















































软件

产品


Fluent中的用户自定义函数(User Defined Function)UDF功能是非常强大灵活的技术,它可以帮助流体工程师实现很多标准界面之外的功能;而且,用户还可以依托UDF技术对Fluent中的算例进行不同程度的二次开发,从而有效提升实际仿真的工作效率。
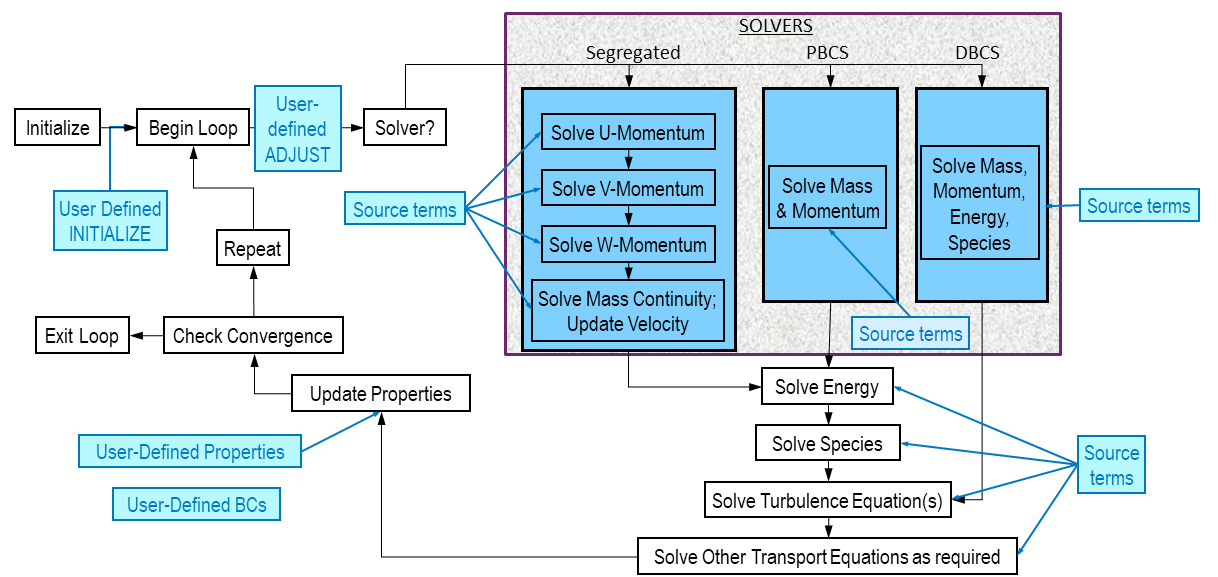
图1 UDF技术可以应用在Fluent仿真的各个环节之中
一位流体仿真的前辈曾经说过:“无论你在哪个行业、哪种产品上使用Fluent进行仿真分析,几乎都离不开UDF。因为标准界面中的内容限制过多,无法满足真实产品设计过程中的多样化需求。如果一个Fluent工程师无法熟练应用UDF技术,那么就好比是一个长不大的小孩子一样,只能按照大人给的规则进行思考和生活;只有掌握了UDF技术,才能有自己的主见,把独立的想法体现在仿真之中;这样,才能真正的成为一名成熟的流体工程师。”
图2 Fluent工程师的成长过程与UDF
当然,我们可能无法找到这段话的真实出处,也不敢完全赞同其中的观点,但它说明的道理却是显而易见的,也从一个侧面说明了UDF的重要性。在实际的工作中,UDF技术广泛应用在复杂的Fluent真实案例中,通常包括以下几个方面的内容:
• 定制边界条件,源项,反应速率,材料属性等
• 定制自定义的物理模型,或直接描述用户提供的模型方程
• 定于求解过程中的调整函数
• 根据不同的需求执行相应的函数
• 自定义在初始化过程中的个性化设置
举一个简单的例子,很多流体仿真中的材料属性是相对复杂的,比如材料的粘性,它和温度、压力、速度等变量都有相对复杂的函数关系。对于这一类情况,通常的Fluent标准界面可能就无法准确描述这种复杂的关系,此时,就必须要请出UDF来帮忙才能完成我们的需求。
1. 并行UDF代码和串行有区别
由于Fluent的求解进程在并行与串行的架构下有较大区别,因此UDF在执行的过程中也会表现出完全不一样的状态。通常我们学习UDF的课程都是基于串行代码展开的,但是大多数内容对于并行UDF都是不可用的。实际上,并行UDF的代码在相当一部分问题中需要额外的规则才能顺利、准确的执行下去。
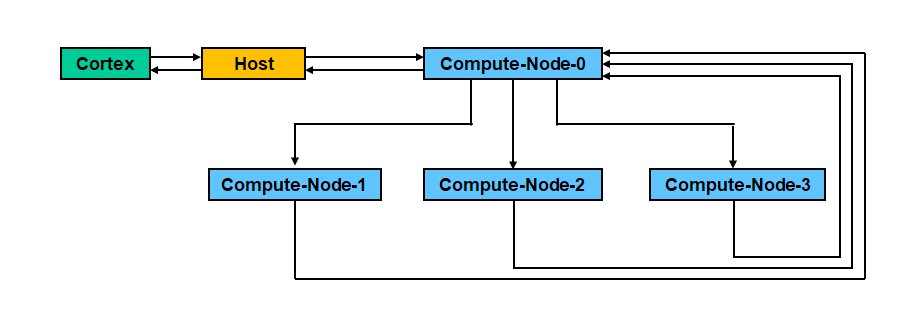
图3 使用4核并行仿真的求解架构
2. 计算机硬件技术发展迅猛
随着全世界经济的飞速发展,计算机硬件的更新换代也得到了明显的提升。对于Fluent仿真来讲,最为重要的就是CPU的性能,因为它关系着求解计算的速度快慢。目前顶级的英特尔至强处理器(E5-26xx)单个CPU就可以具备6核12线程(3.4G)或者18核36线程(2.3G)的能力,运算的速度对比5年前已有了数倍甚至数十倍的提高。而且,这些强大的多核CPU已经逐渐的配备到了各类移动工作站(笔记本)中,使得我们的仿真工作更加灵活,更加高效。因此,我们有理由相信任何一个流体工程师,都不会在如此强大的多核CPU上,使用串行方法来计算我们的Fluent仿真案例。因此,并行技术借助硬件的发展,已经成为流体仿真的必要(唯一)手段。

