















































软件

产品


由于各种人脸图像存在各种姿态、亮度以及遮挡等问题,无约束环境对人脸检测和对齐构成挑战。最近的研究表明,深度学习方法可以在这两项任务上可以取得亮眼的成绩,本文提出了一个深度级联的多任务网络框架,它利用了检测和对齐之间的内在联系来提高整体网络的性能。本文主体框架属于级联结构,通过三个阶段深度卷积网络,以粗略到精细的方式预测face location和landmark location。此外,本文还提出了一种新的在线难分样本挖掘策略,可进一步提高模型的性能。本文算法在人脸检测数据集FDDB和WIDER FACE以及人脸对齐的数据集AFLW测试中实现了state-of-the-art,同时保持了实时性能。
关键词:人脸检测,人脸对齐,级联卷积神经网络
人脸检测和对齐虽然基础,但对于许多面部其它应用至关重要,例如面部识别和面部表情分析。 实际应用中会存在遮挡、大的姿态变化和极端明暗变化,对这些任务构成了巨大的挑战。
Viola和Jones [1]提出的级联人脸检测器利用Haar-Like特征和AdaBoost训练级联分类器,实现了兼顾速度和准确率的良好性能。
DPM用于人脸检测并实现卓越的性能,然而,它们通常是在训练阶段需要昂贵的标注成本。
面部对齐也吸引了广泛的研究兴趣。 该领域的研究大致可分为两类,基于回归的方法和模板拟合方法。
然而,大多数的人脸检测和对齐方法忽略了这两个任务之间的内在相关性。虽然现有的一些研究试图共同解决它们,但这些研究仍然存在局限性。
另一方面,在训练过程中采集难样本对于增强检测器的性能至关重要。然而,传统的难样本挖掘通常以离线方式执行,本文设计一种用于人脸检测的在线难样本挖掘方法,能够根据当前训练状态自动抽取训练样本。
本文提出了一个新的网络框架,通过多任务学习使用统一的级联CNN来整合这两个任务,该框架由三个阶段级联而成。
第一阶段:通过简单的CNN快速生成cadidate proposal,然后选出positive cadidate proposal给到下一阶段。
第二阶段:通过稍复杂的CNN来refine proposal,然后选出positive cadidate proposal给到下一阶段。
第三阶段:使用更强大的CNN再次refine结果并输出五个面部landmark位置。
本文的主要贡献概括如下:
(1)提出了一种新的级联CNN框架,用于联合人脸检测和对齐,并精心设计轻量级CNN架构以实现实时性能。
(2)提出了一种有效的方法来进行在线难样本挖掘,以提高模算法的最终性能。
(3)在具有挑战性的benchmark测试中进行了大量实验,与人脸检测和面部对齐任务中的最新算法相比,性能显著提升。
本文总体架构示意图如下图1所示
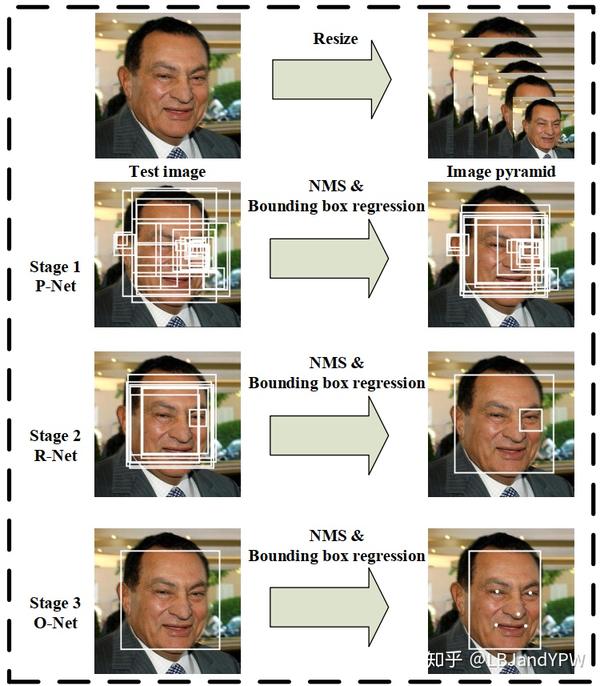
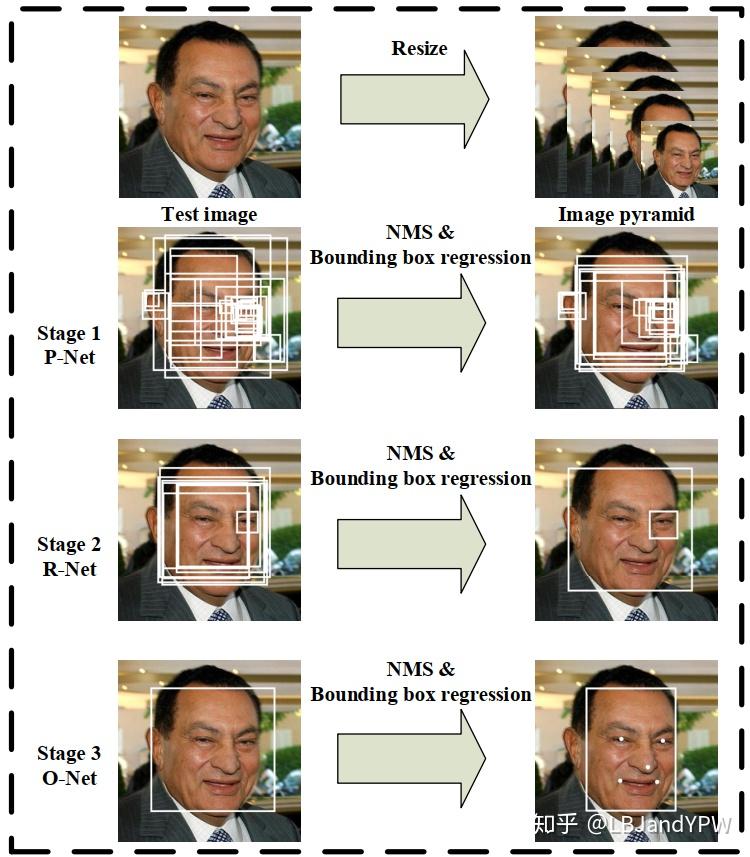
图1:MTCNN级联框架的pip-line,包括三级多任务深度卷积网络。 首先,候选窗口是通过快速提案网络(P-Net)生成的。 之后,通过精炼网络(R-Net)在下一阶段完善这些候选区域。 在第三阶段,输出网络(O-Net)产生最终边界框和面部landmark位置。
阶段1:利用称为Proposal Network(P-Net)的全卷积网络来获得候选面部窗口及其边界框回归向量。 然后基于估计的边界框回归向量校准proposal。 之后,采用非极大值抑制(NMS)来去除高度重叠的proposal。
阶段2:所有阶段1产生的proposal都被送到另一个CNN,称为精炼网络(R-Net),它进一步筛选掉false positive,使用边界框回归执行校准,并进行NMS。
阶段3:这个阶段类似于阶段2,但在这个阶段,我们的目标是识别更多监督的面部区域。 特别是,该网络将输出五个面部landmark点。
在论文[2]中,已经设计了多个用于面部检测的CNN。但是,我们注意到它的性能可能受到以下限制:
(1)卷积层中的某些卷积核缺乏可能限制其辨别能力的多样性。
(2)与其它检测任务相比,人脸检测是一项二分类任务,因此每层可能需要的滤波器数量较少。
为此,本文减少滤波器的数量并将5×5的卷积核更改为3×3以减少计算,同时增加深度以获得更好的性能。通过这些改进,可以在更少的运行时间内获得更好的性能。为了公平比较,我们在每个组中使用相同的训练和验证数据。我们的CNN架构如图2所示。我们将PReLU作为卷积层和全连接层(输出层除外)之后的非线性激活函数。
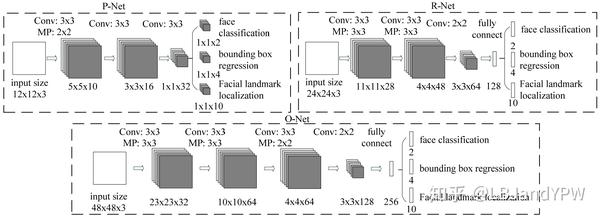
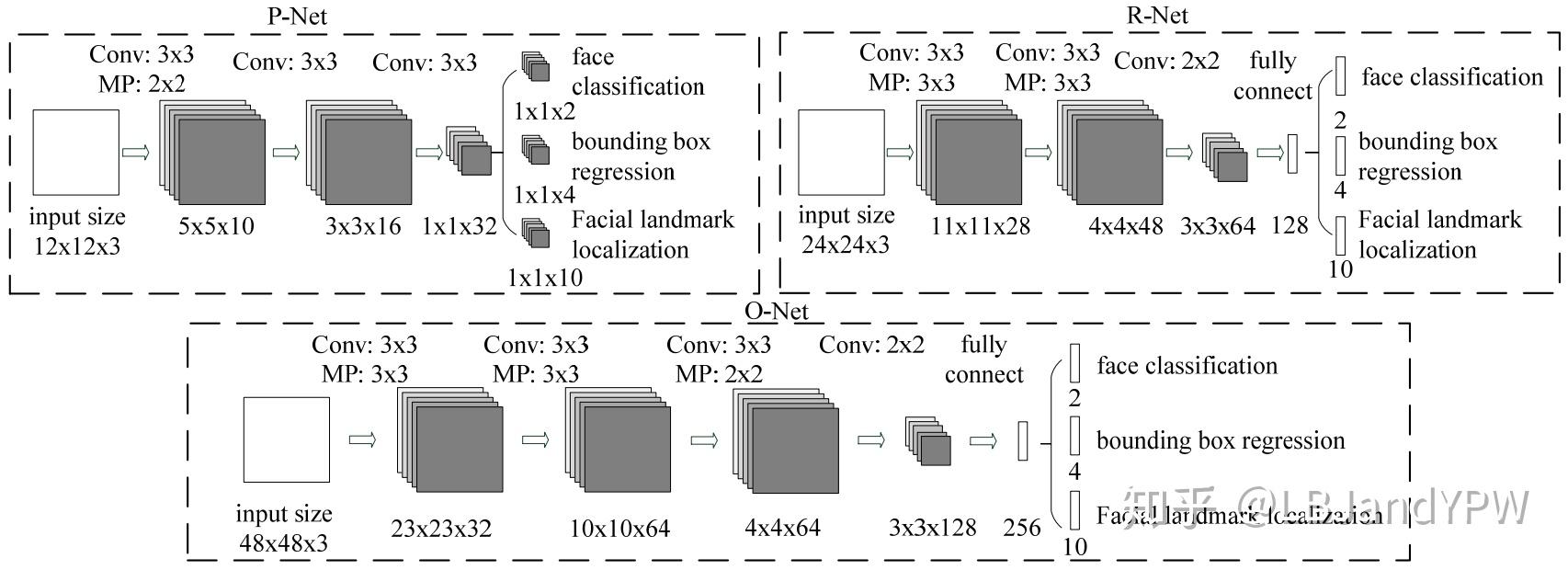
