















































软件

产品


语言如何影响思维?人类如何从语言中获取意义?
这两个基本问题是我们构建类人智能的关键。
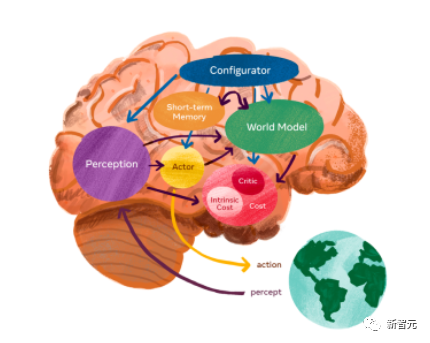
长久以来,理想中的AI,一直是通往人类水平的AI,为此业界大牛Yann LeCun还曾提出了「世界模型」的构想。
 图片
图片
他的愿景是,创造出一个机器,让它能够学习世界如何运作的内部模型,这样它就可以更快速地学习,为完成复杂任务做出计划,并且随时应对不熟悉的新情况。
而最近麻省理工大学和斯坦福的学者提出了一个理性意义构建模型( Rational Meaning Construction),这是一种用于语言信息思维的计算框架,可将自然语言的神经模型与概率模型相结合。
论文第一作者是来自麻省理工大学大脑与认知科学学院的一名五年级博士生。
 图片
图片
他们将语言意义定义为从自然语言到概率思维语言(PLoT)的上下文相关映射——概率、生成世界建模的通用符号基础。
这种架构集成了两种以前从未结合在一起的强大计算工具:他们用概率程序对思维进行建模,并通过大型语言模型(LLM)对意义构建进行建模。
 图片
图片
论文链接:https://arxiv.org/abs//2306.12672
 图片
图片
Github链接:https://github.com/gabegrand/world-models
现在以ChatGPT为代表的大语言模型大热,一会儿语言模型一会儿自然语言处理的一下容易搞不清楚,这里的「语言」又和语言学有什么关系?
首先从学科划分来说,语言学是语言学,大语言模型和自然语言处理则属于人工智能学,第一个概念是一个学科,第二、三个概念属于另一个学科。
大语言模型和自然语言处理不是「与」的关系,也即不是并列关系。自然语言处理是研究如何用人工智能的方式来处理文本内容,方式有很多,其中有一种叫「语言模型」的方式。
从人工智能的角度来看,语言模型与其说是一种模型,不如说是一种用于训练模型的预测任务。
通俗来讲,是根据给定一串文本要求模型预测下一个词,或者在一串文本中间挖走一个词要求模型做完形填空。模型通过不断迭代提升预测性能。
有网友还贴心的归纳了世界模型的迭代规律。
 图片
图片
说了那么多,下面来看看这次提出的模型架构。
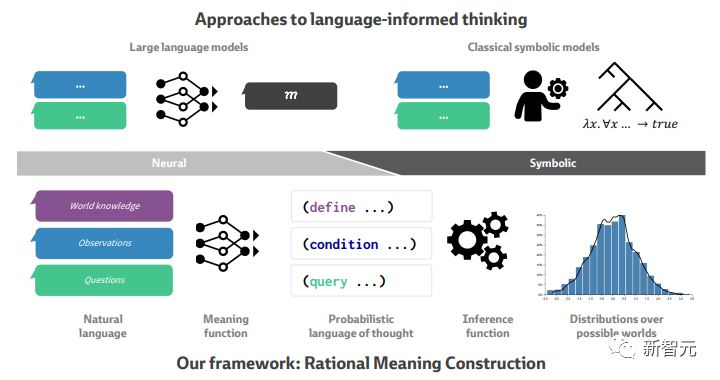
语言信息思维的计算方法依赖于神经符号连续体:一方面,经典符号模型(Classical symbol models)(右上)产生系统的、结构化的推论,但通常仅限于狭窄的语言领域,并且通常需要手工设计。
 图片
图片
另一方面,大型语言模型(左上)在开放域自然语言方面取得了非凡的能力,但难以在支持连贯的推论、预测和计划的一致的世界状态中进行推理。
而我们的理性意义构建框架将语言信息思维分解为两个模块:
意义函数将自然语言转换为概率编程语言(PPL)语句,这些语句代表符号世界模型的语言意义。
推理函数计算可能世界空间上与语言信息一致并以语言信息为条件的概率。
与传统的认知观点一样,思维的核心是构建通用表示,用于对世界上的实体和事件进行建模,足以支持不确定性下的理性、连贯的推论,并规划实现我们目标的行动。
然后,我们考虑语言如何与该架构相关联,以支持基于语言的思维——语言如何建立世界建模和推理,以指导、约束和驱动我们的下游思维,并培养新的思维能力。