图4 一些主流CPU的性能指标
3. 算例更加精细,网格数量更多
硬件提升了,对应能够支持的网格数量也就随之增加,这也是近年来流体仿真取得突破性进展的坚实基础。如果时间倒退回十五年前,那么使用串行计算一个Fluent案例,将是一件非常正常的事情;但是对于眼下的仿真行业,已经无法再找到不使用并行计算的情况了。Fluent仿真经过数十年的发展,很多行业已经不满足于使用相对粗糙的网格进行概略的求解,相反,更多的人希望各通过更加准确的几何细节,和更加精细的物理模型进行详细计算,从而得到更加完整、细致、精准的仿真结果。大规模的计算需要硬件的支持,也离不开并行技术的保障。实际上,当流体仿真的网格数量超过10万时,并行计算的优势就已经可以很好的体现出来了,尤其是当一个核数对应5-8万个(六面体)体网格时,并行加速的效果是非常明显的。
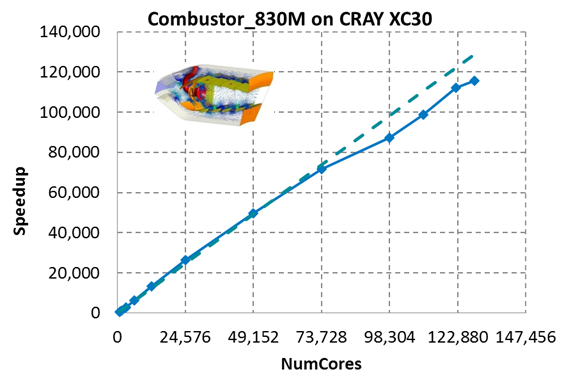
图5 Fluent 使用13万核并行计算的超大规模燃烧问题加速比
4. Fluent中完美的并行技术
Fluent软件在并行的过程中,具备非常严谨的求解进程,既能充分调用已有的CPU资源,又能很好的保证计算结果的准确性,这是Fluent本身的优势,也是Fluent多年发展的成果。可以豪不夸张的讲,Fluent具备有完美的并行能力,从任何一个角度来看都很难找到缺陷,这是其他有限元软件(至少在并行计算层面上)所无法企及的高度。因此,我们要更加珍惜Fluent的这一长处,更好的利用他,帮助我们完成仿真的任务。
值得一提的是,在Fluent R18.1之后的版本中,串行计算已经成为一个“遗留概念”;Fluent的求解架构已经完全按照并行的进程来开展工作了,即使我们选择了Serial(串行),Fluent仍旧会把算例当成1个核心的并行进行计算,从这个角度来讲,串行的UDF代码在18.1之后就退出了历史舞台,无论何种情况下,我们都必须使用并行UDF代码。

