















































软件

产品


Tensorflow2.0——卷积神经网络
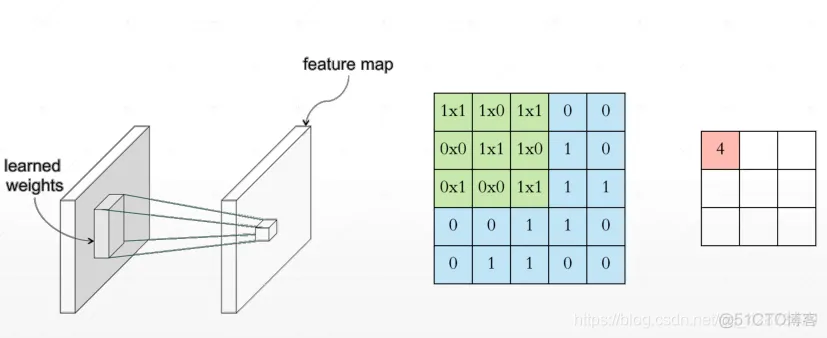
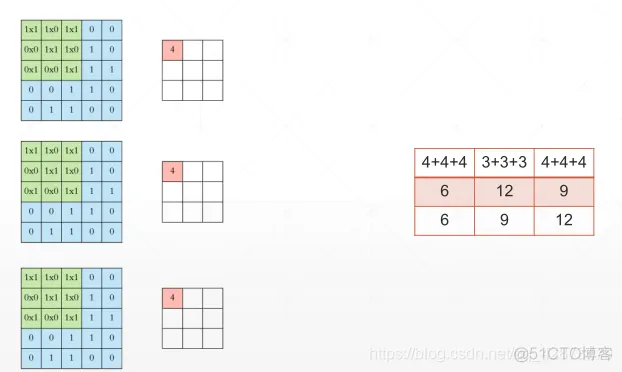
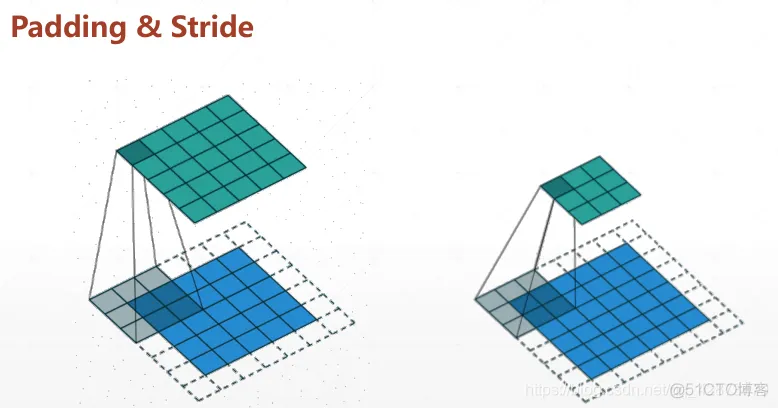
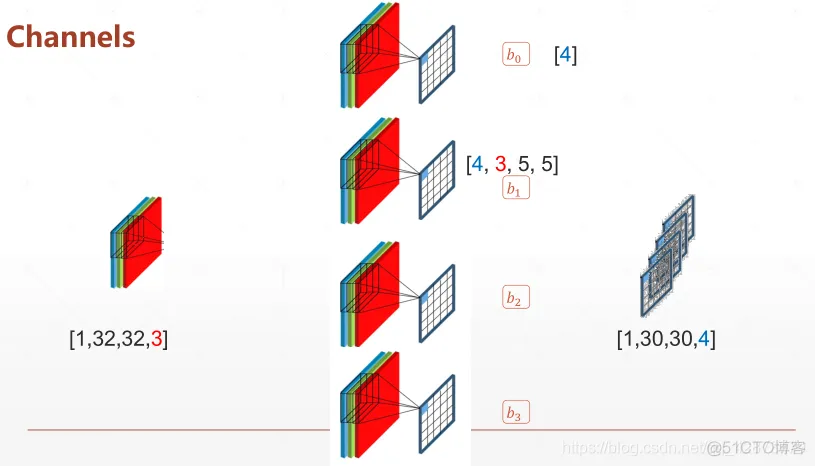

