















































软件

产品


最近在做模型训练,发现在导入大量数据时,由于要进行预处理(concat和reshape操作等),导致内存会占满,使得程序出错。由于输入数据存在大量的稀疏情况,想着能不能输入数据时利用稀疏矩阵进行保存,然后输入到模型中进行训练。
python中scipy.sparse模块,能够有效的对输入数据进行稀疏化存储。但缺点在于稀疏矩阵必定只有两维的操作,但一般图片分类设置到多个维度,因此需要提前把输入数据reshape成两维矩阵。
假设现有的图片大小为[3, 31,31]。其中是图片的大小,而是图片channel。有20w的数据,则内存需要提前存储[200000, 3, 31, 31]的容量大小,这对于小内存的机器来说是不可行的。因此需要先把这20w图片进行稀疏化矩阵操作:
import numpy as np
from scipy.sparse import csr_matrix
input_data = []
with open(file, "r") as f:
while True:
line = f.readline()
if line:
fig = csr_matrix(np.reshape(line, [3, 31*31]))
input_data.append(fig)
else:
break
[200000 * 3, 31*31]的稀疏矩阵,这样就能够有效的在内存中进行存储from scipy import sparse
input_data = sparse.vstack(input_data)
在tensorflow2.0中,可以包装对应的稀疏矩阵进行输入。
def get_sparse_tensor(input_data):
indices = list(zip(*input_data.nonzero()))
return tf.SparseTensor(indices=indices, values=np.float32(input_data.data), dense_shape=input_data.get_shape())
[batch_size, 3, 31, 31],这样才能用卷积的方法进行训练,核心代码如下:# 把稀疏矩阵进行reshape操作
input_global_map = tf.sparse.reshape(input_global_map, [-1, 3, 31, 31])
# 把sparsetensor转换成普通tensor,这样模型才能够训练
input_global_map = tf.sparse.to_dense(input_global_map)
具体可以看github代码,其中“model_conv_pooling.py”是模型的构造代码:
https://github.com/llq20133100095/tensorflow-sparsetensor
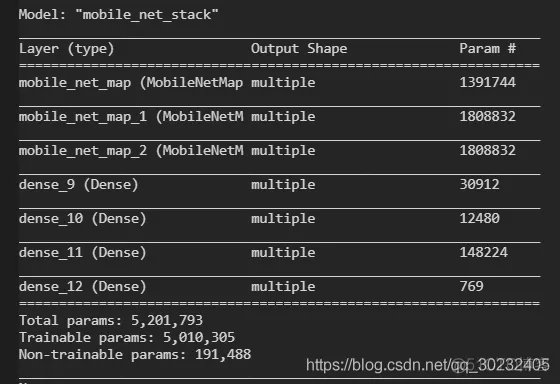
最后可以看一下模型参数:
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















