















































软件

产品


经常有小伙伴在使用Fluent并行求解大规模计算时,发现虽然硬件配置很高,但时并行计算的效率却很低,processors数量调大调小都不管用,为此搞得焦头烂额。今天就针对这种问题进行一些科普,希望小伙伴们在读过之后,可以亲自设置一下,让自己的Fluent算例都快得飞起。
文章内容主要分为以下部分:Fluent并行计算基本概念、Hwloc的概念、并行效率低的原因及解决方案,以及一些其他提高并行效率的手段。
1. Fluent并行计算的基本概念
Fluent 并行计算就是利用多个计算节点(处理器)同时进行计算。并行计算可将网格分割成多个子域, 子域的数量是计算节点的整数倍(如16个子域可以对应1、4、8个计算节点)。每个子域(或子域的集合)就会“居住”在不同的计算节点上。
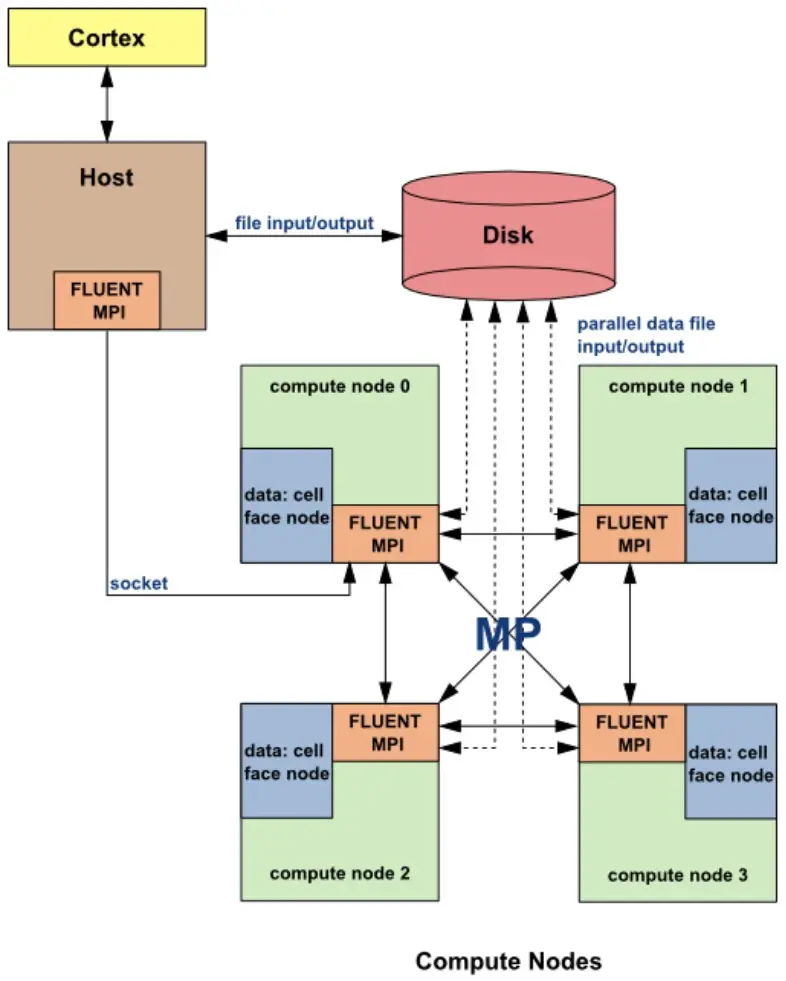
图1. Fluent并行求解通信过程
如图1中所示,Fluent在并行求解过程中,实际启动了多个相互通信的进程:Cortex(人机交互进程),Host进程(主节点进程)和若干计算节点进程(Compute node进程)。其中,Host进程并不存储任何网格和物理场数据,多数情况下,它只是将Fluent人机交互进程Cortex的指令进行解释并分发给各个计算节点进程;而计算节点存储网格和物理场数据,在接到Host进程分发的指令后,进行矩阵计算,他们之间存在一种虚拟的数据链接,是通过MPI来相互传递数据的。
大家注意,这里的计算节点并不是硬件物理意义上的计算节点,而是Fluent为了区分Host进程,而定义的一种与其功能有所区别的进程(专门用来计算)。
