















































软件

产品


1 前言
当计算网格数量巨大时,如果还用串行计算的话,可以把人耗死。此时用并行计算可以显著节省时间,笔者在实际应用中深有体会。同样一个案例(网格数量约200万),串行计算大约10秒钟迭代一次,而改用25核并行计算,约2秒钟迭代一次。
其实在我看来,模拟计算一定程度上比的就是计算机性能。特别当遇到网格数量巨大,且物理模型复杂的计算案例,没有好的工作站或者服务器,可以说基本没办法承担工作。
并行计算的的基本思想为:在并行计算时,FLUENT将原先的计算网格划分为若干个子区域,并将各个子区域分配给不同的计算单元执行计算工作,也叫计算节点(compute node),原先的计算网格也叫主节点(host),主节点和计算节点之间可以进行数据传递。host不存储网格数据,因此不能进行单元循环,在一些计算中可能会出现非物理解,比如分母为零。因此需要host与compute node之间的数据传递才可以进行计算。
当在并行计算中采用UDF时,可能需要对程序进行适应性修改,比如对于那些需要进行全局求和、求最小值、求最大值或者需要对相邻计算节点数据进行计算的程序,官方归纳如下:

今天我们以DEFINE_ON_DEMAND这个宏为例做一些讲解,希望对大家有所帮助,我个人本身也在学习过程中,不能说已经完全掌握了。
完成今天的案例,需确保你的计算机安装好了VS,并且FLUENT可以对UDF成功编译。如果不行,请自行上网搜索别人的经验反馈,可能没有普适性的解决办法,我的电脑是64位,VS是2010版,FLUENT是V19.0。
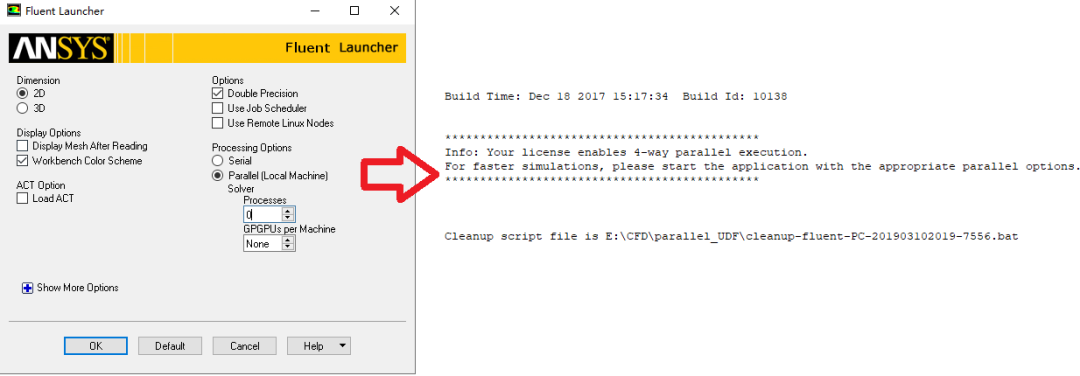
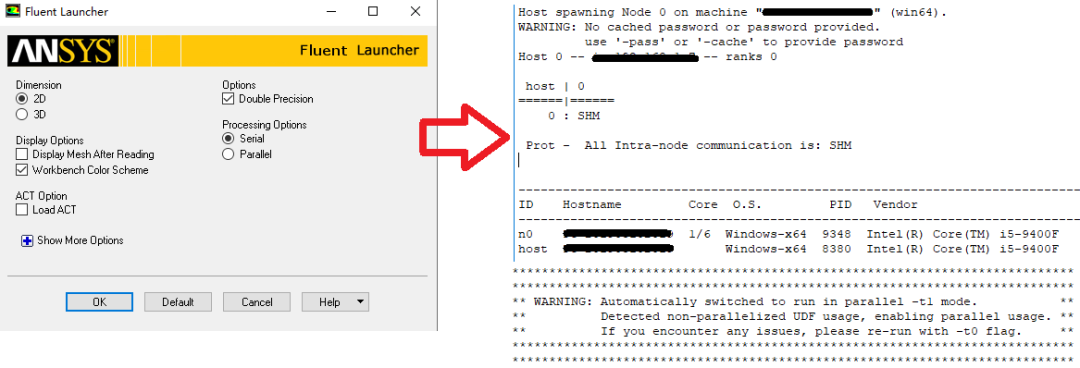
小贴士:用过FLUENT 19.0版本的读者可能会发现一个问题,即使我们选择串行求解器,还是会默认进入并行求解器。如果要进行串行计算,按如下方法可以实现:选择并行求解器,并将处理器数量设置为0就可以了,见如下截图
2 问题描述
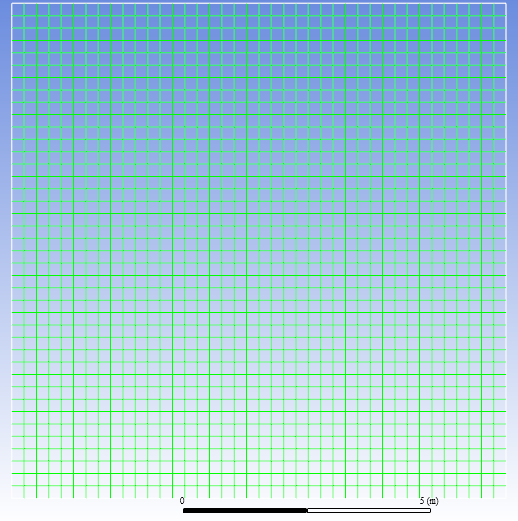
我们建立一个10m×10m的二维平面域,网格如下。我们编写DEFINE_ON_DEMAND宏,用以求解计算域的体积。很显然,计算域的体积应该是100m3。
3 计算结果
3.1 串行UDF,串行计算
未修改的UDF如下,这是一个适用于串行求解器的程序,读者应该很熟悉,我们采用编译方式进行定义,首先进行串行计算。
#include"udf.h"#include"prop.h"#include"mem.h"#include"math.h"#include"stdio.h"DEFINE_ON_DEMAND(get_volume){Domain *domain=Get_Domain(1);real volume=0;real vol_tot=0;Thread *t;cell_t c;thread_loop_c(t,domain){begin_c_loop(c,t){volume=C_VOLUME(c,t);vol_tot+=volume;}end_c_loop(c,t)}Message("\n The total volume is %g\n",vol_tot);}
程序执行结果如下,计算域体积为100m3。