layers.Conv2D
weight&bias
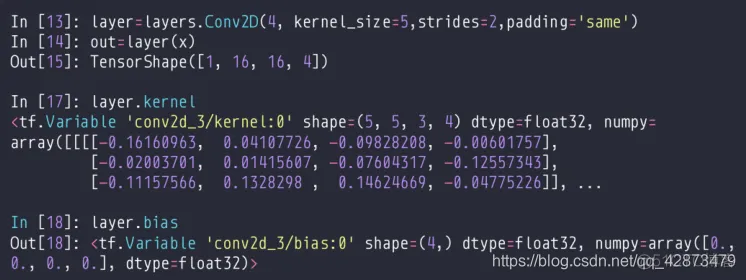
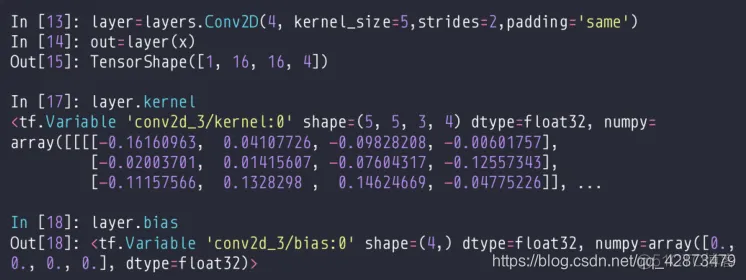
nn.conv2D
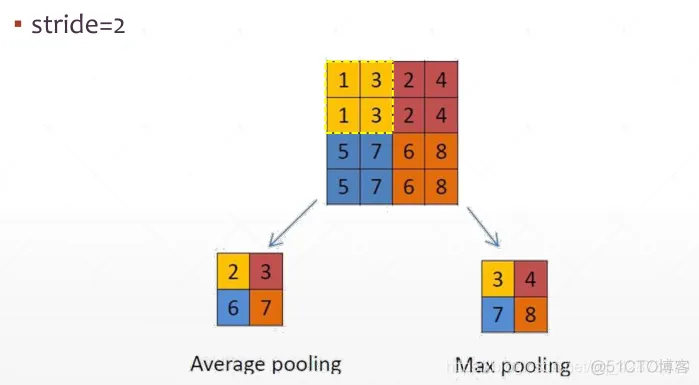
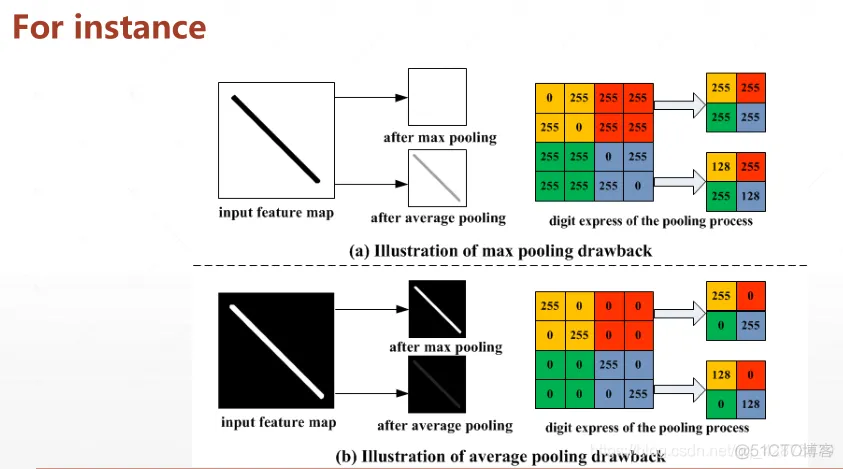
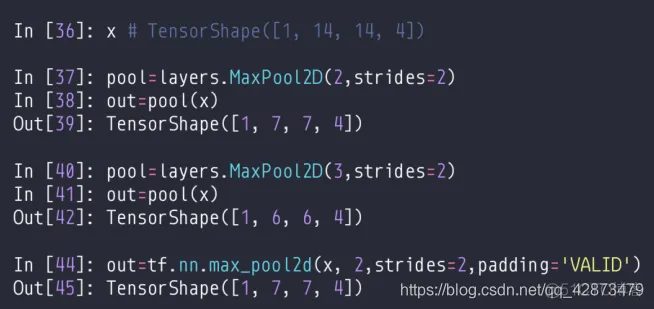
池化:Max/Avg pooling
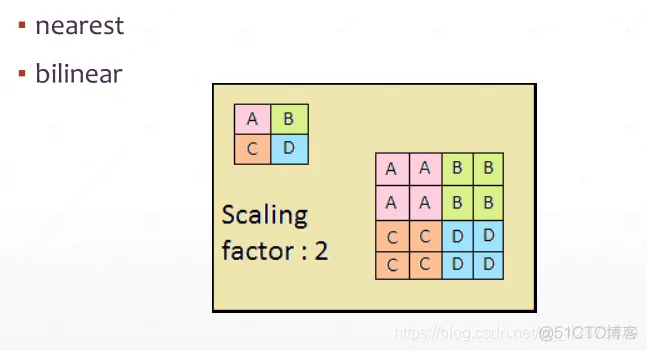
上采样:upsample
UpSampling2D:

