















































软件

产品


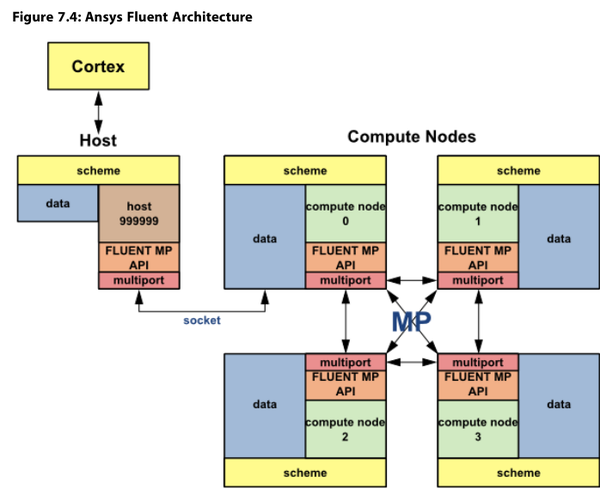
众所周知,多核并行是提高计算速度的关键,上图是fluent的并行计算方式。对于有较多网格的算例,fluent可以把不同的网格按一定方式分配到多个进程(Node,后续的‘进程’专指计算节点)中计算,注意:并不是每个节点分配的网格都不同,对于进程交界处的网格,两个进程都会计算以保证数值的连续性,所以所有进程分配到的网格数量加起来一定是大于总网格数的。每个进程并不是都会和主机通讯,而是把数据汇总到Node0,由Node0和主机交换数据,每个进程之间也会相互交换数据。基于以上,并不是进程数越多算的越快,按我的经验,每个核分配的网格数不要小于10000.
由于fluent采用的是多进程的方式(区别于多线程),每个进程的内存是独立的,因此每个进程都会加载一份UDF的dll,这种单进程联产承包责任制使得不同进程间通讯较为麻烦,需要做特别的处理以实现类似于“全局变量”之类的操作,即所谓的“并行化”。比如你要求所有网格的总数量,你在udf里把网格遍历了一遍,其实遍历的只是每个进程自己的网格,如果想要把每个进程的网格加起来,你会发现没有办法处理,这时候就需要用到fluent内置的一些并行宏。
fluent的宏基本分为两种:一种是每个网格都会执行一遍,如DEFINE_SOURCE, 这种的都有一个返回值作为该网格的参数值,这种宏不需要做并行处理;另一种是“全局”只执行一遍,如DEFINE_PROFILE,这种宏一般含有遍历、循环等操作,如果需要求“全局参数”,则需要做并行处理。下边简述常见的并行宏及其用法:
1. PRINCIPAL_FACE_P和begin_c_loop_int
PRINCIPAL_FACE_P: 很明显,对于进程的交界面,这个面类似于内部面,是既属于这个进程,又属于那个进程的。如果不同进程间都对这个面进行了操作,可能出现重复计算的问题。PRINCIPAL_FACE_P用于解决这个问题,一个面可能属于多个进程,但他只对一个进程PRINCIPAL,因此可以使用下列代码来排出重复出现的面:.
int n=0;
begin_f_loop(f,t)
{
if PRINCIPAL_FACE_P(f,t)
{
n++;
}
end_f_loop(f,t)
begin_c_loop_int: 类似于PRINCIPAL_FACE_P,begin_c_loop_int在遍历cell时只遍历内部cell,而不会遍历与之相邻的拓展cell。至于为什么face和cell的处理方式不同,这个很好理解,因为面是实实在在的交界面,没有内外之分,而单元是被面包裹在内部的,必然有内外之分。
2. 跨进程的全局计算
用的最多的是求全局的和、最大值和最小值。
PRF_GISUM1(x):求变量x在不同进程间的和。接上个代码,你用n求得了该进程下面的数量,想把不同进程的面的数量加起来,可以添加如下代码:
int sum=PRF_GISUM1(n);这样的话就可以得到总面数,而且这个sum的值在不同进程间是相同的,这个很好理解。
PRF_GIHIGH1(x),PRF_GILOW1(x)求全局最大值和最小值,和PRF_GISUM1同理,不再赘述。
3. 主机与计算节点之间交换数据
host_to_node_type_num(val_1,val_2,...,val_num):主机向计算节点传输数据,type和num为数据的类型和参数个数。
node_to_host_type_num(val_1,val_2,...,val_num)同理。
这两个宏用处较少,可以做一些读写文件操作。
4. 主机和计算节点分而治之
对于只在host执行的代码,可以用下述代码包裹:
#if RP_HOST
ABABA
#endif对于只在node执行的代码同理:
#if RP_NODE
ABABA
#endif比如host中不分配网格,网格数为0,如果在host中有除以网格数的操作,就会浮点数溢出,此时需要用#if RP_NODE来排除host。也可以做一下读写文件操作。
5. 其他
以上这些可以处理大多数情况,其他的如全局逻辑、进程号等极少用到。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















