















































软件

产品


TensorFlow XLA优化原理与示例XLA概述
XLA(加速线性代数)是用于优化TensorFlow计算的线性代数的域特定编译器。结果是在服务器和移动平台上的速度,内存使用率和可移植性得到了改善。最初,大多数用户不会从XLA中看到很大的好处,通过使用即时(JIT)编译或提前编译(AOT)的XLA进行试验,针对新硬件加速器尝试XLA。
XLA框架是实验性和积极的开发。尽管现有操作的语义不太可能发生变化,但预计将增加更多的操作来涵盖重要的用例。
XLA与TensorFlow合作有几个目标:
XLA的输入语言称为“HLO IR”,或称为HLO(高级优化程序)。操作语义页面描述了HLO的语义。将HLO视为 编译器IR是最方便的。
XLA将HLO中定义的图形(“计算”)编译成各种体系结构的机器指令。XLA是模块化的,很容易插入替代后端,以便定位一些新颖的硬件架构。用于x64和ARM64的CPU后端,以及NVIDIA GPU后端,均位于TensorFlow源代码树中。
下图显示了XLA中的编译过程:

XLA带有多个与目标无关的优化和分析,如 CSE,独立于目标的操作融合,以及为计算分配运行时,内存的缓冲区分析。
在独立于目标的步骤之后,XLA将HLO计算发送到后端。后端可以执行进一步的HLO级别分析和优化,针对具体目标信息和需求。例如,XLA GPU后端可以执行专用于GPU编程模型的算子融合,并确定如何将计算划分为流。这时,后端也可以模式匹配某些操作或其组合来优化库调用。
下一步是目标特定的代码生成。XLA附带的CPU和GPU后端使用 LLVM进行低级IR,优化和代码生成。这些后端以有效的方式,发出代表XLA HLO计算所需的LLVM IR,然后调用LLVM从此LLVM IR发出本机代码。
纠错
GPU后端当前通过LLVM NVPTX后端,支持NVIDIA GPU; CPU后端支持多个CPU ISA。
支持的平台
XLA目前支持x86-64和NVIDIA GPU上的JIT编译; 以及针对x86-64和ARM的AOT编译。XLA开发后端
XLA提供了一个抽象接口,新体系结构或加速器可以实现创建后端,运行TensorFlow图形。重新定位XLA,应该比实现每个现有的TensorFlow Op用于新硬件,更加简单和可扩展。
大多数实现将落入以下情况之一:
1. 现有的CPU体系结构,尚未正式由XLA支持,无论是否存在 LLVM后端。
2. 具有现有LLVM后端的非CPU类硬件。
3. 没有现有LLVM后端的非CPU类硬件。
注意: LLVM后端可以是官方发布的LLVM后端,或内部开发的定制LLVM后端。
在这种情况下,首先查看现有的 XLA CPU后端。通过使用LLVM,XLA可以轻松地将TensorFlow重定向到不同的CPU,因为XLA后端对于CPU的主要区别在于LLVM生成的代码。Google测试XLA for x64和ARM64体系结构。
如果硬件供应商为其硬件提供LLVM后端,则将后端与使用XLA构建的LLVM进行链接很简单。在JIT模式下,XLA CPU后端为主机CPU发出代码。对于提前编译, xla::AotCompilationOptions可以提供一个LLVM三元组来配置目标体系结构。
如果没有现有的LLVM后端,但存在另一种代码生成器,则应该可以重新使用大部分现有的CPU后端。
可以 xla::Compiler在现有类 xla::CPUCompiler和 xla::GPUCompiler类上建立一个新的实现,因为它们已经发出了LLVM IR。根据硬件的性质,许多LLVM IR生成方面可能需要更改,但可以与现有后端共享大量代码。
一个很好的例子就是XLA 的 GPU后端。GPU后端以非CPU类ISA为目标,代码生成的某些方面对于GPU域是唯一的。其它类型的硬件,例如Hexagon(具有上游LLVM后端)的DSP,可以重新使用部分LLVM IR发射逻辑,但其它部分将是唯一的。
如果无法使用LLVM,最好的选择是为XLA实现所需硬件的新后端。这个选项需要最多的努力。需要实施的类如下:
StreamExecutor:对于许多设备,并非所有的方法StreamExecutor都是必需的。详情请参阅现有的StreamExecutor实施。
xla :: Compiler:这个类将HLO计算的编译封装为一个xla::Executable。
xla::Executable:该类用于在平台上启动编译的计算。
xla::TransferManager:该类使后端能够提供特定于平台的机制,用于从给定的设备内存句柄构造XLA文字数据。换句话说,有助于封装从主机到设备的数据传输并返回。
TensorFlow必须从源代码编译为包含XLA。
TensorFlow / XLA JIT编译器,通过XLA编译和运行TensorFlow图形的一部分。与标准TensorFlow实现相比,这样做的好处是XLA可以将多个算子(内核融合),融合到少量的编译内核中。与TensorFlow执行程序一样,与一次执行算子相比,定位算子可以减少内存带宽要求并提高性能。
有两种方法通过XLA运行TensorFlow计算,或者通过JIT编译算子放置在CPU或GPU的设备上,或通过将算子在XLA_CPU或XLA_GPUTensorFlow设备。将算子直接放在TensorFlow XLA设备上强制算子在该设备上运行,主要用于测试。
Note: The XLA CPU backend produces fast single-threaded code (in most cases), but does not yet parallelize as well as the TensorFlow CPU backend. The XLA GPU backend is competitive with the standard TensorFlow implementation, sometimes faster, sometimes slower.
