















































软件

产品


官网或者找别的博客参考,安装好后软件应该会有一个新手指引。否则会让你安装WSL2什么的。
检查是否安装好:

键入命令后出现类似界面,说明成功了。
docker pull tensorflow/serving
这个会有下载进度条,下载完了也就成功了。
由于我每次训练的结果都是保存为.h5的权重文件,所以还需要进行转换,如果你本身就是通过tf.saved_model.save()进行保存的,那就不用转换。
转换代码(不通用,需要载入自己的模型)
import tensorflow as tf
from resnet50 import RESNET50
if __name__ == '__main__':
classes_name = ['cat',"dog"]
model = RESNET50(num_classes=len(classes_name))
model.load_weights('logs/EP039_loss0.019-valoss0.295.h5')
tf.saved_model.save(model, "test/1")
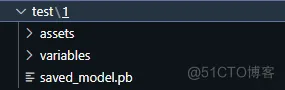
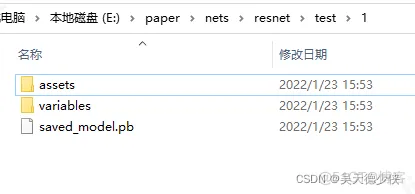
转换后生成的文件:1文件夹里面有2个文件夹和1个pd文件:
docker run -p 8501:8501 --mount type=bind,source=E:\paper\nets\resnet\test/,
target=/models/resnet -e MODEL_NAME=resnet -t tensorflow/serving
文件夹
这种,那么它就会每次启动时会自动去用最新的模型。
启动之后的情况

官方给的命令是这样的:

但是实际生成中肯定是通过代码进行的,而且谁会取部署一个线性回归的模型啊。所以需要写这个命令对应的其他脚本,c/c++、java、python都是可以的,只是python处理图片比较简单,我就以python为例了,其他大佬有c/c++方面的重写,记得call我哈哈哈(c/c++应该要装opencv,也不知道难不难装):
import cv2
import numpy as np
import requests
import json
import time
classes_name = ['cat',"dog"]
input_shape = (224,224)
filename = "datasets/test/dog/dog.10009.jpg"
inputs = cv2.imread(filename)
""" 数据预处理 """
inputs = cv2.resize(inputs,input_shape).astype(np.float32)
inputs0 = np.array(inputs, dtype="float") / 255.0
inputs = np.expand_dims(inputs0,axis=0)
start = time.time()
""" REST API端口 """
url = 'http://localhost:8501/v1/models/resnet:predict'
data = json.dumps({'inputs':inputs.tolist()}) # 要求输入的数据是json格式
# print(data)
response = requests.post(url,data=data)
result = json.loads(response.content)
outputs = result['outputs'][0]
result_index = np.argmax(outputs)
print(f'预测结果是:{classes_name[result_index]}')
print(f'花费时间:{time.time()-start:.2f}s')
我本来以为字典里面的
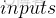
和
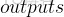
是有讲究的,跟自己在构建模型时有关,跟那个时候的命名一致,没想到竟然直接是
.png)
和
.png)
,那更省事了。
输出:

免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















