















































软件

产品


docker run -p 8501:8501 --name="half_plus_two" --mount type=bind,
source=/tmp/tfserving/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_cpu,
target=/models/half_plus_two -e MODEL_NAME=half_plus_two -t tensorflow/serving "&"
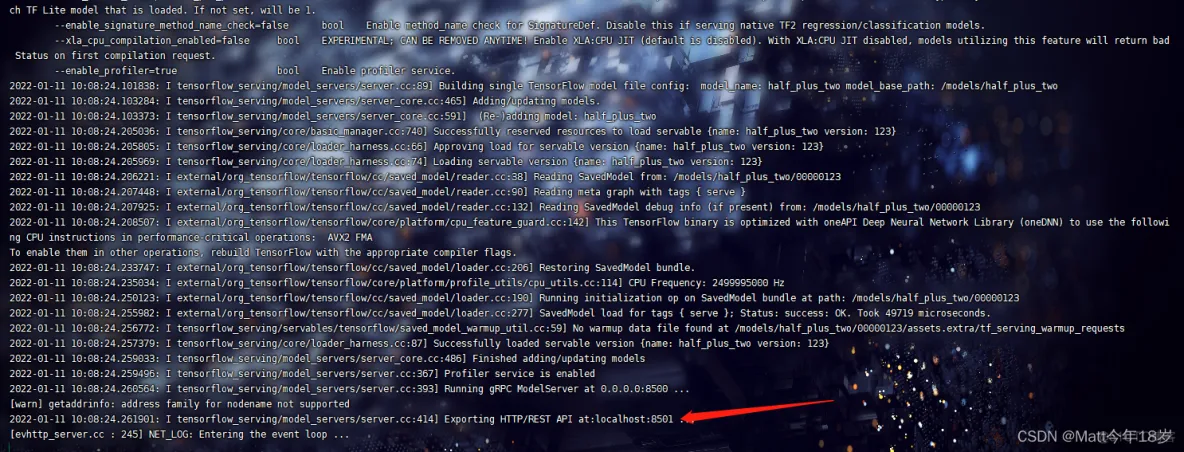
本文用的是阿里云服务器,客户机访问时无法用localhost:8501访问,需要公网ip:8501访问。
直接访问公网ip:8501结果如下:

curl上传数据访问服务:
curl -d '{"instances": [1.0, 2.0, 5.0]}' http://121.41.94.49:8501/v1/models/half_plus_two:predict

目前先找了个特征提取的网络模型跑一下试试。
文件夹目录为/media/tf_serving/r50_fp16pb,里面有个文件夹1, 1里面是3个东西,存放的就是tf保存的文件