JIT编译可以在会话级别,打开或手动进行选择操作。这两种方法都是零拷贝---在编译的XLA内核和置于同一设备上的TensorFlow算子之间传递数据时,不需要复制数据。
在会话级别打开JIT编译,导致所有可能的算子,贪婪地编译成XLA计算。每个XLA计算,编译为一个或多个内核设备。
受限于一些限制,如果图中有两个相邻的算子,都具有XLA实现,编译为单个XLA计算。
JIT编译在会话级别打开,方法是在会话初始化期间,将config 设置global_jit_level为tf.OptimizerOptions.ON_1,传递配置。
# Config to turn on JIT compilation1.
config = tf.ConfigProto()1.
config.graph_options.optimizer_options.global_jit_level = tf.OptimizerOptions.ON_11.
sess = tf.Session(config=config)1.Note: Turning on JIT at the session level will not result in operations being compiled for the CPU. JIT compilation for CPU operations must be done via the manual method documented below. This decision was made due to the CPU backend being single-threaded.
JIT编译也可以为一个或多个算子手动打开。这是通过标记算子以使用属性进行编译完成的_XlaCompile=true。最简单的方法是通过在中tf.contrib.compiler.jit.experimental_jit_scope()定义的范围 tensorflow/contrib/compiler/jit.py。用法示例:
jit_scope = tf.contrib.compiler.jit.experimental_jit_scope1.
x = tf.placeholder(np.float32)1.
with jit_scope():1.
y = tf.add(x, x) # The "add" will be compiled with XLA.1.该_XlaCompile属性目前支持尽力而为。如果无法编译算子, TensorFlow将默默回退到正常实现。
通过XLA运行计算的另一种方法,将算子放置在特定的XLA设备上。通常仅用于测试。有效目标是XLA_CPU或XLA_GPU。
with tf.device("/job:localhost/replica:0/task:0/device:XLA_GPU:0"):1.
output = tf.add(input1, input2)1.与标准CPU和GPU设备上的JIT编译不同,这些设备在将数据传输到设备上,或从设备传输时将复制数据。额外的副本使XLA和TensorFlow算子,在同一个图中混合成本很高。
如何在开启JIT的情况下,训练MNIST softmax。当前在会话级别的JIT,仅支持GPU。
