















































软件

产品


开先河之作,是1992年Cootes提出的ASM模型。ASM方法从局部的特征来检测点,对噪声很敏感。1998年Cootes提出改进都AAM,但对于 初始化 和appearance的改变很敏感。两者都使用了shape model (PCA),它的缺点是模型不够灵活,不能实现细微调整(如主成分维度不变)。
更多总结:
人脸关键点检测总结
CVPR2012上有一篇非常有名的特征点定位,提出了非参数的形状约束,使用了two level cascaded regression 和shape indexed features,提高了对于人脸appearance的变换,提出了correlation based features selection,解决了大训练集的训练问题,提高了时间效率。
大致流程如下:
首先算法得输入是一张人脸图片,观察图片,发现其实人的五官大体位置是有的。算法一开始,就给了一个大体的初始位置。这个初始位置是根据经验设定的:
初始位置有了,我们在每个点的周围按照预先规定的要求取两个点,算出这两个点的灰度差值。然后将这个差值按照预先规定的方式归一化到0-511内,假设这个值为120。比较120与th1的大小,如果120>th1,那么我们生成一串数字【001】。如果120<=th1,那么我们再按照预先规定的方式取两个点,同样算出这两个点的灰度差值,同样按照的方式归一化到0-511内,假设这个值为50,然后比较50与th2的大小,如果50>th2,我们生成一串数字【100】;如果50<th2,那么我们就生成一串数字【010】。th1,th2也是预先规定的: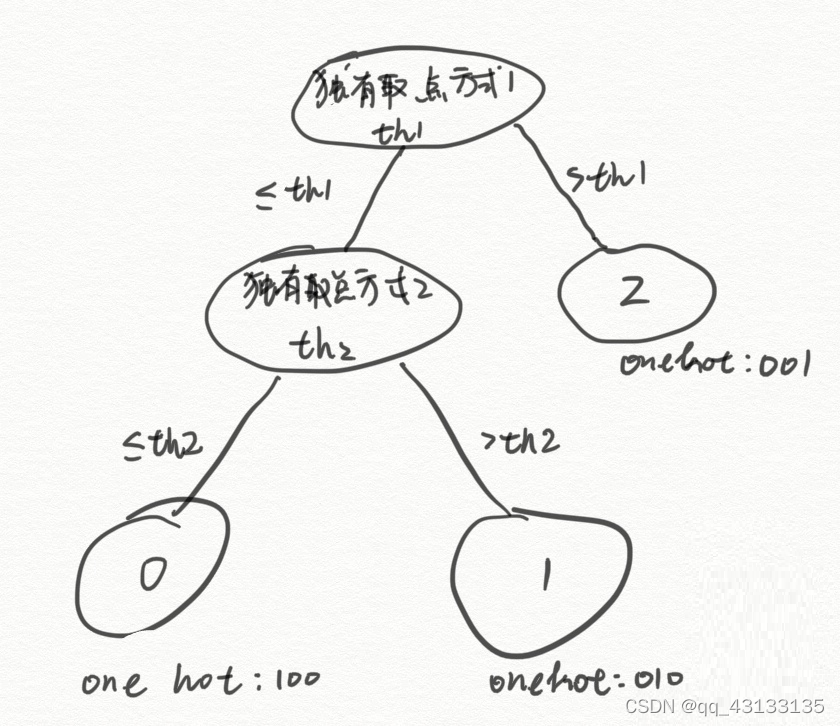
经过上面这样的一个决策树,我们得到一串数字100,或者010,或者001。
实际上,每个关键点生成了4个决策树,每个决策树中规定的取点位置不同,每个决策树中的th1,th2的具体取值也不同,也就是4个不同的树。经过一个树得到一串数字。经过4个树,得到4串数字,比如[100][010][001][010],连起来写的话,就是一串有12个值的数字[100 010 001 010]。这是一个稀疏向量,大部分数字都是0。
由于每个点有4个决策树,我们这里有5个关键点,所以我们事先准备了5* 4=20个决策树树。每个树得到3个数字。20个树就得到20* 3=60个数字,即长度为60的向量。
这60个数字,是由0和1组成的,所以叫binary feature,二值特征。又因为这些数字是在关键点初始位置周围取的点求的,所以又叫 local binary feature,LBF,局部二值特征。
一张图片得到了一个LBF特征。这个1x60的特征向量与另一个1x60的权重向量 w 1 w_1 w1做点积,然后加上一个常数 b 1 b_1 b1,就得到了一个值 δ 1 \delta_1 δ1, 将这个 δ 1 \delta_1 δ1加到初始位置的第1个点的x坐标上; 同样再与另一个1x60的向量 w 2 w_2 w2做点积,再加上一个常数 b 1 b_1 b1,就得到了一个值 δ 2 \delta_2 δ2 ,将这个 δ 2 \delta_2 δ2 加到初始位置的第1个点的y坐标上。:
δ 1 = L B F ∗ w 1 + b 1 \delta_1=LBF * w_1 +b_1 δ1=LBF∗w1+b1
δ 2 = L B F ∗ w 2 + b 2 \delta_2=LBF * w_2 +b_2 δ2=LBF∗w2+b2
这里 w 1 w_1 w1, b 1 b_1 b1, w 2 w_2 w2, b 2 b_2 b2都是预先训练好的,这里实际上是一个线性预测模型。为了移动一个点,用了4个决策树,生成一个LBF特征,又用了2个线性预测模型,分别预测了点在x轴,y轴上的移动量,完成一个点的移动。移动5个点,一共用了4* 5=20个决策树,2* 5=10个线性预测模型。
通过上述步骤就将第1个关键点移动了[ δ 1 \delta_1 δ1, δ 2 \delta_2 δ2],就把关键点从初始位置,移动到了关键点应该所在的位置:
同样的方法,我们得到 [ δ 3 , δ 4 ] , [ δ 5 , δ 6 ] , [ δ 7 , δ 8 ] , [ δ 9 , δ 1 0 ] [\delta_3,\delta_4],[\delta_5,\delta_6],[\delta_7,\delta_8],[\delta_9,\delta_10] [δ3,δ4],[δ5,δ6],
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