由于流体计算量通常都很大,所以我们可以想象得到Fluent计算节点进程的计算量非常繁重(每个进程要负责相当庞大数量网格的计算),因此最为理想的模式是:为每一个计算节点进程分配一个专享的CPU物理核心(Core)。
2. Hwloc的概念
便携式硬件位置hwloc(Portable Hardware Locality)软件包提供了便携式抽象(跨操作系统,版本,体系结构等)现代体系结构的分层拓扑结构,包括NUMA内存节点,共享缓存,处理器插槽,处理器内核和处理单元(逻辑处理器或“线程”)。它也聚集各种系统属性,例如缓存和内存信息。
Hwloc主要是旨在帮助应用程序收集有关现代的信息计算硬件,以便相应有效地利用它。例如,两个紧密协作的任务最好是放在共享缓存的内核上以便提升速度。
3. 并行效率低的原因及解决方案
3.1. 问题1:有小伙伴在Fluent启动界面设置的并行计算节点进程数大于他所实际拥有的物理核数,计算时发现并行效率很慢。
原因:并行节点数大于实际物理核心数,会使得每个计算进程就像馋嘴的娃娃,都想独享某个CPU物理核这块蛋糕,结果最后谁也不能完全占有,所以每个计算进程都变得非常缓慢。
解决方案:将并行节点数设成稍低于实际物理核心数。
3.2. 问题2:Fluent的计算节点进程数小于计算机的物理核心数,但并行速度却非常慢,同时,可以监控到CPU使用率非常低。
原因:Hwloc错误导致MPI无法将并行进程绑定到唯一核上,最终多个进程使用同一个核,从而导致计算效率低。
解决方案:
1)使用Intel MPI。