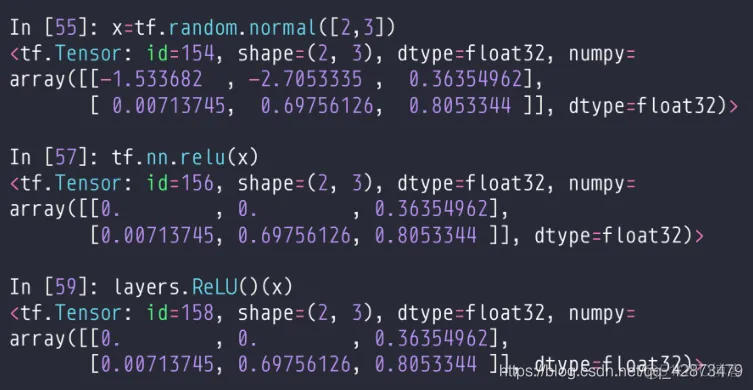
Relu:
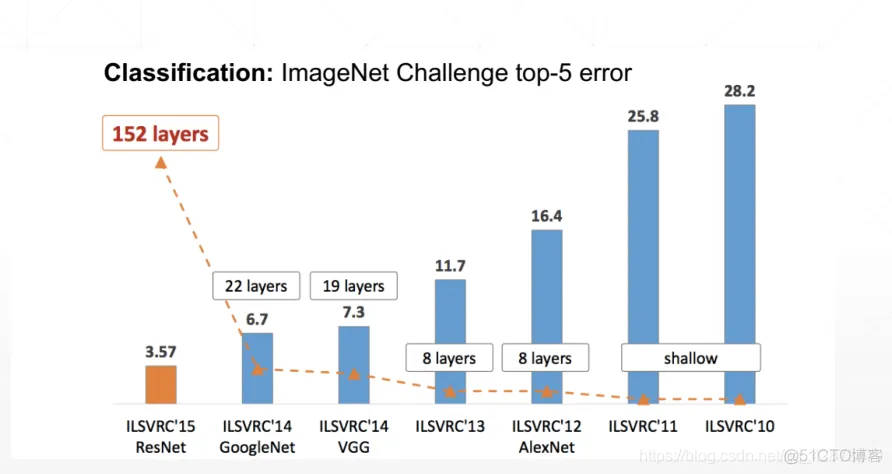
MNIST数据集上:99.2%acc ;
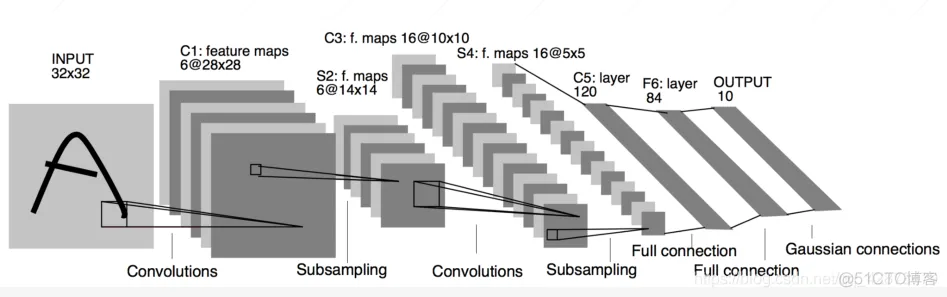
网络层:5/6layers:2卷积层+3全连接层
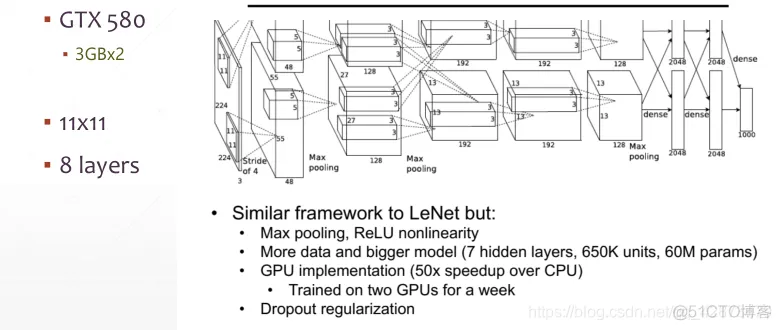
准确率提升10%+
网络层:5卷积层+3全连接层
VGG有不同的版本:VGG11、VGG16、VGG19
创新点:探索了一种更小型的卷积核(1x1、3x3),关注更小的视野,不会损害计算精度,也不会增大所需计算的参数量,效率较佳。
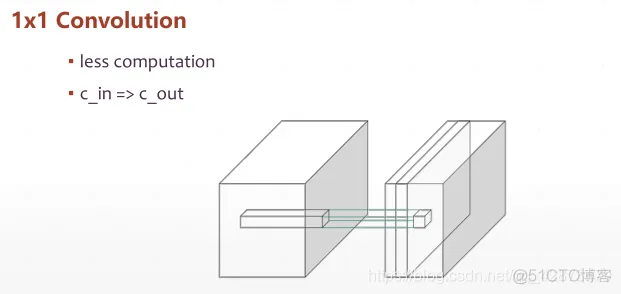
kernel卷积核的数量决定了输出的feature map的大小。