3.2 串行UDF,并行计算
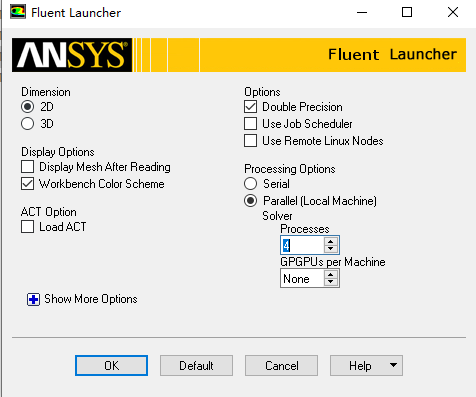
还是采用上面的串行UDF进行编译定义,但是用并行计算,我的电脑是6核,并行求解器调用4核,如下图。
程序执行结果如下,我们可以看到出现了5个结果,其中第一个为0,这是从host中获取的结果,由于host不存储数据,因此为0,如果我们的UDF程序将体积作为了分母(比如求体积加权平均),则会出现非物理解,读者可以自行尝试。另外的4个结果来自compute node,四个值相加为110.125m3,与实际值相比存在10%的误差,关于误差我们后面讨论。

3.3 并行UDF,并行计算
接下来我们将之前的串行UDF进行适应性修改,增加几行语句(粗斜体部分),修改后的程序如下。具体如何根据自己的计算需求增加语句,请读者自行研究UDF帮助文档,里面写得非常详细,可以当作设计手册来看待。本案例增加的语句我将按照自己的理解进行通俗解释,若有不当请海涵。首先,“vol_tot=PRF_GRSUM1(vol_tot)”中的宏PRF_GRSUM1(x)返回的值是所有compute node的x的和,这里指的是4个compute node各自计算的体积之和。
“node_to_host_real_1(vol_tot)”中的宏node_to_host_real_1(x)将compute node-0的数据x传递给host,这里指的是compute node-0存储的4个compute node各自计算的体积之和,也就是总体积。
“#if !RP_NODE #endif”将执行范围限定于串行或者host相关。
#include"udf.h"#include"prop.h"#include"mem.h"#include"math.h"#include"stdio.h"DEFINE_ON_DEMAND(get_volume){Domain *domain=Get_Domain(1);real volume=0;real vol_tot=0;Thread *t;cell_t c;thread_loop_c(t,domain){begin_c_loop(c,t){volume=C_VOLUME(c,t);vol_tot+=volume;}end_c_loop(c,t)}vol_tot=PRF_GRSUM1(vol_tot);node_to_host_real_1(vol_tot);#if !RP_NODEMessage("\n The total volume is %g\n",vol_tot);#endif}
程序执行结果如下,可以看出只有一个结果110.125 m3(来自host或者串行求解器),并且等于串行UDF并行计算结果之和。

对于这10%的误差,我通过网格自适应,将网格进行数次加密后,误差越来越小。为何有这误差,我尚未明白。

3.4 小结
对于本案例的并行计算,我通俗地理解为:host相当于老板,compute node相当于工人,老板将工作(计算)分配给若干工人,每个人分到的工作有老板决定。
老板当然不用亲自干活,因此如果想直接从老板那里获得工作相关内容,或者需要老板分派一些额外的命令就需要采用既定的渠道(宏)在老板和工人之间进行信息传递。而对于老板,只需要利用好各个工人的工作成果,具体要怎么利用(UDF)由老板的客户决定,而我们就是这些客户了。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