asset是空的,variables内部为

模型文件配置好了以后,运行docker:
docker run -p 8501:8501 --name="resnet01" --mount type=bind,
source=/media/tf_serving/r50_fp16pb,target=/models/resnet -e MODEL_NAME=resnet -t tensorflow/serving "&"
source就是自己的文件夹,target为容器内部存储位置,注意后面的MODEL_NAME需要跟前面target最后的存储位置文件夹位置相同才可以,否则会报错找不到该MODEL_NAME的位置。
运行结果如下:
usage: tensorflow_model_server
Flags:
--port=8500 int32 TCP port to listen on for gRPC/HTTP API. Disabled if port set to zero.
--grpc_socket_path="" string If non-empty, listen to a UNIX socket for gRPC API on the given path. Can be either relative or absolute path.
--rest_api_port=0 int32 Port to listen on for HTTP/REST API. If set to zero HTTP/REST API will not be exported. This port must be different than the one specified in --port.
--rest_api_num_threads=4 int32 Number of threads for HTTP/REST API processing. If not set, will be auto set based on number of CPUs.
--rest_api_timeout_in_ms=30000 int32 Timeout for HTTP/REST API calls.
--rest_api_enable_cors_support=false bool Enable CORS headers in response
--enable_batching=false bool enable batching
--allow_version_labels_for_unavailable_models=false bool If true, allows assigning unused version labels to models that are not available yet.
--batching_parameters_file="" string If non-empty, read an ascii BatchingParameters protobuf from the supplied file name and use the contained values instead of the defaults.
--model_config_file="" string If non-empty, read an ascii ModelServerConfig protobuf from the supplied file name, and serve the models in that file. This config file can be used to specify multiple models to serve and other advanced parameters including non-default version policy. (If used, --model_name, --model_base_path are ignored.)
--model_config_file_poll_wait_seconds=0 int32 Interval in seconds between each poll of the filesystemfor model_config_file. If unset or set to zero, poll will be done exactly once and not periodically. Setting this to negative is reserved for testing purposes only.
--model_name="default" string name of model (ignored if --model_config_file flag is set)
--model_base_path="" string path to export (ignored if --model_config_file flag is set, otherwise required)
--num_load_threads=0 int32 The number of threads in the thread-pool used to load servables. If set as 0, we don't use a thread-pool, and servable loads are performed serially in the manager's main work loop, may casue the Serving request to be delayed. Default: 0
--num_unload_threads=0 int32 The number of threads in the thread-pool used to unload servables. If set as 0, we don't use a thread-pool, and servable loads are performed serially in the manager's main work loop, may casue the Serving request to be delayed. Default: 0
--max_num_load_retries=5 int32 maximum number of times it retries loading a model after the first failure, before giving up. If set to 0, a load is attempted only once. Default: 5
--load_retry_interval_micros=60000000 int64 The interval, in microseconds, between each servable load retry. If set negative, it doesn't wait. Default: 1 minute
--file_system_poll_wait_seconds=1 int32 Interval in seconds between each poll of the filesystem for new model version. If set to zero poll will be exactly done once and not periodically. Setting this to negative value will disable polling entirely causing ModelServer to indefinitely wait for a new model at startup. Negative values are reserved for testing purposes only.
--flush_filesystem_caches=true bool If true (the default), filesystem caches will be flushed after the initial load of all servables, and after each subsequent individual servable reload (if the number of load threads is 1). This reduces memory consumption of the model server, at the potential cost of cache misses if model files are accessed after servables are loaded.
--tensorflow_session_parallelism=0 int64 Number of threads to use for running a Tensorflow session. Auto-configured by default.Note that this option is ignored if --platform_config_file is non-empty.
--tensorflow_intra_op_parallelism=0 int64 Number of threads to use to parallelize the executionof an individual op. Auto-configured by default.Note that this option is ignored if --platform_config_file is non-empty.
--tensorflow_inter_op_parallelism=0 int64 Controls the number of operators that can be executed simultaneously. Auto-configured by default.Note that this option is ignored if --platform_config_file is non-empty.
--ssl_config_file="" string If non-empty, read an ascii SSLConfig protobuf from the supplied file name and set up a secure gRPC channel
--platform_config_file="" string If non-empty, read an ascii PlatformConfigMap protobuf from the supplied file name, and use that platform config instead of the Tensorflow platform. (If used, --enable_batching is ignored.)
--per_process_gpu_memory_fraction=0.000000 float Fraction that each process occupies of the GPU memory space the value is between 0.0 and 1.0 (with 0.0 as the default) If 1.0, the server will allocate all the memory when the server starts, If 0.0, Tensorflow will automatically select a value.
--saved_model_tags="serve" string Comma-separated set of tags corresponding to the meta graph def to load from SavedModel.
--grpc_channel_arguments="" string A comma separated list of arguments to be passed to the grpc server. (e.g. grpc.max_connection_age_ms=2000)
--grpc_max_threads=4 int32 Max grpc server threads to handle grpc messages.
--enable_model_warmup=true bool Enables model warmup, which triggers lazy initializations (such as TF optimizations) at load time, to reduce first request latency.