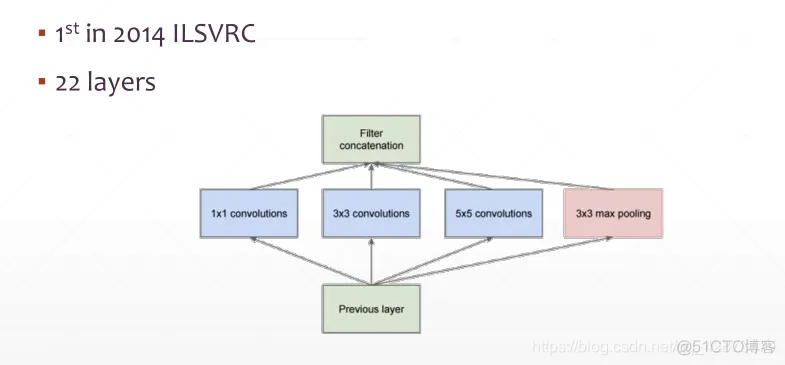
在同一个卷积层中使用不同的卷积核(1x1、3x3、5x5)。综合了不同视角的视野,观察更全面。
假如都使用32个卷积核,输入为[28x28],那么max pooling会输出[14x14]维度,那么另外三个卷积核的strides都应为2,才能对应输出[14x14]与池化层维度匹配,经过concatenation合并成为32*4 [14x14]个输出。
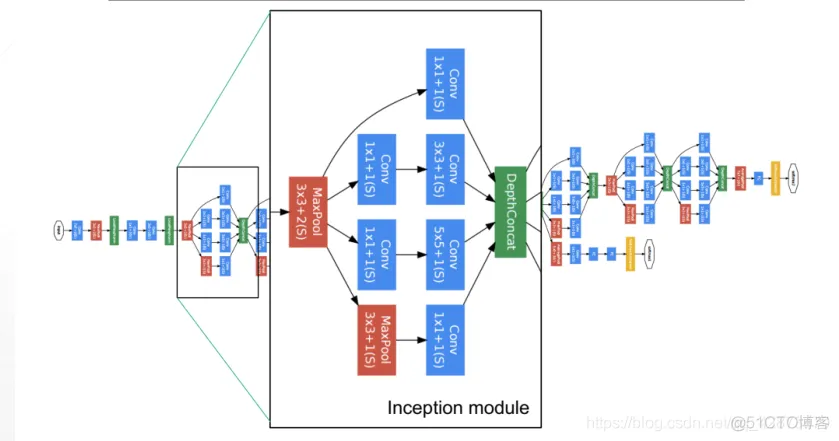
前面有16层,后面有6层,可以分开使用也可以全部使用,根据target计算loss去优化。
一个网络单元unit:卷积Conv+BatchNorm+池化pooling+激活Relu
ResNet是现在使用最广泛、意义最大的一种卷积神经网络。
深层次的神经网络一步步求导时会导致误差的堆叠,会更容易出现梯度离散和梯度爆炸现象,所以不能一味的堆叠网络层数。
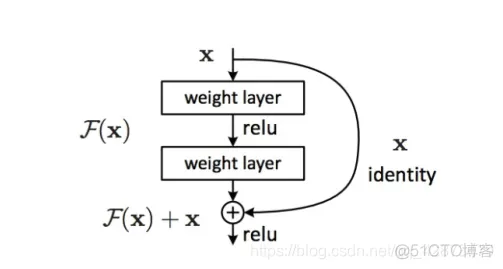
它对每层的输入做一个reference, 学习形成残差函数, 而不是学习一些没有reference的函数。这种残差函数更容易优化,能使网络层数大大加深。
在计算机视觉里,特征的“等级”随增网络深度的加深而变高,研究表明,网络的深度是实现好的效果的重要因素。然而梯度弥散/爆炸成为训练深层次的网络的障碍,导致无法收敛。
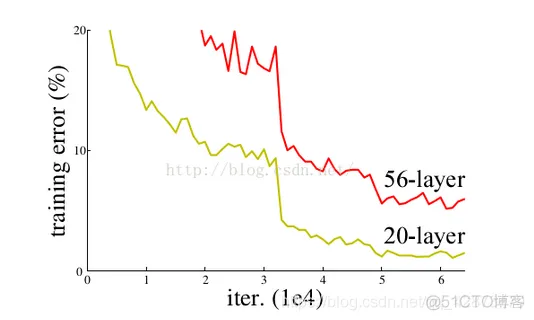
有一些方法可以弥补,如归一初始化,各层输入归一化,使得可以收敛的网络的深度提升为原来的十倍。然而,虽然收敛了,但网络却开始退化了,即增加网络层数却导致更大的误差, 如下图。 这种deep plain net收敛率十分低下。
通过在一个浅层网络基础上叠加y=x的层(称identity mappings,恒等映射),可以让网络随深度增加而不退化。这反映了多层非线性网络无法逼近恒等映射网络。
但是,不退化不是我们的目的,我们希望有更好性能的网络。resnet学习的是残差函数F(x) = H(x) - x, 这里如果F(x) = 0, 那么就是上面提到的恒等映射。事实上,resnet是“shortcut connections”的在connections是在恒等映射下的特殊情况,它没有引入额外的参数和计算复杂度。 假如优化目标函数是逼近一个恒等映射, 而不是0映射, 那么学习找到对恒等映射的扰动会比重新学习一个映射函数要容易。从下图可以看出,残差函数一般会有较小的响应波动,表明恒等映射是一个合理的预处理。
残差学习的基本单元:
ResNet:
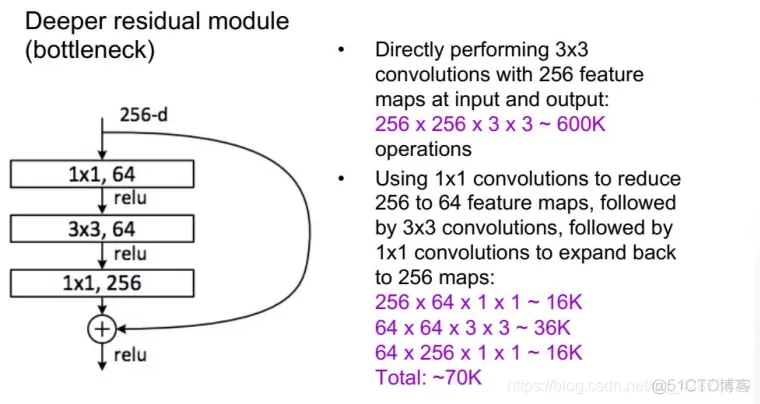

