















































软件

产品


生成随机数据根据一列数据或从选定的数据分布创建一个或多个随机数据列。在 Minitab 中,选择计算 > 随机数据。
指定随机数字生成器为随机数生成器指定一个起点,以便将来生成相同的随机数据集。在 Minitab 中,选择计算 > 设置基数。创建分布的 PDF、CDF 或逆 CDF。计算所选分布的 PDF、CDF 或逆 CDF。在 Minitab 中,选择计算 > 概率分布。
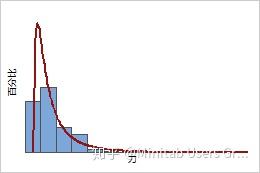
一组数据可按许多不同方式分布或散布。例如,掷骰子所得的数据可以是从 1 到 6 的随机整数值。制造过程所得的数据可以目标值为中心进行分布,也可以包括远离中心值的数据值。
可以通过图形、描述性统计量或者与理论分布的比较来评估数据分布:图形通过图形(如直方图),可以直接深入了解数据集的分布情况。直方图可以帮助您观测:
描述性统计量用于描述包含数字值的数据的中心趋势(平均值、中位数)和展开(方差、标准差)的描述性统计,这些统计添加了明细层并且可用于与其他数据集进行比较。理论分布最后,一些常见分布可通过正态分布、Weibull 分布和指数分布等进行标识和称呼。例如,正态分布始终为钟形,且沿均值对称分布。真实数据将只能接近于这些完全分布。如果存在紧密拟合,则可认为数据由给定分布进行了合理建模。可使用统计 > 质量工具 > 个体分布标识来确定最适合您数据的分布。
概率分布要么是连续概率分布,要么是离散概率分布,这取决于它们是定义连续变量还是离散变量的概率。
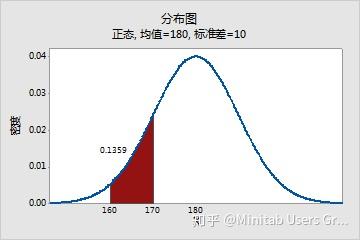
但是,X 精确等于某个值的概率始终为零,因为曲线下单个点的面积为零(没有宽度)。例如,男子体重恰好为 190 磅(至无限精确)的概率为零。您可以计算男性体重超过 190 磅或小于 190 磅的概率,或者介于 189.9 到 190.1 磅之间的概率,但恰好等于 190 磅的概率为零。
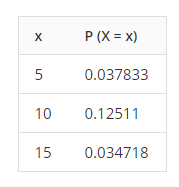
您还可以查看分布图上的离散分布,以了解各范围之间的概率。

离散 PDF 的示例
对于离散变量,PDF 将给出给定 x 值的概率值。例如,糖果制造商生产多种颜色的某一类型糖果。生产的糖果中有 30% 为黄色,10% 为橙色,10% 为红色,20% 为绿色,30% 为蓝色。

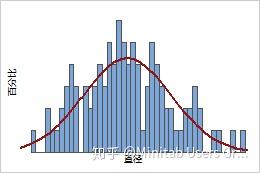
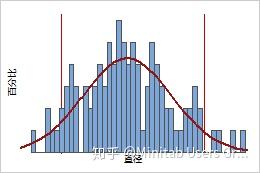
广为熟知的钟形曲线表示正态分布的 PDF。尽管软木塞直径服从正态分布,但其他测量值(如将软木塞从酒瓶中拔出所需的力)可能服从其他分布。例如,对数正态分布的 PDF 有一个长的右尾。例如,对数正态分布的 PDF 有一个长的右尾。

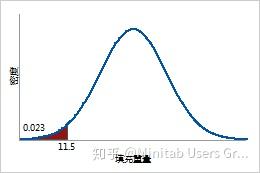
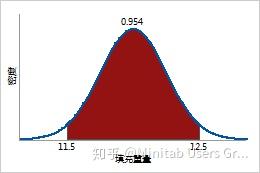
使用 CDF 可以确定随机选择的罐装苏打水的填充重量小于 11.5 盎司、大于 12.5 盎司或介于 11.5 到 12.5 盎司之间的概率。

使用“计算器”从 1 减去 p 值
计算的 p 值为 0.08795。使用 0.05 的截止值,您不能断定统计显著性,因为 0.08795 不小于 0.05。注意
该示例适用于 F 分布;但是可针对其他分布使用类似的方法。
5% 的加热管失效所需的时间预计为 0.05 倍的逆累积分布函数或 506.544 小时。
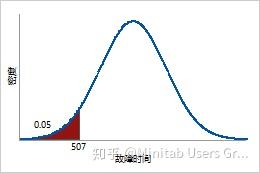
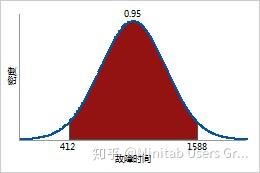
确定 95% 的加热管失效所需的时间
因此,95% 的加热管开始失效和全部失效所需的时间预计分别为 0.025 倍和 0.975 倍的逆累积分布函数或 412 小时和 1588 小时。
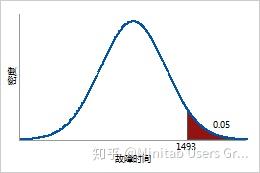
确定 5% 的加热管未失效的时间
仅剩 5% 的加热管未失效的时间预计为 .95 倍的逆累积分布函数或 1493 小时。
将出现此输出:

可以按如下方式解释输出内容:
计算超几何分布的逆累积概率
现在,您知道了与缺陷数相关联的累积概率,可以计算逆累积概率了。
假设您要计算缺陷数 x,使累积概率 p 为 0.50。通过前面的结果了解到,P(X ≤ 1 ) = 0.391619 并且 P(X ≤ 2 ) = 0.676941。由于超几何分布是一种离散分布,缺陷数无法介于 1 和 2 之间。换言之,可以有 1 个或 2 个缺陷,但不会有 1.4 个缺陷。因此,如果选择输入常量并输入 0.50,则 Minitab 将会在输出中计算这两个概率,如以下示例所示:
将出现此输出:

第一个概率指示 x 的值,使 P(X ≤ x) < p;第二个概率指示最小的 x,使 P(X ≤ x) ≥ p。在该示例中,第一个概率显示最大缺陷数 x = 2,使 P(X ≤ 2) < 0.5;第二个概率显示最小缺陷数 x = 3,使 P(X ≤ 3) ≥ 0.5。
Minitab 显示临界值 24.054。对于卡方检验,如果检验统计量大于临界值,则可以断定存在否定原假设的统计学证据。
注意
此示例使用卡方分布。但是,您可以为所选择的任何分布执行相同的步骤。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















