
# 在PART-1-1中定义名称为set_for_datas的集合,包含node_Labels节点编号,并将其赋予给变量node_set
node_set = my_odb.rootAssembly.instances['PART-1-1'].NodeSetFromNodeLabels(name='set_for_datas',nodeLabels=node_Labels)
# 在前述全局位移场变量的基础上提取局部位移场
local_dis_values = dis_field.getSubset(region=node_set)
# *****************************************************
# 生成txt文件,并将提取的结果写入
with open('data.txt','w') as f: #可修改路径为绝对路径
f.write("NodeLabel, NodeDis\n")
for node_value in local_dis_values.values:
txt_line = "{}, {}\n".format(node_value.nodeLabel, node_value.magnitude)
f.write(txt_line)使用方法
1.打开用Abaqus打开ODB文件;
2.复制上述代码,在命令行粘贴上述代码并回车,命令行位置如下图所示。
3. 回车运行。
4.运行完毕后在Abaqus工作目录下(或代码中指定的绝对路径下)即可看到新生成的data.txt文件,打开如下图所示。
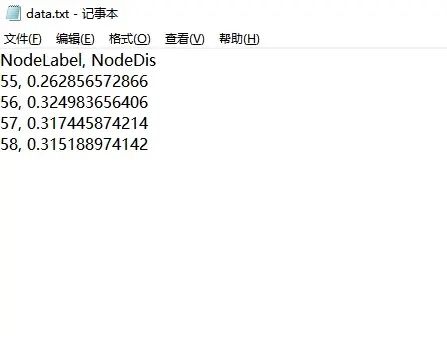
处理结果
大家觉得有用的话请投币吧
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