实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1。新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。

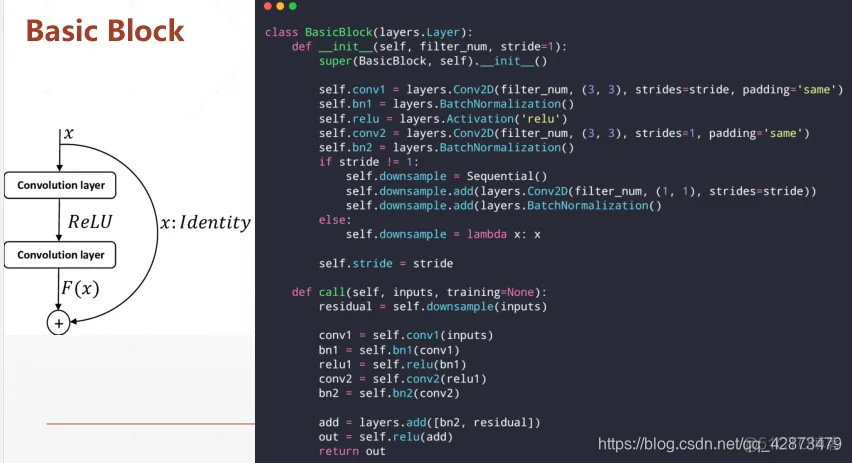
一个Basic Block包括两个卷积层和一个短接线,在梯度离散时可以退化到短接线直接传递。
两个单元称为一个Res Block:

