















































软件

产品




进行完手掌检测后,在手定位范围内通过 hand landmark model回归出精确的21个 hand landmarks的2.5D坐标。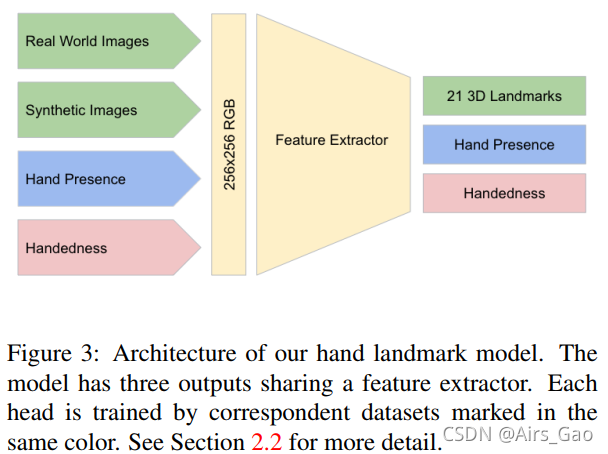
模型有3个输出:
(1)21个hand landmarks,包含x,y,和相对的depth。
(2)表示输入图像中手存在的概率的手标志(hand flag)。
(3)二值分类的handedness,如左手或右手。
本文用到3个数据集:

在不同数据集上的验证结果: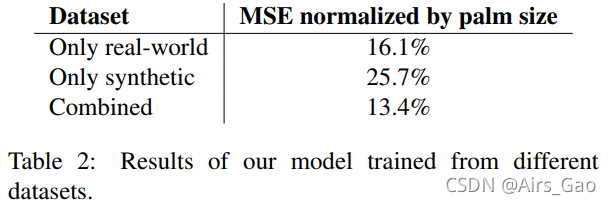
训练了3种模型,经过对比,Full model可以兼顾准确率和时间。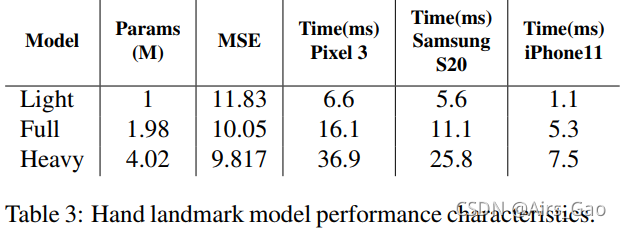

免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