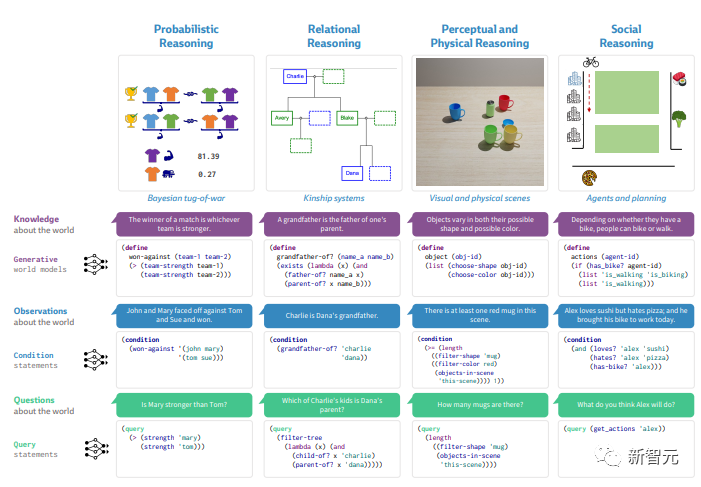 图片
图片
接下来是构成本文推理核心的四个领域:
在所有领域,我们提出了一个统一的框架,将语言转换为概率编程语言的代码,以促进类人推理。
他们从理性、概率的角度对生物智能和人类语言进行了三项观察:
生物智能包含许多计算能力。我们在这里关注的基本思想概念集中在理性推理和决策上为自己的目标服务,从这个角度来看,思想包含了对世界进行建模的系统。
与思想一样,语言也包含许多系统和能力,我们对语言采取广泛的理性视角——我们认为语言是一种以目标为导向的行动系统,用于将思想外化并与其他智能生物进行交流。
最后,我们对语言和思维的综合计算方法建立在人类是资源理性思考者的广泛证据之上,在时间和内存有限的约束下,我们合理分配计算资源,以便做出有用的推论。
 图片
图片
为了说明我们的框架,让我们考虑一个具体场景,重点关注在给定预先指定的世界模型的情况下根据语言进行推理。
假设一位朋友正在向您讲述之前发生的一场拔河比赛:
(A) 生成模型定义了两个潜在特征,即「力量和懒惰」,并指定了它们如何相互作用以确定团队强度。通过结合 (A) 和 (B),我们可以少量提示LLM进行翻译,将开放式自然语言 (C) 转化为 Church 语句 (D),捕获该领域的语言意义。
由此产生的概率推论透明地代表了模型的信念,并且自然地捕捉关于玩家潜在特征的类似人类的直觉。
面对世界模型的不确定性,我们输入问题如,「如果他们再次比赛,乔什会击败加布吗?」
在我们的框架中,我们将问题转化为Church中的查询语句,以评估兴趣的数量。
调用查询会触发概率计算,模拟模型下可能的世界,并受到迄今为止任何观察的约束。
查询表达式在每个模拟世界中进行评估,产生多个样本,这些样本形成感兴趣值的后验分布。
在本工作的整个示例中,我们自由地交织查询和条件语句,就像自然对话中的事实陈述之间偶尔会出现问题一样。
此行为是通过读取-评估-打印循环 (REPL) 实现的,该循环根据出现的所有条件语句评估查询对话历史中的那一点。
在我们的模型中,我们假设用户指定每个话语是否是条件或查询,但大语言模型可能可以准确地对未注释的话语进行分类。
人类语言的意义理论应该解释语言如何与我们的思想相关,这一愿景是人类语言和意义理论的核心,但人工智能最广泛的愿景长期以来也是计算机共享我们的语言,能够像我们期望被其他人理解的那样有意义地理解我们。
当今的大型语言模型在许多重要方面都在构建这一现实方面取得了惊人的进步,我们第一次构建了能够流利地与我们对话的计算机系统。
不过,我们还需要做更多的工作来捕捉我们自己与语言的关系。我们不像大型语言模型那样学习语言。我们首先思考,然后从少得多的输入中学习语言如何映射到我们的思想中。
我们自己的世界模式和信仰并不是我们从语言中收集到的脆弱的副产品——它们是我们认知的基础和核心,是为了我们的意图和愿望而有目的地构建和维护的。
通过使用神经模型将句子翻译成概率程序,我们解决了世界模型如何从描述不确定情况、关系结构、具体情况和目标导向推理的语言中提取含义并推理引擎如何推理。
同时也留下了许多悬而未决的问题,例如如何将该框架扩展到更复杂的语言,以及如何自动化为新领域构建意义表示的过程。
这些问题共同为解决跨越人工智能和认知科学的许多子领域建模语言、推理及其交互方面的核心挑战提供了路线图。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