图2:整个网络其实是级联的CNN结构,每一部分的输出做为后续部分的输入。因此第一部分P-Net是全卷积网络初检网络选出可能的Cadidate proposal,之后经过后处理得到positive sample。后面R-Net最后是全连接网络,是对positive sample的refine。同理,O-Net将会进一步refine。
我们利用三项任务来训练MTCNN人脸检测器:
1)面部分类
学习目标被制定为两分类问题。 对于每个样本 ![[公式]](https://www.gofarlic.com\upload\csdn\514\55abd6ee2c07065bfd8875b4e79a1cf9.png) ,我们使用交叉熵损失:
,我们使用交叉熵损失:
![[公式]](https://www.gofarlic.com\upload\csdn\514\8013b5c2584e98891af7240e503523ad.png)
其中![[公式]](https://www.gofarlic.com\upload\csdn\514\09ddd44d82b13fd61f56d10f53fa5941.png) 是网络预测样本为true的概率,符号
是网络预测样本为true的概率,符号 ![[公式]](https://www.gofarlic.com\upload\csdn\514\e3d8f6552100e952ff0946af0b667fd8.png) 表示ground truth。
表示ground truth。
2)边界框回归
对于每个proposal,我们预测它与最近的ground truth之间的偏移量(即边界框的左边、顶部、高度和宽度。 学习目标被制定为回归问题,我们对每个样本使用欧几里德损失函数:
![[公式]](https://www.gofarlic.com\upload\csdn\514\292758c764b5060c04dd4b260f513379.png)
其中 ![[公式]](https://www.gofarlic.com\upload\csdn\514\64d6860634913c833639a1513c21d5b6.png) 是网络预测的bbox位置回归结果,
是网络预测的bbox位置回归结果, ![[公式]](https://www.gofarlic.com\upload\csdn\514\3be5d1ed02f83bde7b454e27f2b7324f.png) ground truth的位置。
ground truth的位置。
3)面部landmark定位