图6 串行问题在高版本的Fluent中仍旧按照并行架构进行求解
悄悄分享一个小秘密:18.1版本仍旧可以正确读取串行的UDF代码,但仅限紧急情况下使用。方法是:并行(Parallel)核数设置成0。
首先需要明确的是,并行与串行的区别仅存在于代码之中,其他的UDF环节(如编译、解释、管理、与算例hook等)则不存在任何差别。因此,我们在已经具备的串行UDF技能基础之上,仅考虑以下四个方面的差异,即可满足并行需求:
1. 并行专用的编译器指令
由于并行求解中需要区分主节点和子节点分别书写代码,因此必须要使用一些预处理的命令来判别使用的环境。当我们的代码中含有这一类指令时,读入主节点和子节点的代码会有很大的区别。
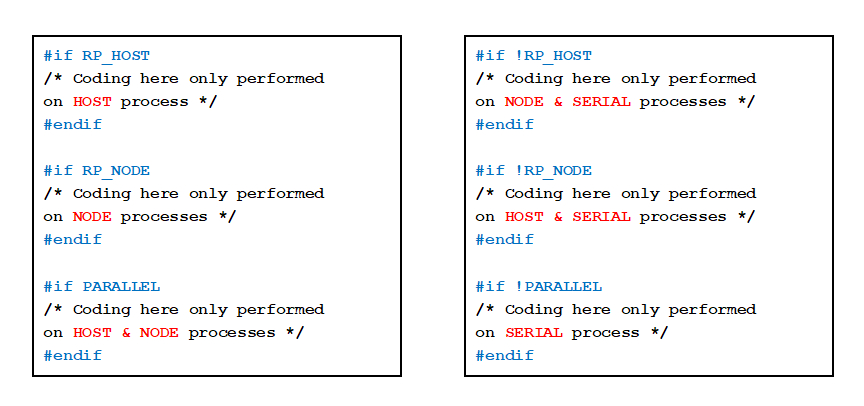
图7 并行专用的编译器指令
2. 区分内部(internal)和外部(external)单元(cell)与面(face)的循环
并行计算必须首先对网格进行分区,这样才能提高整体的工作效率。分区结束后,通常在分区的交界处会出现一些特别的单元(cell)和面(face)。基于串行代码的循环宏在处理这一类分区交界单元(面)时可能会出现错误,但这些错误在串行问题中则不会发生,因此,必须要在并行UDF中对这一类单元(面)进行特殊的处理,从而避免循环过程中的错误。

图8 并行计算中分区的网格分类
3. 全局变量(数据)缩减(变量一致性处理)
当多核并行计算时,一些全局变量(如平均速度等)在各个分区的网格中有不同的值,这就需要我们进行全局的数据统一。并行UDF在处理这一类问题中有专用的代码,可以较为轻松的实现全局变量(数据)的规模缩减和同步。
4. 子节点与主节点之间的数据传输
根据并行仿真的架构,网格的变量数据并不包含在主节点中,通过TUI输入的值也不能直接被子节点获得,此时,就必须要通过代码来实现数据的传递,这样才能使代码中的一些功能得以有效实现。
由于篇幅所限,关于UDF并行计算的详细内容无法全部展示在文章之中,如果大家感兴趣,可以关注仿真秀平台,里面有更为详细的功能讲解与介绍,同时还会有实际的并行UDF案例操作与演示。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