验证LD_LIBRARY环境变量或ldconfig,包含$CUDA_ROOT/extras/CUPTI/lib64,其中包含CUDA分析工具界面 (CUPTI)的库。TensorFlow使用CUPTI从GPU中,提取跟踪信息。
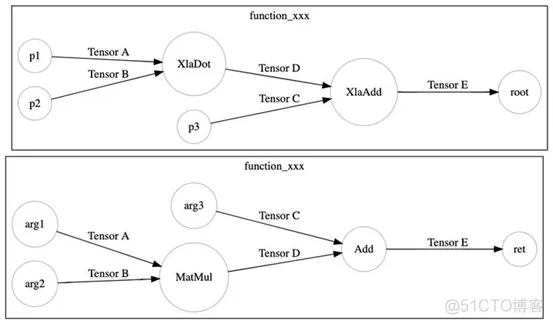
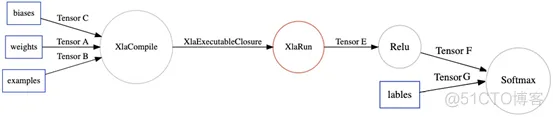
先来看XLA如何作用于TensorFlow的计算图,下面是一张简单的TensorFlow计算图。
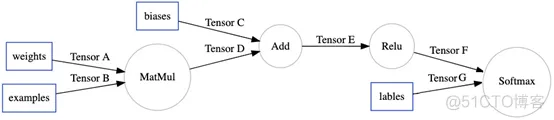
XLA通过一个TensorFlow的图优化Pass(MarkForCompilation),在TensorFlow计算图中,找到适合JIT编译的区域。假设XLA仅支持MatMul和Add。
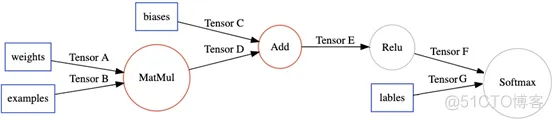
TensorFlow XLA把这个区域定义为一个Cluster,作为一个独立的JIT编译单元,在TensorFlow计算图中通过Node Attribute标示。
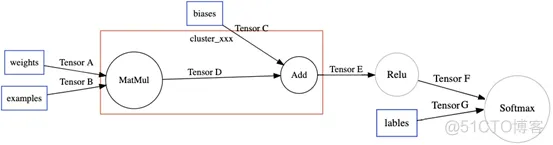
然后,另一个TensorFlow的图优化Pass(EncapsulateSubgraphs),把cluster转化成TensorFlow的一个Function子图。在原图上用一个Caller节点表示这个Function在原图的位置。
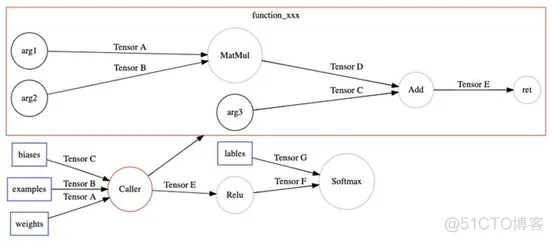
最后,调用TensorFlow的图优化Pass(BuildXlaOps),把Function节点转化成特殊的Xla节点。
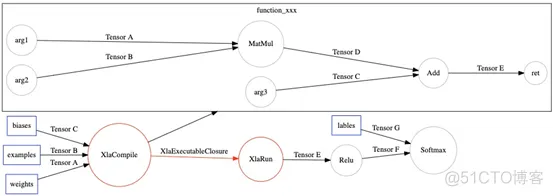
在TensorFlow运行时,运行到XlaCompile时,编译Xla cluster子图,然后把编译完的Executable可执行文件,通过XlaExecutableClosure传给XlaRun运行。
TensorFlow运行到XlaCompile节点时。
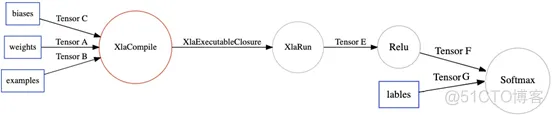
为了编译这个Function,通过把TensorFlow子图所有的节点,翻译成XLA HLO Instruction虚拟指令的形式表达,整个子图也由此转化成XLA HLO Computation。
XLA-HLO
XLA在HLO的图表达上进行图优化。聚合可在同一个GPU Kernel中执行的HLO指令。
HLO图优化前
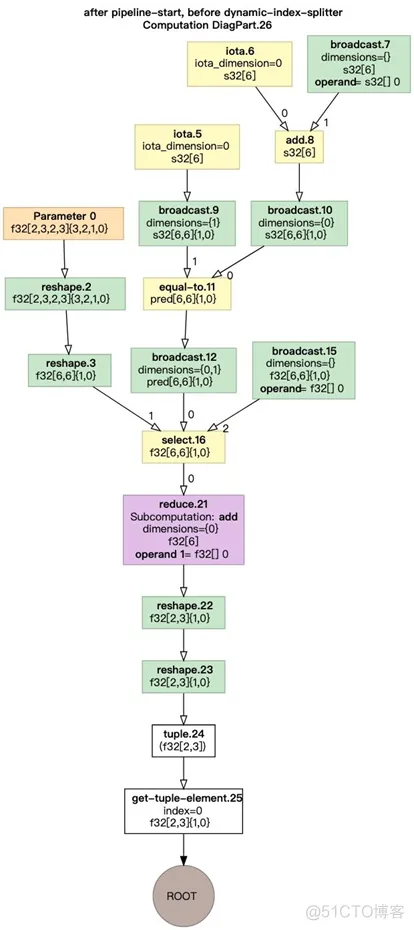
HLO图优化后
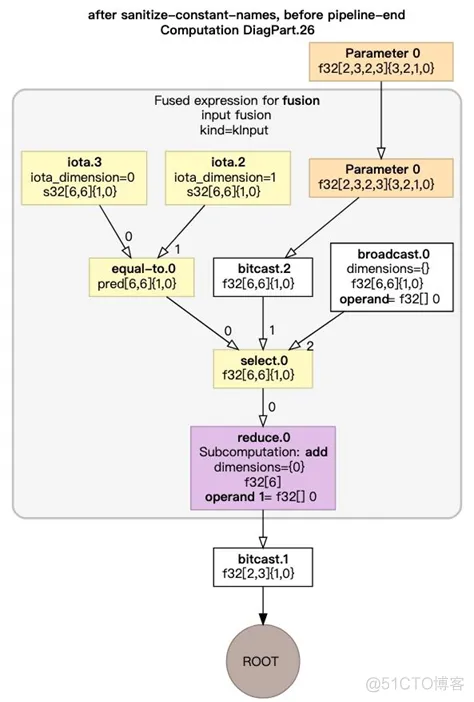
代码生成
首先根据虚拟指令分配GPU Stream和显存。
然后IrEmitter把HLO Graph转化成由编译器的中间表达LLVM IR表示的GPU Kernel。LLVM IR如下所示:
source_filename = "cluster_36__XlaCompiledKernel_true__XlaNumConstantArgs_1__XlaNumResourceArgs_0_.36"1.