Intel MPI内置有自动的绑定机制。在Linux平台上,如果使用的是Platform MPI。Platform默认并不绑定,必须显式打开(需要将 /etc/startmethods.ccl 中的‘-cpu_bind’ flag移除
2)采用命令行的方式启动Fluent。
Windows下:-affinity=1
Linux下:-affinity=core
这样Fluent将强行把每个计算进程分配给一个专门的物理核心(CPU Core)
4. 一些其他提升并行效率的手段
4.1. 关闭超线程
Fluent的计算是CPU密集型的任务,使用超线程表面上增加了计算机的逻辑核心数(Logic Cores),实际则降低了硬件针对此类科学问题的真实计算能力。在一些客户的计算机上,开启同样多的计算进程,使用超线程的效率较不使用超线程的效率要低20~30%左右;在另外一些计算平台上,差距甚至更大!
关闭超线程的具体方法,下面以华硕主板为例。(其他型号主板大同小异,只需要找到SMT字样即可;有些服务器主板,可能在BIOS里显示的是Hyper-Threading Technology,Disable掉就可以)
首先开机按del键进入BIOS(有些是F2,有些F5或F8,看具体主板)。
进入BIOS后找到CPU Configuration。
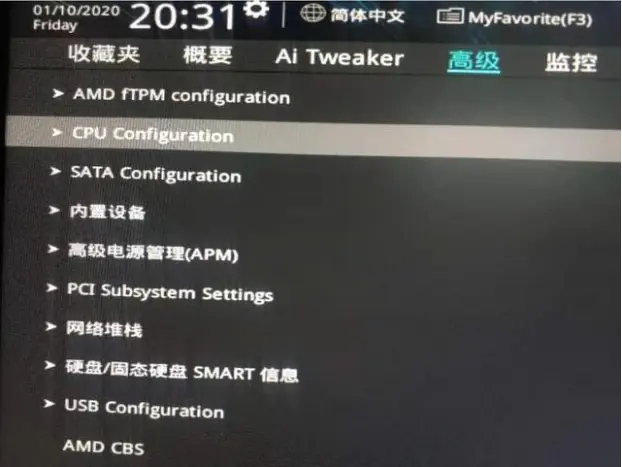
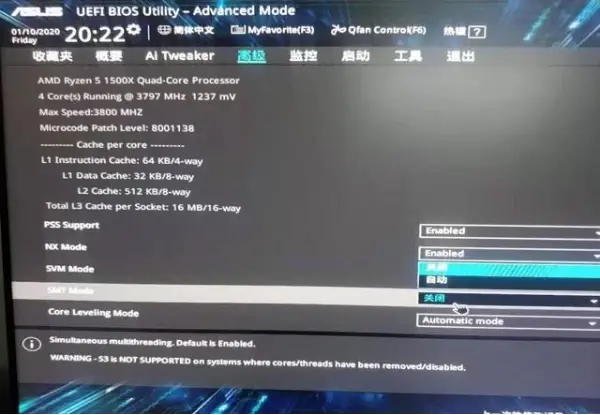
进入CPU Configuration,找到SMT Mode,选择关闭。
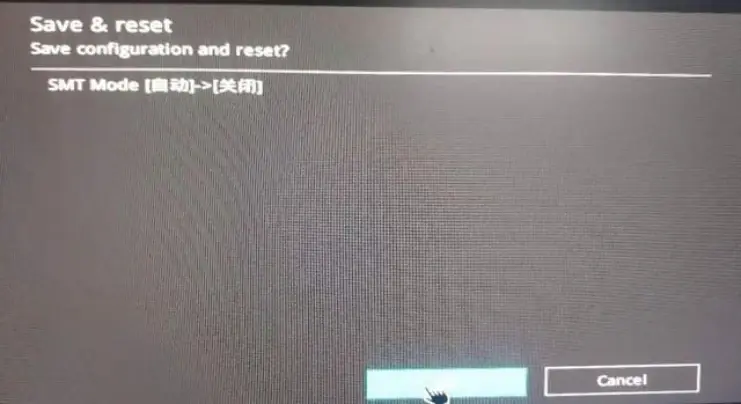
随后按F10保存,重启电脑。
重启后进入电脑系统,可通过任务管理器中的性能选项卡,或使用CPU-Z查看CPU的核心数和线程数。