--version=false bool Display version
--monitoring_config_file="" string If non-empty, read an ascii MonitoringConfig protobuf from the supplied file name
--remove_unused_fields_from_bundle_metagraph=true bool Removes unused fields from MetaGraphDef proto message to save memory.
--prefer_tflite_model=false bool EXPERIMENTAL; CAN BE REMOVED ANYTIME! Prefer TensorFlow Lite model from `model.tflite` file in SavedModel directory, instead of the TensorFlow model from `saved_model.pb` file. If no TensorFlow Lite model found, fallback to TensorFlow model.
--num_tflite_pools=1 int32 EXPERIMENTAL; CAN BE REMOVED ANYTIME! Number of TFLite interpreters in an interpreter pool of TfLiteSession. Typically there is one TfLiteSession for each TF Lite model that is loaded. If not set, will be auto set based on number of CPUs.
--num_tflite_interpreters_per_pool=1 int32 EXPERIMENTAL; CAN BE REMOVED ANYTIME! Number of TFLite interpreters in an interpreter pool of TfLiteSession. Typically there is one TfLiteSession for each TF Lite model that is loaded. If not set, will be 1.
--enable_signature_method_name_check=false bool Enable method_name check for SignatureDef. Disable this if serving native TF2 regression/classification models.
--xla_cpu_compilation_enabled=false bool EXPERIMENTAL; CAN BE REMOVED ANYTIME! Enable XLA:CPU JIT (default is disabled). With XLA:CPU JIT disabled, models utilizing this feature will return bad Status on first compilation request.
--enable_profiler=true bool Enable profiler service.
2022-01-14 07:21:08.305998: I tensorflow_serving/model_servers/server.cc:89] Building single TensorFlow model file config: model_name: resnet model_base_path: /models/resnet
2022-01-14 07:21:08.306230: I tensorflow_serving/model_servers/server_core.cc:465] Adding/updating models.
2022-01-14 07:21:08.306250: I tensorflow_serving/model_servers/server_core.cc:591] (Re-)adding model: resnet
2022-01-14 07:21:08.410121: I tensorflow_serving/core/basic_manager.cc:740] Successfully reserved resources to load servable {name: resnet version: 1}
2022-01-14 07:21:08.410171: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: resnet version: 1}
2022-01-14 07:21:08.410186: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: resnet version: 1}
2022-01-14 07:21:08.411260: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /models/resnet/1
2022-01-14 07:21:08.935499: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2022-01-14 07:21:08.935560: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /models/resnet/1
2022-01-14 07:21:08.936768: I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-01-14 07:21:09.054331: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-01-14 07:21:09.073055: I external/org_tensorflow/tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 2499995000 Hz
2022-01-14 07:21:09.159416: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/resnet/1
2022-01-14 07:21:09.211160: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 799895 microseconds.
2022-01-14 07:21:09.217029: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/resnet/1/assets.extra/tf_serving_warmup_requests
2022-01-14 07:21:09.219704: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: resnet version: 1}
2022-01-14 07:21:09.221243: I tensorflow_serving/model_servers/server_core.cc:486] Finished adding/updating models
2022-01-14 07:21:09.221674: I tensorflow_serving/model_servers/server.cc:367] Profiler service is enabled
2022-01-14 07:21:09.235265: I tensorflow_serving/model_servers/server.cc:393] Running gRPC ModelServer at 0.0.0.0:8500 ...
[warn] getaddrinfo: address family for nodename not supported
2022-01-14 07:21:09.237491: I tensorflow_serving/model_servers/server.cc:414] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
首先是照例啥也不写直接访问ip+端口号:
然后自己找了个差不多的tf_serving_test.py文件
import requests
from time import time
import json
import numpy as np
import cv2 as cv
def preprocess(image):
'''
模型输入前期处理
'''
def postprocess(boxes,scores,labels):
'''
模型输出后期处理
'''
def main():
url = 'http://公网ip:8501/v1/models/resnet:predict' #配置IP和port
img1_path = "6.jpg"
image1 = cv.imread(img1_path)
image1 = cv.resize(image1, (112, 112))
image1 = image1.transpose(2,0,1)
image1 = image1.tolist()
img2_path = "26.jpg"
image2 = cv.imread(img2_path)
image2 = cv.resize(image2, (112, 112))
image2 = image2.transpose(2, 0, 1)
image2 = image2.tolist()
image = []
image.append(image1)
# image.append(image2)
nimage = np.array(image)
print(nimage.shape)
# preprocess(image)
a1 = time()
predict_request = {"instances": image} #准备需要发送的数据,"inputs"与与.pb模型设置的输入节点一致
r = requests.post(url, json=predict_request) #发送请求
a2 = time()
print('响应时间{}'.format(a2 - a1))
prediction = json.loads(r.content.decode("utf-8")) #获取响应结果
print(prediction)
value_list = list(prediction.values())
value = np.array(value_list)
print(value.shape)
# boxes = np.array(prediction.get("loc_box"))
# scores = np.array(prediction.get('fire_pre'))
# labels = np.array(prediction.get("fire_class"))
# postprocess(boxes,scores,labels)
if __name__ == '__main__':
main()
模型属于是特征提取模型,输入为图片,格式为none*3*112*112, 搞好了以后进行测试:

服务访问成功!接下来就是部署多模型
文件配置结合上面链接以及单模型部署情况就可以搞定,启动docker:
docker run -p 8501:8501 --name="model04" --mount type=bind,
source=/media/tf_serving/Multimodel/,target=/models/Multimodel -t tensorflow/serving
--model_config_file=/models/Multimodel/model.config
这里要注意最后的--model_config_file的位置不要写错,路径为容器内路径。
访问与单模型也差不多,修改一下url地址即可


免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