类似于边界框回归任务,面部landmark也被作为回归问题,我们使用最小化欧几里德损失:
![[公式]](https://www.gofarlic.com\upload\csdn\514\bcd5d12e2c6d831d2bf027afe5caa640.png)
其中 ![[公式]](https://www.gofarlic.com\upload\csdn\514\d3fdd0c6d5343fed128820f039fc66cf.png) 是网络预测的位置结果,
是网络预测的位置结果, ![[公式]](https://www.gofarlic.com\upload\csdn\514\8947a39f36e519b7b793d679019da9d5.png) 是第
是第 ![[公式]](https://www.gofarlic.com\upload\csdn\514\b1677f9423a31be742701330c190cf05.png) 个样本的ground truth,5个位置分别是左眼,右眼,鼻子,左嘴角和右嘴角。
个样本的ground truth,5个位置分别是左眼,右眼,鼻子,左嘴角和右嘴角。
4)多源训练
由于每个CNN中使用不同的任务,每个阶段的CNN有着不同的训练目的,因此使用样本类型指示符来实现,然后整体学习目标可以表述为:
![[公式]](https://www.gofarlic.com\upload\csdn\514\ad7ed189c534cb08a98740096fd0871a.png)
![[公式]](https://www.gofarlic.com\upload\csdn\514\b5edc03934564b6fc6a72b7804435505.png) 是表示不同网络结构det、box、landmark的损失函数的权重不一,由于O-Net要输出精准的landmark,所以O-Net的landmark损失权重会比前面两个阶段的网络要大。
是表示不同网络结构det、box、landmark的损失函数的权重不一,由于O-Net要输出精准的landmark,所以O-Net的landmark损失权重会比前面两个阶段的网络要大。