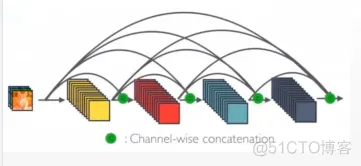
DenseNet:
准确率比较:
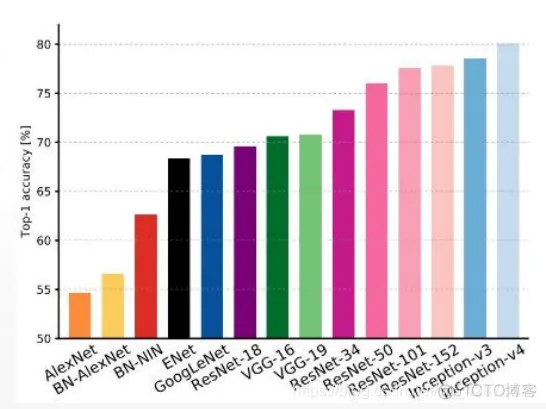
计算量和准确率比较:
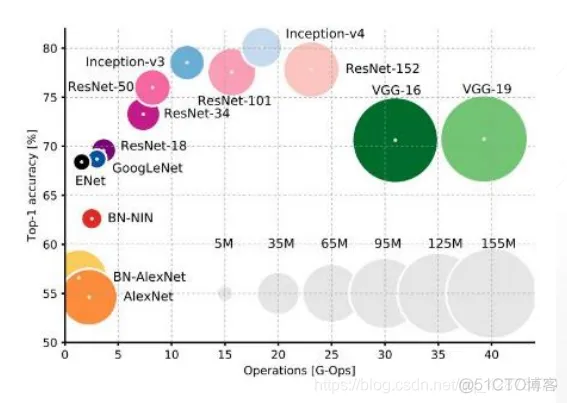
可以看出。Inception和ResNet都表现较好,计算量较小准确率高,注意VGG计算量比较大,因为运用的卷积核相对比较大。
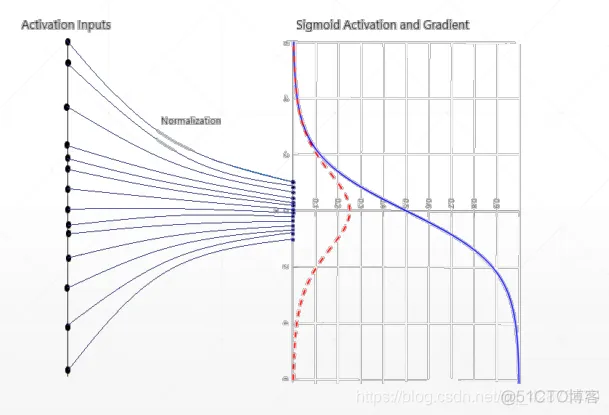
Sigmoid函数在深度网络中常常会导致导数逐渐变为0,使得参数无法被更新,神经网络无法被优化。下图可以看出,当输出过大或过小时,sigmoid的梯度接近于0,出现梯度离散现象。
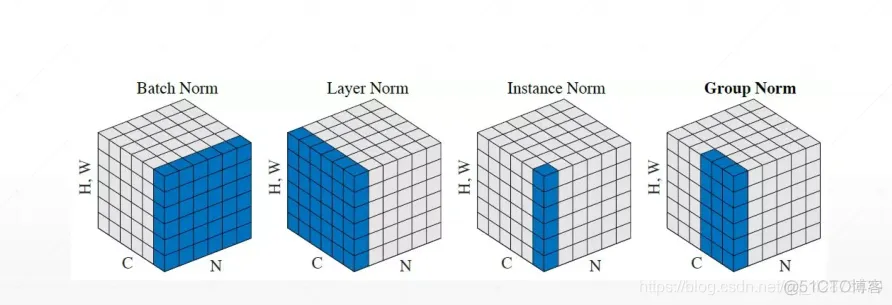
Feature Scaling:

Batch Norm

Pipeline:

优点:收敛速度快、表现更好能够搜索到更优的解、稳定性好、对于超参数没有那么敏感,可以使用更大的学习速率。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