target datalayout = "e-i64:64-i128:128-v16:16-v32:32-n16:32:64"1.
target triple = "nvptx64-nvidia-cuda"1.
@0 = private unnamed_addr constant [4 x i8] zeroinitializer1.
@1 = private unnamed_addr constant [4 x i8] zeroinitializer1.
@2 = private unnamed_addr constant [4 x i8] zeroinitializer1.
@3 = private unnamed_addr constant [4 x i8] zeroinitializer1.
@4 = private unnamed_addr constant [4 x i8] zeroinitializer1.
@5 = private unnamed_addr constant [4 x i8] zeroinitializer1.
@6 = private unnamed_addr constant [4 x i8] zeroinitializer1.
define void @fusion_1(i8* align 16 dereferenceable(3564544) %alloc2, i8* align 64 dereferenceable(3776) %temp_buf) {1.
entry:1.
%output.invar_address = alloca i641.
%output_y.invar_address = alloca i641.
%arg0.1.raw = getelementptr inbounds i8, i8* %alloc2, i64 01.
%arg0.1.typed = bitcast i8* %arg0.1.raw to [944 x [944 x float]]*1.
%fusion.1.raw = getelementptr inbounds i8, i8* %temp_buf, i64 01.
%fusion.1.typed = bitcast i8* %fusion.1.raw to [944 x float]*1.
%0 = call i32 @llvm.nvvm.read.ptx.sreg.tid.x(), !range !41.
%thread.id.x = sext i32 %0 to i641.
%thread.x = urem i64 %thread.id.x, 9441.
%thread.y = udiv i64 %thread.id.x, 9441.
%1 = alloca float1.
%partial_reduction_result.0 = alloca float1.
%2 = load float, float* bitcast ([4 x i8]* @0 to float*)1.
%3 = getelementptr inbounds float, float* %partial_reduction_result.0, i32 01.
store float %2, float* %31.
%current_output_linear_index_address = alloca i641.
%4 = alloca i11.
store i1 false, i1* %41.
%5 = call i32 @llvm.nvvm.read.ptx.sreg.ctaid.x(), !range !51.
%block.id.x = sext i32 %5 to i641.
%6 = udiv i64 %block.id.x, 11.
%7 = urem i64 %6, 11.
%8 = udiv i64 %block.id.x, 11.
%9 = urem i64 %8, 81.
%10 = udiv i64 %block.id.x, 81.
%block_origin.0 = mul i64 %10, 11.
%block_origin.1 = mul i64 %9, 11.
...1.
由LLVM生成nvPTX(Nvidia定义的虚拟底层指令表达形式)表达,进而由NVCC生成CuBin可执行代码。PTX如下所示:
.reg .f32 %f<25>;1.
.reg .b32 %r<31>;1.
.reg .b64 %rd<61>;1.
ld.param.u64 %rd27, [fusion_1_param_0];1.
ld.param.u64 %rd28, [fusion_1_param_1];1.
cvta.to.global.u64 %rd29, %rd28;1.
cvta.to.global.u64 %rd1, %rd27;1.
cvta.global.u64 %rd2, %rd29;1.
mov.u32 %r3, %tid.x;1.
cvt.u64.u32 %rd3, %r3;1.
mov.u32 %r1, %ctaid.x;1.
setp.eq.s32 %p1, %r1, 7;1.
@%p1 bra LBB0_4;1.
bra.uni LBB0_1;1.
LBB0_4:1.
selp.b64 %rd4, 48, 128, %p1;1.
cvt.u32.u64 %r26, %rd3;1.
shl.b64 %rd47, %rd3, 2;1.
add.s64 %rd48, %rd47, %rd1;1.
add.s64 %rd59, %rd48, 3383296;1.
or.b32 %r27, %r26, 845824;1.
mul.wide.u32 %rd49, %r27, 582368447;1.
shr.u64 %rd50, %rd49, 39;1.
cvt.u32.u64 %r28, %rd50;1.
mul.lo.s32 %r29, %r28, 945;1.
sub.s32 %r2, %r27, %r29;1.
mov.f32 %f23, 0f00000000;1.
...1.
当TensorFlow运行到XlaRun时,运行由XlaCompile编译得到的GPU可执行代码(Cubin或PTX)。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