4.2. 使用硬件物理核心数减1作为并行节点数量
Windows系统本身消耗一定量的硬件资源。当在求解一些大问题时,如果我们“完全”利用该系统的物理核心,可能会遭遇意向不到的效率降低。
例如,有位小伙伴有一台Windows系统的64个物理核心的图形工作站。他现在要计算一个网格量是1亿的大问题,并且使用了这台工作站的全部64个物理核心。有时,他会发现使用64个物理核心反而比63个物理核心要慢。其中原因正是Windows的一些系统进程与Fluent的计算进程之间发生了资源的“争夺”。
5.附:HPC加速效果
Case1. ANSYS从R19.0开始,到2021R2版本,HPC使用核心数对于计算速度的提升,算法的优化保证了更好的加速效果。
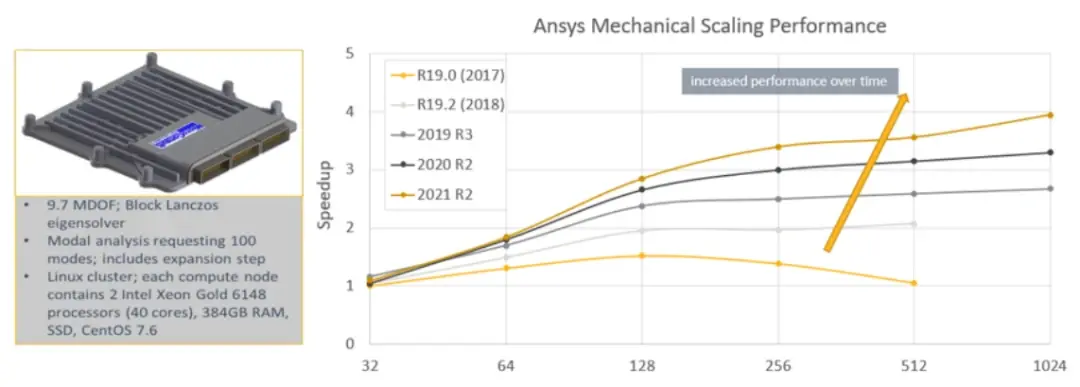
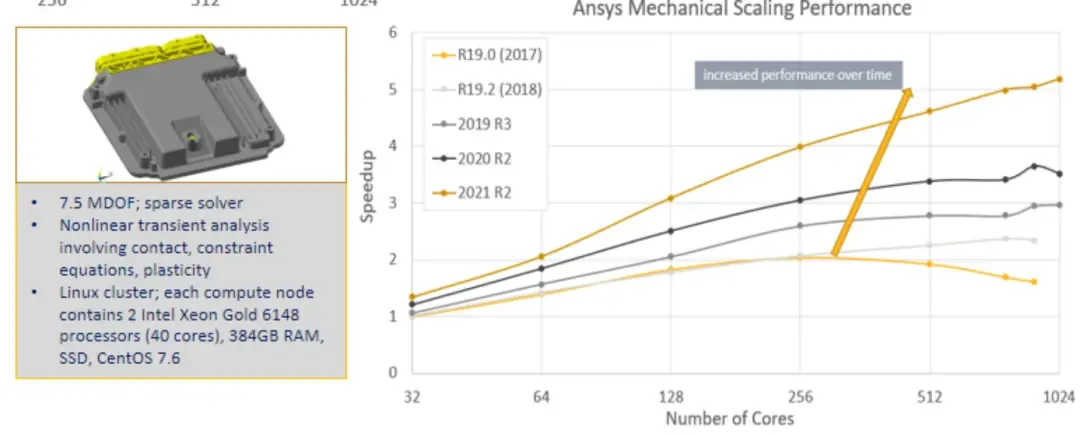
Case2. 12m网格数量的燃烧器仿真
单节点采用64核心,不同节点数量下Fluent并行加速效果

Case3. 140m网格数量的F1赛车外流场仿真(动网格模拟车轮转动)

不同版本下HPC加速效果对比
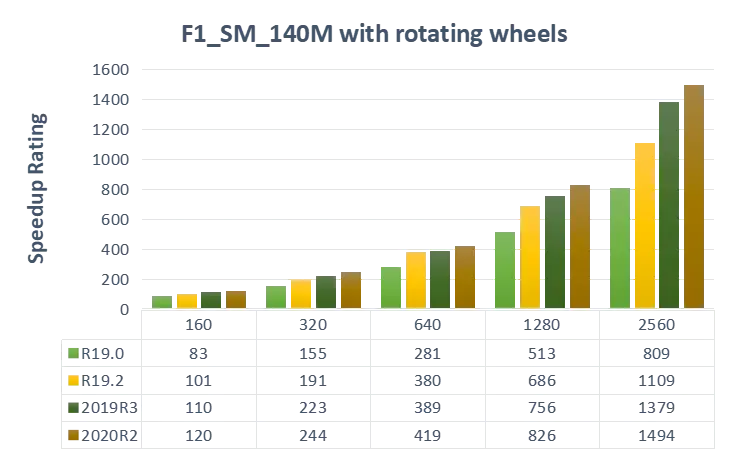
同版本下,不同节点数量加速效果对比(单节点64核心)
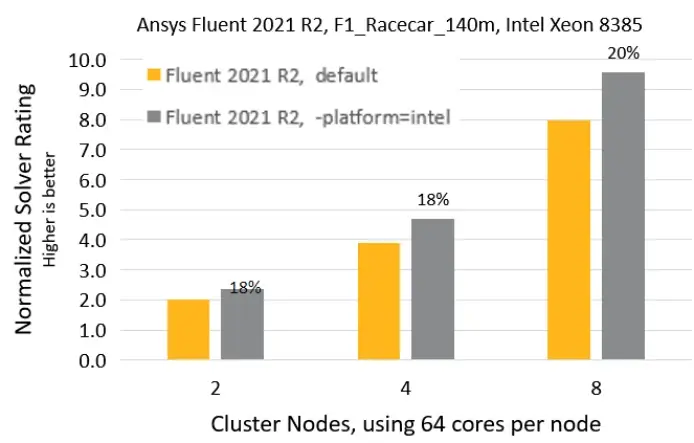
可以看出,HPC可以加速计算速度,且越新的版本,HPC对于计算速度的提升越大。
完

武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















