















































软件

产品


在网上查如何进行神经风格迁移的时候,发现大多数人都是使用迁移学习来的网络。当然,迁移学习导入已经训练好的网络进行训练是非常方便且快速的,但是有时候我们可能会想自己训练一个网络进行神经风格迁移。所以在这篇文章中,我们尝试使用自定义的 GoogLeNet 网络模型进行神经风格迁移。
PS:对神经风格迁移的原理感兴趣的可以参考:Tensorflow2.0之神经风格迁移。
下面直接贴上代码并对其中不好理解的地方做出解释:
import tensorflow as tf
import IPython.display as display
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12,12)
mpl.rcParams['axes.grid'] = False
content_path = tf.keras.utils.get_file('turtle.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Green_Sea_Turtle_grazing_seagrass.jpg')
style_path = tf.keras.utils.get_file('kandinsky.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
上面代码得到的是两张图片的存储路径。
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape*scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
content_image = load_img(content_path)
style_image = load_img(style_path)
上述代码中:
img = tf.io.read_file(path_to_img) 将图片加载到程序中,但此时得到的img是经编码后的,我们并不能明白它代表什么。
img = tf.image.decode_image(img, channels=3) 将加载的图片解码成像素值数组。
img = tf.image.convert_image_dtype(img, tf.float32) 将所有图片像素同除255,并将该数组数据设置为浮点型。
其余部分的目的是将图片的长宽等比例缩放成使其最长边等于512。
对 GoogLeNet 模型的定义有兴趣的朋友可以参考:Tensorflow2.0之三种方法自定义GoogLeNet。
class Inception(tf.keras.Model):
def __init__(self, c1, c2, c3, c4):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(c1, kernel_size=1,
activation='relu', padding='same')
self.conv2_1 = tf.keras.layers.Conv2D(c2[0], kernel_size=1,
activation='relu', padding='same')
self.conv2_2 = tf.keras.layers.Conv2D(c2[1], kernel_size=3,
activation='relu', padding='same')
self.conv3_1 = tf.keras.layers.Conv2D(c3[0], kernel_size=1,
activation='relu', padding='same')
self.conv3_2 = tf.keras.layers.Conv2D(c3[1], kernel_size=5,
activation='relu', padding='same')
self.conv4_1 = tf.keras.layers.MaxPool2D(pool_size=3, strides=1,
padding='same')
self.conv4_2 = tf.keras.layers.Conv2D(c4, kernel_size=1,
activation='relu', padding='same')
def call(self, inputs):
x1 = self.conv1(inputs)
x2 = self.conv2_2(self.conv2_1(inputs))
x3 = self.conv3_2(self.conv3_1(inputs))
x4 = self.conv4_2(self.conv4_1(inputs))
return tf.concat((x1, x2, x3, x4), axis=-1)
在这里一定要用函数的方法定义 GoogLeNet 模型!!!否则会报错:
AttributeError: Layer inception_2 has no inbound nodes.
def GoogLeNet():
inputs = tf.keras.layers.Input(shape=(None, None, 3))
model = [
tf.keras.layers.Conv2D(filters=64, kernel_size=7, strides=2,
activation='relu', padding='same'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same'),
tf.keras.layers.Conv2D(filters=64, kernel_size=1,
activation='relu', padding='same'),
tf.keras.layers.Conv2D(filters=192, kernel_size=3,
activation='relu', padding='same'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same'),
Inception(64, (96, 128), (16, 32), 32),
Inception(128, (128, 192), (32, 96), 64),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same'),
Inception(192, (96, 208), (16, 48), 64),
Inception(160, (112, 224), (24, 64), 64),
Inception(128, (128, 256), (24, 64), 64),
Inception(112, (144, 288), (32, 64), 64),
Inception(256, (160, 320), (32, 128), 128),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same'),
Inception(256, (160, 320), (32, 128), 128),
Inception(384, (192, 384), (48, 128), 128),
tf.keras.layers.GlobalAvgPool2D()
]
x = inputs
for layer in model:
x = layer(x)
outputs = tf.keras.layers.Dense(10)(x)
return tf.keras.Model(inputs=inputs, outputs=outputs)
google = GoogLeNet()
for layer in google.layers:
print(layer.name)
input_1
conv2d
max_pooling2d
conv2d_1
conv2d_2
max_pooling2d_1
inception
inception_1
max_pooling2d_4
inception_2
inception_3
inception_4
inception_5
inception_6
max_pooling2d_10
inception_7
inception_8
global_average_pooling2d
dense
风格层的输出旨在代表风格图片的特征,内容层的输出旨在表示内容图片的特征。
content_layers = ['global_average_pooling2d', 'inception_8']
style_layers = ['inception_2',
'inception_3',
'inception_4',
'inception_5',
'inception_6',
'inception_7',
'inception_8']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
在这之后要先对这个 GoogLeNet 模型进行训练,在这里就不再展示了。(因为我没找到一个小的训练集……)
因为原始的 GoogLeNet 模型输出分类结果(概率),但在风格迁移时我们需要的是两张图片各自的特征,即不同层的输出,所以要重新对 GoogLeNet 的输出进行定义。
def google_layers(layer_names):
outputs = [google.get_layer(name).output for name in layer_names]
model = tf.keras.Model([google.input], outputs)
return model
此处详解参考Tensorflow2.0如何在网络中规定多个输出。
图像的风格可以通过不同风格层的输出的平均值和相关性来描述。 通过在每个位置计算这些输出向量的外积,并在所有位置对该外积进行平均,可以计算出包含此信息的 Gram 矩阵。 对于特定层的 Gram 矩阵,具体计算方法如下所示:
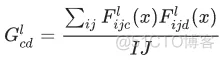
上式中的可以这样解释:
我们知道,输入神经网络的一张图片的形状应该类似这种形式:[1, 256, 128, 3]。那么表示第几张图片,这里为1;表示256; 表示128;和都等于3(因为是同一张图片,所以)。
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
其中,tf.linalg.einsum(‘bijc,bijd->bcd’, input_tensor, input_tensor) 旨在计算Gram矩阵。
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.google = google_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.google.trainable = True
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
outputs = self.google(inputs)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name:value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name:value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content':content_dict, 'style':style_dict}
extractor = StyleContentModel(style_layers, content_layers)
实例化此模型时,其输入为风格层和内容层。将图片输入此模型后,得到一个字典,包含 ‘content’ 和 ‘style’ ,分别表示风格层的输出(五层输出)和内容层的输出(一层输出)。
将风格图片和内容图片分别输入模型,分别取其风格特征和内容特征。
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
因为输入的内容图片不断地改变其风格直到接近风格图片的风格,所以定义一个 tf.Variable 来表示要优化的图像。
image = tf.Variable(content_image)
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
style_weight = 1e-2
content_weight = 1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
# 计算风格损失
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
# 计算内容损失
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
# 计算总损失
loss = style_loss + content_loss
return loss
style_weight 和content_weight 分别表示风格上的损失和内容上的损失在计算总损失时所占的比重。
首先,由于这是一个浮点图像,因此我们需要定义一个函数来保持像素值保持在 0 和 1 之间:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
然后,通过梯度带来进行参数优化。
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
有关梯度带的详细信息可以参考:Tensorflow2.0中的梯度带(GradientTape)以及梯度更新。
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='')
display.clear_output(wait=True)
imshow(image.read_value())
plt.title("Train step: {}".format(step))
plt.show()
迭代1000次之后,得到图片:

免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