![[公式]](https://www.gofarlic.com\upload\csdn\514\137d4b8b4111fd48081f99c9794c6452.png) 的意思是数据类型指示器indicator,简单的理解就是一个batch的图片feed到网络后,如果是negative,那么它只贡献分类loss,如果是positive,那么不仅贡献分类loss,还贡献box loss(即位置回归loss,如果图片是part face则它仅贡献于box loss, 如果图片是landmark face,则它仅贡献于landmark loss。
的意思是数据类型指示器indicator,简单的理解就是一个batch的图片feed到网络后,如果是negative,那么它只贡献分类loss,如果是positive,那么不仅贡献分类loss,还贡献box loss(即位置回归loss,如果图片是part face则它仅贡献于box loss, 如果图片是landmark face,则它仅贡献于landmark loss。
5)在线难样本挖掘
在每个小批量中,对来自所有样本的前向传播中计算的损失进行排序,并选择其中top-70%作为难样本。 然后我们只计算后向传播中这些难样本的梯度。这意味着我们将会忽略在训练期间不太有助于加强检测器的简单样本。 实验表明,该策略无需手动选择样本即可获得更好的性能。
由于我们联合进行人脸检测和对齐,这里我们在训练过程中使用了四种不同的数据注释:
label的用途:
网络做人脸分类的时候,使用postives 和negatives的图片来做,为什么只用这两种?因为这两种数据分得开,容易使模型收敛(为了分得开,所以训练样本选取也是很关键的)。
网络做人脸bbox的偏移量回归的时候,使用positives 和parts的数据,不能使用negatives, 因为negative基本不包含人脸信息,这个时候使用这种样本来训练学习bbox将会不利于模型。而positive和part的数据里面人脸部分比较大,适合用来做回归,网络还能够看到鼻子、眼睛、耳朵等部位来进行回归(和通用的目标检测算法是一个道理)。
网络做人脸landmark 回归的时候,就只使用landmark face数据了。(这个脸必须是全部的,否则不利于网络学习)
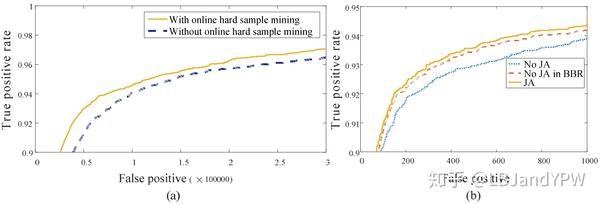
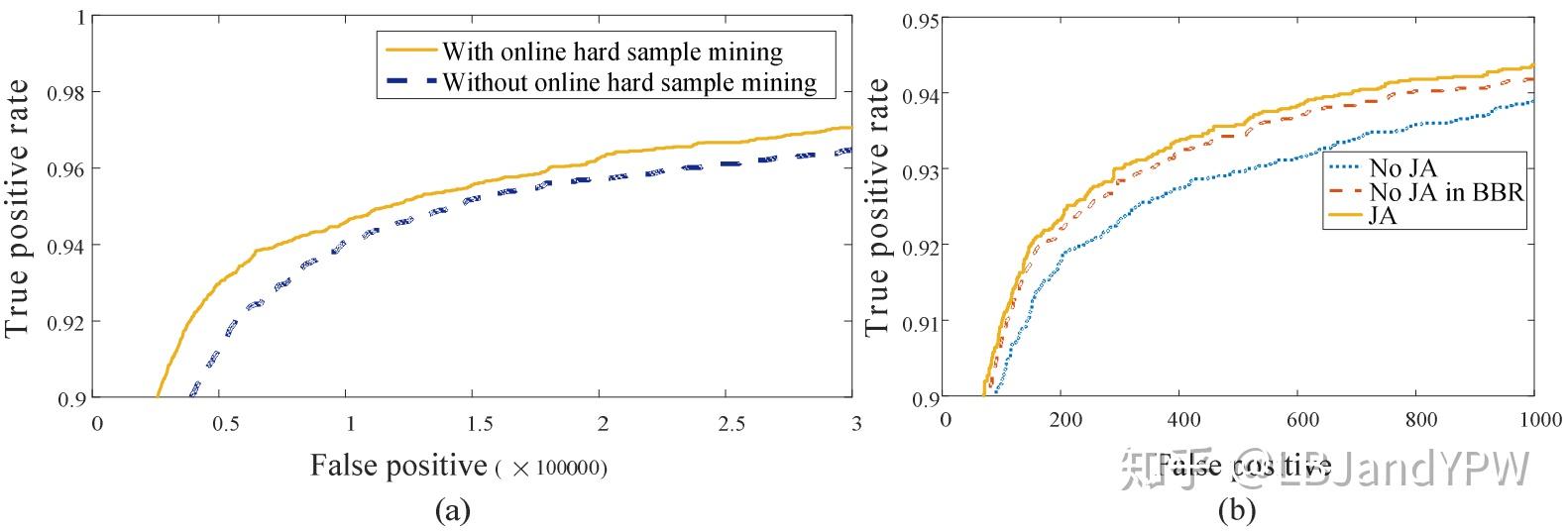
图3:果然联合训效果是比较明显的


免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















